Major Crypto Relative Strength Portfolio System Majors RSPS - Relative Strength Portfolio System for Major Cryptocurrencies
Overview
Majors RSPS (Relative Strength Portfolio System) is an advanced portfolio allocation indicator that combines relative strength analysis, trend consensus, and macro risk factors to dynamically allocate capital across major cryptocurrency assets. The system leverages the NormalizedIndicators Library to evaluate both absolute trends and relative performance, creating an adaptive portfolio that automatically adjusts exposure based on market conditions.
This indicator is designed for portfolio managers, asset allocators, and systematic traders who want a data-driven approach to cryptocurrency portfolio construction with automatic rebalancing signals.
🎯 Core Concept
What is RSPS?
RSPS (Relative Strength Portfolio System) evaluates each asset on two key dimensions:
Relative Strength: How is the asset performing compared to other major cryptocurrencies?
Absolute Trend: Is the asset itself in a bullish trend?
Assets that show both strong relative performance AND positive absolute trends receive higher allocations. Weak performers are automatically filtered out, with capital reallocated to cash or stronger assets.
Dual-Layer Architecture
Layer 1: Majors Portfolio (Orange Zone)
Evaluates 14 major cryptocurrency assets
Calculates relative strength against all other majors
Applies trend filters to ensure absolute momentum
Dynamically allocates capital based on comparative strength
Layer 2: Cash/Risk Position (Navy Zone)
Evaluates macro risk factors and market conditions
Determines optimal cash allocation
Acts as a risk-off mechanism during adverse conditions
Provides downside protection through dynamic cash holdings
📊 Tracked Assets
Major Cryptocurrencies (14 Assets)
BTC - Bitcoin (Benchmark L1)
ETH - Ethereum (Smart Contract L1)
SOL - Solana (High-Performance L1)
SUI - Sui (Move-Based L1)
TRX - Tron (Payment-Focused L1)
BNB - Binance Coin (Exchange L1)
XRP - Ripple (Payment Network)
FTM - Fantom (DeFi L1)
CELO - Celo (Mobile-First L1)
TAO - Bittensor (AI Network)
HYPE - Hyperliquid (DeFi Exchange)
HBAR - Hedera (Enterprise L1)
ADA - Cardano (Research-Driven L1)
THETA - Theta (Video Network)
🔧 How It Works
Step 1: Relative Strength Calculation
For each asset, the system calculates relative strength by:
RSPS Score = Average of:
- Asset/BTC trend consensus
- Asset/ETH trend consensus
- Asset/SOL trend consensus
- Asset/SUI trend consensus
- ... (all 14 pairs)
- Asset's absolute trend consensus
Key Logic:
Each pair is evaluated using the eth_4d_cal() calibration from NormalizedIndicators
If an asset's absolute trend is extremely weak (≤ 0.1), it receives a penalty score (-0.5)
Otherwise, it gets the average of all its relative strength comparisons
Step 2: Trend Filtering
Assets must pass a trend filter to receive allocation:
Trend Score = Average of:
- Asset/BTC trend (filtered for positivity)
- Asset/ETH trend (filtered for positivity)
- Asset's absolute trend (filtered for positivity)
Only positive values contribute to the trend score, ensuring bearish assets don't receive allocation.
Step 3: Portfolio Allocation
Capital is allocated proportionally based on filtered RSPS scores:
Asset Allocation % = (Asset's Filtered RSPS Score / Sum of All Filtered Scores) × Main Portfolio %
Example:
SOL filtered score: 0.6
BTC filtered score: 0.4
All others: 0
Total: 1.0
SOL receives: (0.6 / 1.0) × Main% = 60% of main portfolio
BTC receives: (0.4 / 1.0) × Main% = 40% of main portfolio
Step 4: Cash/Risk Allocation
The system evaluates macro conditions across 6 factors:
Inverse Major Crypto Trends (40% weight)
When BTC, ETH, SOL, SUI, DOGE, etc. trend down → Cash allocation increases
Evaluates total market cap trends (TOTAL, TOTAL2, OTHERS)
Stablecoin Dominance (10% weight)
USDC dominance vs. major crypto dominances
Higher stablecoin dominance → Higher cash allocation
MVRV Ratios (10% weight)
BTC and ETH Market Value to Realized Value
High MVRV (overvaluation) → Higher cash allocation
BTC/ETH Ratio (15% weight)
Relative performance between two market leaders
Indicates market phase (BTC dominance vs. alt season)
Active Address Ratios (5% weight)
USDC active addresses vs. BTC/ETH active addresses
Network activity comparison
Macro Indicators (15% weight)
Global currency circulation (USD, EUR, CNY, JPY)
Treasury yield curve (10Y-2Y)
High yield spreads
Central bank balance sheets and money supply
Cash Allocation Formula:
Cash % = (Sum of Risk Factors × 0.5) / (Risk Factors + Majors TPI)
When risk factors are elevated, cash allocation increases, reducing exposure to volatile assets.
📈 Visual Components
Orange Zone (Majors Portfolio)
Fill: Light orange area showing aggregate portfolio strength
Line: Average trend power index (TPI) of allocated assets
Baseline: 0 level (neutral)
Interpretation:
Above 0: Bullish allocation environment
Rising: Strengthening portfolio momentum
Falling: Weakening portfolio momentum
Below 0: No allocation (100% cash)
Navy Zone (Cash Position)
Fill: Navy blue area showing cash allocation strength
Line: Risk-adjusted cash allocation signal
Baseline: 0 level
Interpretation:
Higher navy zone: Elevated risk-off signal → More cash
Lower navy zone: Risk-on environment → Less cash
Zero: No cash allocation (100% invested)
Performance Line (Orange/Blue)
Orange: Main portfolio allocation dominant (risk-on mode)
Blue: Cash allocation dominant (risk-off mode)
Tracks: Cumulative portfolio returns with dynamic rebalancing
Allocation Table (Bottom Left)
Shows real-time portfolio composition:
ColumnDescriptionAssetCryptocurrency nameRSPS ValuePercentage allocation (of main portfolio)CashDollar amount (if enabled)
Color Coding:
Orange: Active allocation
Gray: Weak signal (borderline)
Blue: Cash position
Missing: No allocation (filtered out)
⚙️ Settings & Configuration
Required Setup
Chart Symbol
MUST USE: INDEX:BTCUSD or similar major crypto index
Recommended Timeframe: 1D (Daily) or 4D (4-Day)
Why: System needs price data for all 14 majors, BTC provides stable reference
Hide Chart Candles
For clean visualization:
Right-click on chart
Select "Hide Symbol" or set candle opacity to 0
This allows the indicator fills and table to be clearly visible
User Inputs
plot_table (Default: true)
Enable/disable the allocation table
Set to false if you only want the visual zones
use_cash (Default: false)
Enable portfolio dollar value calculations
Shows actual dollar allocations per asset
cash (Default: 100)
Total portfolio size in dollars/currency units
Used when use_cash is enabled
Example: Set to 10000 for a $10,000 portfolio
💡 Interpretation Guide
Entry Signals
Strong Allocation Signal:
✓ Orange zone elevated (> 0.3)
✓ Navy zone low (< 0.2)
✓ Performance line orange
✓ Multiple assets in allocation table
→ Action: Deploy capital to allocated assets per table percentages
Risk-Off Signal:
✓ Orange zone near zero
✓ Navy zone elevated (> 0.4)
✓ Performance line blue
✓ Few or no assets in table (high cash %)
→ Action: Reduce exposure, increase cash holdings
Rebalancing Triggers
Monitor the allocation table for changes:
New assets appearing: Add to portfolio
Assets disappearing: Remove from portfolio
Percentage changes: Rebalance existing positions
Cash % changes: Adjust overall exposure
Market Regime Detection
Risk-On (Bull Market):
Orange zone high and rising
Navy zone minimal
Many assets allocated (8-12)
High individual allocations (15-30% each)
Risk-Off (Bear Market):
Orange zone near zero or negative
Navy zone elevated
Few assets allocated (0-3)
Cash allocation dominant (70-100%)
Transition Phase:
Both zones moderate
Medium number of assets (4-7)
Balanced cash/asset allocation (40-60%)
🎯 Trading Strategies
Strategy 1: Pure RSPS Following
1. Check allocation table daily
2. Rebalance portfolio to match percentages
3. Follow cash allocation strictly
4. Review weekly, act on significant changes (>5%)
Best For: Systematic portfolio managers, passive allocators
Strategy 2: Threshold-Based
Entry Rules:
- Orange zone > 0.4 AND Navy zone < 0.3
- At least 5 assets in allocation table
- Total non-cash allocation > 60%
Exit Rules:
- Orange zone < 0.1 OR Navy zone > 0.5
- Fewer than 3 assets allocated
- Cash allocation > 70%
Best For: Active traders wanting clear rules
Strategy 3: Relative Strength Overlay
1. Use RSPS for broad allocation framework
2. Within allocated assets, overweight top 3 performers
3. Scale position sizes by RSPS score
4. Use individual asset charts for entry/exit timing
Best For: Discretionary traders with portfolio focus
Strategy 4: Risk-Adjusted Position Sizing
For each allocated asset:
Position Size = Base Position × (Asset's RSPS Score / Max RSPS Score) × (1 - Cash Allocation)
Example:
- $10,000 portfolio
- SOL RSPS: 0.6 (highest)
- BTC RSPS: 0.4
- Cash allocation: 30%
SOL Size = $10,000 × (0.6/0.6) × (1-0.30) = $7,000
BTC Size = $10,000 × (0.4/0.6) × (1-0.30) = $4,667
Cash = $10,000 × 0.30 = $3,000
Best For: Risk-conscious allocators
📊 Advanced Usage
Multi-Timeframe Confirmation
Use on multiple timeframes for robust signals:
1D Chart: Tactical allocation (daily rebalancing)
4D Chart: Strategic allocation (weekly review)
Strong Confirmation:
- Both timeframes show same top 3 assets
- Both show similar cash allocation levels
- Orange zones aligned on both
Weak/Conflicting:
- Different top performers
- Diverging cash allocations
→ Wait for alignment or use shorter timeframe
Sector Rotation Analysis
Group assets by type and watch rotation:
L1 Dominance: BTC, ETH, SOL, SUI, ADA high → Layer 1 season
Alt L1s: TRX, FTM, CELO rising → Alternative platform season
Specialized: TAO, THETA, HYPE strong → Niche narrative season
Payment/Stable: XRP, BNB allocation → Risk reduction phase
Divergence Trading
Bullish Divergence:
Navy zone declining (less risk-off)
Orange zone flat or slightly rising
Few assets still allocated but strengthening
→ Early accumulation signal
Bearish Divergence:
Orange zone declining
Navy zone rising
Asset count decreasing in table
→ Distribution/exit signal
Performance Tracking
The performance line (overlay) shows cumulative strategy returns:
Compare to BTC/ETH: Is RSPS outperforming?
Drawdown analysis: How deep are pullbacks?
Correlation: Does it track market or provide diversification?
🔬 Technical Details
Data Sources
Price Data:
COINEX: Primary exchange for alt data
CRYPTO: Alternative price feeds
INDEX: Aggregated index prices (recommended for BTC)
Macro Data:
Dominance metrics (SUI.D, BTC.D, etc.)
MVRV ratios (on-chain valuation)
Active addresses (network activity)
Global money supply and macro indicators
Calculation Methodology
RSPS Scoring:
For each asset, calculate 14 relative trends (vs. all others)
Calculate asset's absolute trend
Average all 15 values
Apply penalty filter for extremely weak trends (≤ 0.1)
Trend Consensus:
Uses eth_4d_cal() from NormalizedIndicators library
Combines 8 normalized indicators per measurement
Returns value from -1 (bearish) to +1 (bullish)
Performance Calculation:
Daily Return = Σ(Asset ROC × Asset Allocation)
Cumulative Performance = Previous Perf × (1 + Daily Return / 100)
Assumes perfect rebalancing and no slippage (theoretical performance).
Filtering Logic
filter() function:
pinescriptfilter(input) => input >= 0 ? input : 0
This zero-floor filter ensures:
Only positive trend values contribute to allocation
Bearish assets receive 0 weight
No short positions or inverse allocations
Anti-Manipulation Safeguards
Null Handling:
All values wrapped in nz() to handle missing data
Prevents calculation errors from data gaps
Normalization:
Allocations always sum to 100%
Prevents over/under-allocation
Conditional Logic:
Assets need positive values on multiple metrics
Single metric cannot drive allocation alone
⚠️ Important Considerations
Required Timeframes
1D (Daily): Recommended for most users
4D (4-Day): More stable, fewer rebalances
Other timeframes: Use at your own discretion, may require recalibration
Data Requirements
Needs INDEX:BTCUSD or equivalent major crypto symbol
All 14 tracked assets must have available data
Macro indicators require specific TradingView data feeds
Rebalancing Frequency
System provides daily allocation updates
Practical rebalancing: Weekly or on significant changes (>10%)
Consider transaction costs and tax implications
Performance Notes
Theoretical returns: No slippage, fees, or execution delays
Backtest carefully: Validate on your specific market conditions
Past performance: Does not guarantee future results
Risk Warnings
⚠️ High Concentration Risk: May allocate heavily to 1-3 assets
⚠️ Volatility: Crypto markets are inherently volatile
⚠️ Liquidity: Some allocated assets may have lower liquidity
⚠️ Correlation: All assets correlated to BTC/ETH to some degree
⚠️ System Risk: Relies on continued availability of data feeds
Not Financial Advice
This indicator is a tool for analysis and research. It does not constitute:
Investment advice
Portfolio management services
Trading recommendations
Guaranteed returns
Always perform your own due diligence and risk assessment.
🎓 Use Cases
For Portfolio Managers
Systematic allocation framework
Objective rebalancing signals
Risk-adjusted exposure management
Performance tracking vs. benchmarks
For Active Traders
Identify strongest assets to focus trading on
Gauge overall market regime (risk-on/off)
Time entry/exit for portfolio shifts
Complement technical analysis with allocation data
For Institutional Allocators
Quantitative portfolio construction
Multi-asset exposure optimization
Drawdown management through cash allocation
Compliance-friendly systematic approach
For Researchers
Study relative strength dynamics in crypto markets
Analyze correlation between majors
Test macro factor impact on crypto allocations
Develop derived strategies and signals
🔧 Setup Checklist
✅ Chart Configuration
Set chart to INDEX:BTCUSD
Set timeframe to 1D or 4D
Hide chart candles for clean visualization
Add indicator from library
✅ Indicator Settings
Enable plot_table (see allocation table)
Set use_cash if tracking dollar amounts
Input your portfolio size in cash parameter
✅ Monitoring Setup
Bookmark chart for daily review
Set alerts for major allocation changes (optional)
Create spreadsheet to track allocations (optional)
Establish rebalancing schedule (weekly recommended)
✅ Validation
Verify all 14 assets appear in table (when allocated)
Check that percentages sum to ~100%
Confirm performance line is tracking
Test cash allocation calculation if enabled
📋 Quick Reference
Signal Interpretation
ConditionOrange ZoneNavy ZoneActionStrong BullHigh (>0.4)Low (<0.2)Full allocationModerate BullMid (0.2-0.4)Low-MidStandard allocationNeutralLow (0.1-0.2)Mid (0.3-0.4)Balanced allocationModerate BearVery Low (<0.1)Mid-HighReduce exposureStrong BearZero/NegativeHigh (>0.5)High cash/exit
Rebalancing Thresholds
Change TypeThresholdActionIndividual asset±5%Consider rebalanceIndividual asset±10%Strongly rebalanceCash allocation±10%Adjust exposureAsset entry/exitAnyAdd/remove position
Color Legend
Orange: Main portfolio strength/allocation
Navy: Cash/risk-off allocation
Blue text: Cash position in table
Orange text: Active asset allocation
Gray text: Weak/borderline allocation
White: Headers and labels
🚀 Getting Started
Beginner Path
Add indicator to INDEX:BTCUSD daily chart
Hide candles for clarity
Enable plot_table to see allocations
Check table daily, note top 3-5 assets
Start with small allocation, observe behavior
Gradually increase allocation as you gain confidence
Intermediate Path
Set up on both 1D and 4D charts
Enable use_cash with your portfolio size
Create tracking spreadsheet
Implement weekly rebalancing schedule
Monitor divergences between timeframes
Compare performance to buy-and-hold BTC
Advanced Path
Modify code to add/remove tracked assets
Adjust relative strength calculation methodology
Customize cash allocation factors and weights
Integrate with portfolio management platform
Develop algorithmic rebalancing system
Create alerts for specific allocation conditions
📖 Additional Resources
Related Indicators
NormalizedIndicators Library: Core calculation engine
Individual asset trend indicators for deeper analysis
Macro indicator dashboards for cash allocation factors
Complementary Analysis
On-chain metrics (MVRV, active addresses, etc.)
Order book liquidity for execution planning
Correlation matrices for diversification analysis
Volatility indicators for position sizing
Learning Materials
Study relative strength portfolio theory
Research tactical asset allocation strategies
Understand crypto market cycles and phases
Learn about risk management in volatile assets
🎯 Key Takeaways
✅ Systematic allocation across 14 major cryptocurrencies
✅ Dual-layer approach: Asset selection + Cash management
✅ Relative strength focused: Invests in comparatively strong assets
✅ Trend filtering: Only allocates to assets in positive trends
✅ Dynamic rebalancing: Automatically adjusts to market conditions
✅ Risk-managed: Increases cash during adverse conditions
✅ Transparent methodology: Clear calculation logic
✅ Practical visualization: Easy-to-read table and zones
✅ Performance tracking: See cumulative strategy returns
✅ Highly customizable: Adjust assets, weights, and factors
📋 License
This code is subject to the Mozilla Public License 2.0 at mozilla.org
Majors RSPS transforms complex multi-asset portfolio management into a systematic, data-driven process. By combining relative strength analysis with trend consensus and macro risk factors, it provides traders and portfolio managers with a robust framework for navigating cryptocurrency markets with discipline and objectivity.WiederholenClaude kann Fehler machen. Bitte überprüfen Sie die Antworten. Sonnet 4.5
Statistics


Mean Reversion Signals (v6.4) – VWAP ±SD use with "support and resistence levels with breaks {lux algo} " at 5m tf for better results

Price Drop CounterThe Price Drop Counter is a very basic statistical indicator.
See it as an analytical tool that tracks how many times an asset's price has dropped by a specified percentage from its recent peak within a defined date range.
The indicator monitors the highest price reached and counts each occurrence when the price falls by your chosen threshold, then resets its peak tracking point after each drop is registered.
Uses
Volatility Assessment: Measure how frequently significant price corrections occur during specific periods
Market Behavior Analysis: Compare drop frequency across different timeframes or market conditions
Risk Evaluation: Identify assets or periods with higher downside volatility
Historical Pattern Recognition: Study how often major pullbacks happened during bull or bear markets
Backtesting Support: Analyze how your strategy would perform based on the frequency of drawdowns
How to use it
Add the indicator to your TradingView chart
Configure the Percent Drop (%) to define your threshold (default: 10%). The indicator will count each time price falls by this percentage from the most recent high
IMPORTANT Set your Start Date and End Date to analyze a specific period of interest
The blue step-line plot shows the cumulative count of drops within your date range
Adjust the percentage threshold based on your analysis needs - use smaller values (2-5%) for more frequent signals or larger values (15-20%) for major corrections only
The counter resets its high-water mark after each qualifying drop, allowing it to track multiple sequential drops within the same period.

indicator CalibrationIndicator Calibration - Multi-Indicator Consensus System
Overview
Indicator Calibration is a powerful consensus-based trading indicator that leverages the MyIndicatorLibrary (NormalizedIndicators) to combine multiple trend-following indicators into a single, actionable signal. By averaging the normalized outputs of up to 8 different trend indicators, this tool provides traders with a clear consensus view of market direction, reducing noise and false signals inherent in single-indicator approaches.
The indicator outputs a value between -1 (strong bearish) and +1 (strong bullish), with 0 representing a neutral market state. This creates an intuitive, easy-to-read oscillator that synthesizes multiple analytical perspectives into one coherent signal.
🎯 Core Concept
Consensus Trading Philosophy
Rather than relying on a single indicator that may give conflicting or premature signals, Indicator Calibration employs a democratic voting system where multiple indicators contribute their normalized opinion:
Each enabled indicator votes: +1 (bullish), -1 (bearish), or 0 (neutral)
The votes are averaged to create a consensus signal
Strong consensus (closer to ±1) indicates high agreement among indicators
Weak consensus (closer to 0) indicates market indecision or transition
Key Benefits
Reduced False Signals: Multiple indicators must agree before strong signals appear
Noise Filtering: Individual indicator quirks are smoothed out by averaging
Customizable: Enable/disable indicators and adjust parameters to suit your trading style
Universal Application: Works across all timeframes and asset classes
Clear Visualization: Simple line oscillator with clear bull/bear zones
📊 Included Indicators
The system can utilize up to 8 normalized trend-following indicators from the library:
1. BBPct - Bollinger Bands Percent
Parameters: Length (default: 20), Factor (default: 2)
Type: Stationary oscillator
Strength: Mean reversion and volatility detection
2. NorosTrendRibbonEMA
Parameters: Length (default: 20)
Type: Non-stationary trend follower
Strength: Breakout detection with momentum confirmation
3. RSI - Relative Strength Index
Parameters: Length (default: 9), SMA Length (default: 4)
Type: Stationary momentum oscillator
Strength: Overbought/oversold with smoothing
4. Vidya - Variable Index Dynamic Average
Parameters: Length (default: 30), History Length (default: 9)
Type: Adaptive moving average
Strength: Volatility-adjusted trend following
5. HullSuite
Parameters: Length (default: 55), Multiplier (default: 1)
Type: Fast-response moving average
Strength: Low-lag trend identification
6. TrendContinuation
Parameters: MA Length 1 (default: 50), MA Length 2 (default: 25)
Type: Dual HMA system
Strength: Trend quality assessment with neutral states
7. LeonidasTrendFollowingSystem
Parameters: Short Length (default: 21), Key Length (default: 10)
Type: Dual EMA crossover
Strength: Simple, reliable trend tracking
8. TRAMA - Trend Regularity Adaptive Moving Average
Parameters: Length (default: 50)
Type: Adaptive trend follower
Strength: Adjusts to trend stability
⚙️ Input Parameters
Source Settings
Source: Choose your price input (default: close)
Can be modified to: open, high, low, close, hl2, hlc3, ohlc4, hlcc4
Indicator Selection
Each indicator can be enabled or disabled via checkboxes:
use_bbpct: Enable/disable Bollinger Bands Percent
use_noros: Enable/disable Noro's Trend Ribbon
use_rsi: Enable/disable RSI
use_vidya: Enable/disable VIDYA
use_hull: Enable/disable Hull Suite
use_trendcon: Enable/disable Trend Continuation
use_leonidas: Enable/disable Leonidas System
use_trama: Enable/disable TRAMA
Parameter Customization
Each indicator has its own parameter group where you can fine-tune:
val 1: Primary period/length parameter
val 2: Secondary parameter (multiplier, smoothing, etc.)
📈 Signal Interpretation
Output Line (Orange)
The main output oscillates between -1 and +1:
+1.0 to +0.5: Strong bullish consensus (all or most indicators agree on uptrend)
+0.5 to +0.2: Moderate bullish bias (bullish indicators outnumber bearish)
+0.2 to -0.2: Neutral zone (mixed signals or transition phase)
-0.2 to -0.5: Moderate bearish bias (bearish indicators outnumber bullish)
-0.5 to -1.0: Strong bearish consensus (all or most indicators agree on downtrend)
Reference Lines
Green line (+1): Maximum bullish consensus
Red line (-1): Maximum bearish consensus
Gray line (0): Neutral midpoint
💡 Trading Strategies
Strategy 1: Consensus Threshold Trading
Entry Rules:
- Long: Output crosses above +0.5 (strong bullish consensus)
- Short: Output crosses below -0.5 (strong bearish consensus)
Exit Rules:
- Exit Long: Output crosses below 0 (consensus lost)
- Exit Short: Output crosses above 0 (consensus lost)
Strategy 2: Zero-Line Crossover
Entry Rules:
- Long: Output crosses above 0 (bullish shift in consensus)
- Short: Output crosses below 0 (bearish shift in consensus)
Exit Rules:
- Exit on opposite crossover
Strategy 3: Divergence Trading
Look for divergences between:
- Price making higher highs while indicator makes lower highs (bearish divergence)
- Price making lower lows while indicator makes higher lows (bullish divergence)
Strategy 4: Extreme Reading Reversal
Entry Rules:
- Long: Output reaches -0.8 or below (extreme bearish consensus = potential reversal)
- Short: Output reaches +0.8 or above (extreme bullish consensus = potential reversal)
Use with caution - best combined with other reversal signals
🔧 Optimization Tips
For Trending Markets
Enable trend-following indicators: Noro's, VIDYA, Hull Suite, Leonidas
Use higher threshold levels (±0.6) to filter out minor retracements
Increase indicator periods for smoother signals
For Range-Bound Markets
Enable oscillators: BBPct, RSI
Use zero-line crossovers for entries
Decrease indicator periods for faster response
For Volatile Markets
Enable adaptive indicators: VIDYA, TRAMA
Use wider threshold levels to avoid whipsaws
Consider disabling fast indicators that may overreact
Custom Calibration Process
Start with all indicators enabled using default parameters
Backtest on your chosen timeframe and asset
Identify which indicators produce the most false signals
Disable or adjust parameters for problematic indicators
Test different threshold levels for entry/exit
Validate on out-of-sample data
📊 Visual Guide
Color Scheme
Orange Line: Main consensus output
Green Horizontal: Bullish extreme (+1)
Red Horizontal: Bearish extreme (-1)
Gray Horizontal: Neutral zone (0)
Reading the Chart
Line above 0: Net bullish sentiment
Line below 0: Net bearish sentiment
Line near extremes: Strong consensus
Line fluctuating near 0: Indecision or transition
Smooth line movement: Stable consensus
Erratic line movement: Conflicting signals
⚠️ Important Considerations
Lag Characteristics
This is a lagging indicator by design (consensus takes time to form)
Best used for trend confirmation rather than early entry
May miss the first portion of strong moves
Reduces false entries at the cost of delayed entries
Number of Active Indicators
More indicators = smoother but slower signals
Fewer indicators = faster but potentially noisier signals
Minimum recommended: 4 indicators for reliable consensus
Optimal: 6-8 indicators for balanced performance
Market Conditions
Best: Strong trending markets (up or down)
Good: Volatile markets with clear directional moves
Poor: Choppy, sideways markets with no clear trend
Worst: Low-volume, range-bound conditions
Complementary Tools
Consider combining with:
Volume analysis for confirmation
Support/resistance levels for entry/exit points
Market structure analysis (higher timeframe trends)
Risk management tools (ATR-based stops)
🎓 Example Use Cases
Swing Trading
Timeframe: Daily or 4H
Enable: All 8 indicators with default parameters
Entry: Consensus > +0.5 or < -0.5
Hold: Until consensus reverses to opposite extreme
Day Trading
Timeframe: 15m or 1H
Enable: Faster indicators (RSI, BBPct, Noro's, Hull Suite)
Entry: Zero-line crossover with volume confirmation
Exit: Opposite crossover or profit target
Position Trading
Timeframe: Weekly or Daily
Enable: Slower indicators (TRAMA, VIDYA, Trend Continuation)
Entry: Strong consensus (±0.7) with higher timeframe confirmation
Hold: Months until consensus weakens significantly
🔬 Technical Details
Calculation Method
1. Each enabled indicator calculates its normalized signal (-1, 0, or +1)
2. All active signals are stored in an array
3. Array.avg() computes the arithmetic mean
4. Result is plotted as a continuous line
Output Range
Theoretical: -1.0 to +1.0
Practical: Typically ranges between -0.8 to +0.8
Rare: All indicators perfectly aligned at ±1.0
Performance
Lightweight calculation (simple averaging)
No repainting (all indicators are non-repainting)
Compatible with all Pine Script features
Works on all TradingView plans
📋 License
This code is subject to the Mozilla Public License 2.0 at mozilla.org
🚀 Quick Start Guide
Add to Chart: Apply indicator to your chart
Choose Timeframe: Select appropriate timeframe for your trading style
Enable Indicators: Start with all 8 enabled
Observe Behavior: Watch how consensus forms during different market conditions
Calibrate: Adjust parameters and indicator selection based on observations
Backtest: Validate your settings on historical data
Trade: Apply with proper risk management
🎯 Key Takeaways
✅ Consensus beats individual indicators - Multiple perspectives reduce errors
✅ Customizable to your style - Enable/disable and tune to preference
✅ Simple interpretation - One line tells the story
✅ Works across markets - Stocks, crypto, forex, commodities
✅ Reduces emotional trading - Clear, objective signal generation
✅ Professional-grade - Built on proven technical analysis principles
Indicator Calibration transforms complex multi-indicator analysis into a single, actionable signal. By harnessing the collective wisdom of multiple proven trend-following systems, traders gain a powerful edge in identifying high-probability trade setups while filtering out market noise.

NEW PRICE ACTION ALGO (v2)Updated price action indicator for day trading QQQ,SPY & IWM on the 5-6min chart

D+P All-in-OneD+P=DARVAS+PIVOT
In this script i tried make small combo of multiple metrics.
Along with Darvas+Pivot we have EMA10,20&RSI d,w,m table. i fixed this table to middle right so that its easy to use while using phone.
There is floater table having Day Low& Previous Day Low-% differnce from current price
We have RS rating of O'Neil
Small table having MarketCap,Industry and sector.

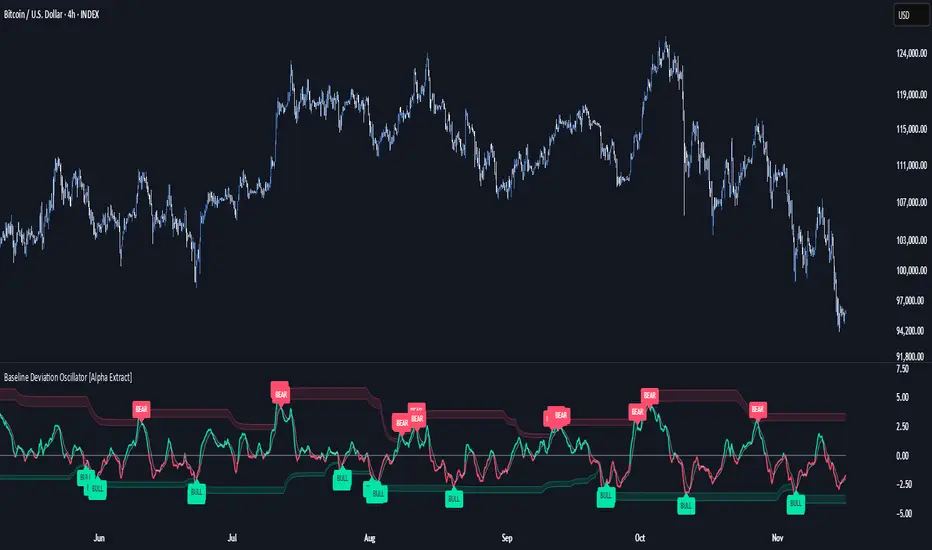
Baseline Deviation Oscillator [Alpha Extract]A sophisticated normalized oscillator system that measures price deviation from a customizable moving average baseline using ATR-based scaling and dynamic threshold adaptation. Utilizing advanced HL median filtering and multi-timeframe threshold calculations, this indicator delivers institutional-grade overbought/oversold detection with automatic zone adjustment based on recent oscillator extremes. The system's flexible baseline architecture supports six different moving average types while maintaining consistent ATR normalization for reliable signal generation across varying market volatility conditions.
🔶 Advanced Baseline Construction Framework
Implements flexible moving average architecture supporting EMA, RMA, SMA, WMA, HMA, and TEMA calculations with configurable source selection for optimal baseline customization. The system applies HL median filtering to the raw baseline for exceptional smoothing and outlier resistance, creating ultra-stable trend reference levels suitable for precise deviation measurement.
// Flexible Baseline MA System
ma(src, length, type) =>
if type == "EMA"
ta.ema(src, length)
else if type == "TEMA"
ema1 = ta.ema(src, length)
ema2 = ta.ema(ema1, length)
ema3 = ta.ema(ema2, length)
3 * ema1 - 3 * ema2 + ema3
// Baseline with HL Median Smoothing
Baseline_Raw = ma(src, MA_Length, MA_Type)
Baseline = hlMedian(Baseline_Raw, HL_Filter_Length)
🔶 ATR Normalization Engine
Features sophisticated ATR-based scaling methodology that normalizes price deviations relative to current volatility conditions, ensuring consistent oscillator readings across different market regimes. The system calculates ATR bands around the baseline and uses half the band width as the normalization factor for volatility-adjusted deviation measurement.
🔶 Dynamic Threshold Adaptation System
Implements intelligent threshold calculation using rolling window analysis of oscillator extremes with configurable smoothing and expansion parameters. The system identifies peak and trough levels over dynamic windows, applies EMA smoothing, and adds expansion factors to create adaptive overbought/oversold zones that adjust to changing market conditions.
1D
3D
1W
🔶 Multi-Source Configuration Architecture
Provides comprehensive source selection including Close, Open, HL2, HLC3, and OHLC4 options for baseline calculation, enabling traders to optimize oscillator behavior for specific trading styles. The flexible source system allows adaptation to different market characteristics while maintaining consistent ATR normalization methodology.
🔶 Signal Generation Framework
Generates bounce signals when oscillator crosses back through dynamic thresholds and zero-line crossover signals for trend confirmation. The system identifies both standard threshold bounces and extreme zone bounces with distinct alert conditions for comprehensive reversal and continuation pattern detection.
Bull_Bounce = ta.crossover(OSC, -Active_Lower) or
ta.crossover(OSC, -Active_Lower_Extreme)
Bear_Bounce = ta.crossunder(OSC, Active_Upper) or
ta.crossunder(OSC, Active_Upper_Extreme)
// Zero Line Signals
Zero_Cross_Up = ta.crossover(OSC, 0)
Zero_Cross_Down = ta.crossunder(OSC, 0)
🔶 Enhanced Visual Architecture
Provides color-coded oscillator line with bullish/bearish dynamic coloring, signal line overlay for trend confirmation, and optional cloud fills between oscillator and signal. The system includes gradient zone fills for overbought/oversold regions with configurable transparency and threshold level visualization with automatic label generation.
snapshot
🔶 HL Median Filter Integration
Features advanced high-low median filtering identical to DEMA Flow for exceptional baseline smoothing without lag introduction. The system constructs rolling windows of baseline values, performs median extraction for both odd and even window lengths, and eliminates outliers for ultra-clean deviation measurement baseline.
🔶 Comprehensive Alert System
Implements multi-tier alert framework covering bullish bounces from oversold zones, bearish bounces from overbought zones, and zero-line crossovers in both directions. The system provides real-time notifications for critical oscillator events with customizable message templates for automated trading integration.
🔶 Performance Optimization Framework
Utilizes efficient calculation methods with optimized array management for median filtering and minimal computational overhead for real-time oscillator updates. The system includes intelligent null value handling and automatic scale factor protection to prevent division errors during extreme market conditions.
🔶 Why Choose Baseline Deviation Oscillator ?
This indicator delivers sophisticated normalized oscillator analysis through flexible baseline architecture and dynamic threshold adaptation. Unlike traditional oscillators with fixed levels, the BDO automatically adjusts overbought/oversold zones based on recent oscillator behavior while maintaining consistent ATR normalization for reliable cross-market and cross-timeframe comparison. The system's combination of multiple MA type support, HL median filtering, and intelligent zone expansion makes it essential for traders seeking adaptive momentum analysis with reduced false signals and comprehensive reversal detection across cryptocurrency, forex, and equity markets.
Earnings Move Radar (E+1 & E+2)Stop guessing earnings reactions. See them. Count them. Use them.
Earnings Move Radar turns every earnings release into a clear visual story on your chart.
What it does for you
Automatically marks the first and second trading day after each earnings (E+1 & E+2).
Shows at a glance whether the move came from a gap, an intraday trend, or a follow-through / reversal on the next day.
Packs all past earnings into a compact stats panel so you instantly know:
how big earnings moves usually are,
how often they close up vs. down,
how common your “big move” threshold really is.
Highlights simple, practical patterns like “two-day runs” and “three-day runs” around earnings that many traders care about but rarely measure.
Why traders like it
Saves time: no more clicking through old earnings dates one by one.
Puts realistic numbers behind your option ideas and post-earnings plays.
Works on any stock or ETF with earnings data, with a customizable look-back window.
All labels and the stats table are shown in Chinese, making it very friendly for Chinese-speaking traders.
How to use
Apply it to a daily chart of the stock or ETF you trade.
Scan the labels to understand how the market usually reacts to earnings for this symbol.
Use the stats panel to size your risk and define what “normal”, “large” and “extreme” earnings moves mean for you.
This indicator is an analytical tool, not a signal generator. It does not provide financial advice.

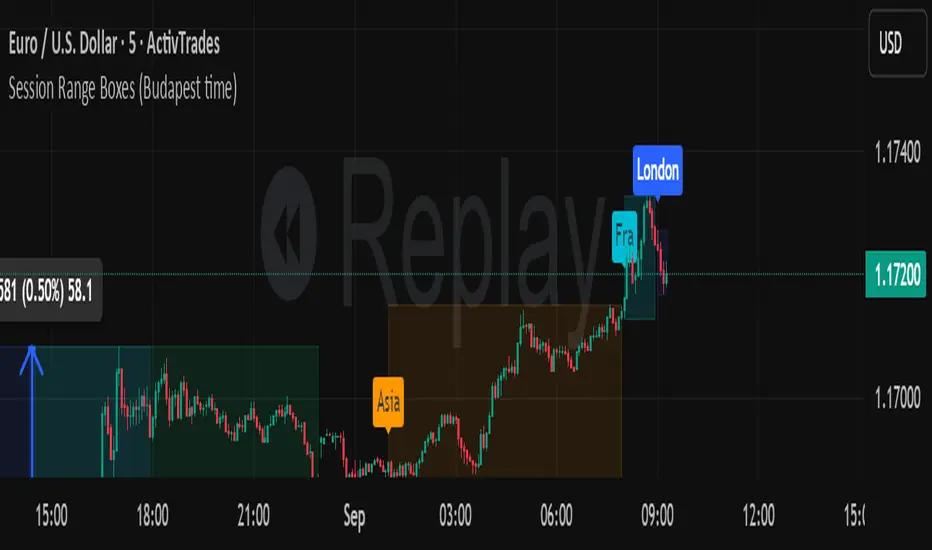
Session Range Boxes (Budapest time) GR V2.0Session Range Boxes (Budapest time)
This indicator draws intraday range boxes for the main Forex sessions based on Europe/Budapest time (CET/CEST).
Tracked sessions (Budapest time):
Asia: 01:00 – 08:00
Frankfurt (pre-London): 08:00 – 09:00
London: 09:00 – 18:00
New York: 14:30 – 23:00
For each session, the script:
Detects the session start and session end using the current chart timeframe and the Europe/Budapest time zone.
Tracks the high and low of price during the entire session.
Draws a box (rectangle) from session open to session close, covering the full price range between session high and low.
Optionally prints a small label above the first bar of each session (Asia, Fra, London, NY).
Color scheme:
Asia: soft orange box
Frankfurt: light aqua box
London: darker blue box
New York: light lime box
Use this tool to:
Quickly see which session created the high/low of the day,
Identify liquidity zones and session ranges that price may revisit,
Visually separate Asia, Frankfurt, London and New York volatility on intraday charts.
Optimized for intraday trading (Forex / indices), but it works on any symbol where session behavior matters.
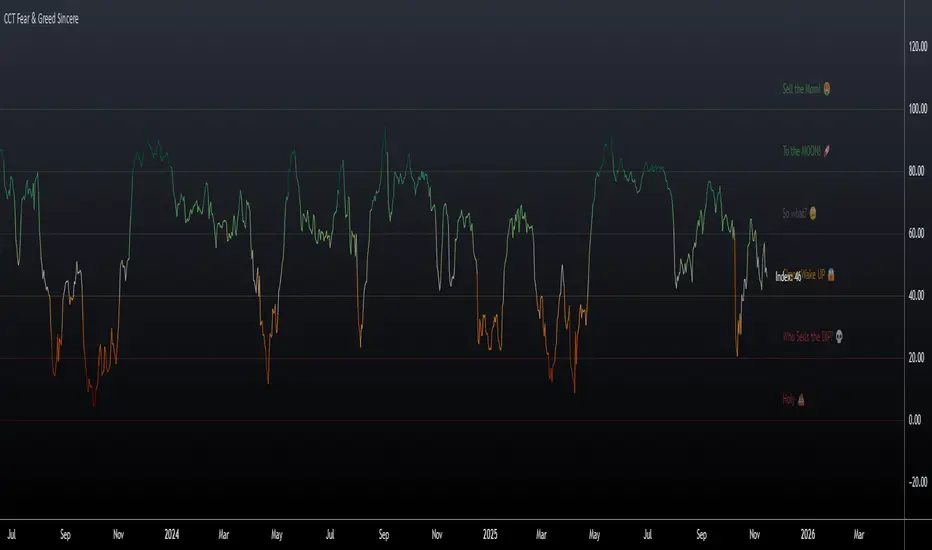
CCT Fear & Greed Sincere📄 CCT Fear & Greed Sincere — Technical Overview
The CCT Fear & Greed Sincere indicator provides a consolidated view of macro-market conditions using exclusively price-derived and market-structure data. The goal is to translate multiple independent risk-appetite components into a unified 0–100 index. This tool does not rely on survey sentiment, alternative datasets, or social indicators; it uses only verifiable, market-observable inputs.
All components are normalized into a comparable scale and combined into a composite metric representing broad risk-seeking or risk-averse behaviour in global markets. While applicable to any instrument on TradingView, the indicator is particularly effective for cryptocurrency markets due to their historical sensitivity to equity volatility, liquidity cycles, and macroeconomic shifts.
📊 Components Included in the Index
Below is an overview of the internal factors used to compute the final score. Each item is independently transformed into a 0–100 range before aggregation.
1. S&P 500 Price Deviation (SPX 125-Day Distance)
Measures how far the S&P 500 is trading above or below its 125-day moving average.
Large positive deviations generally reflect elevated risk-taking, while negative deviations suggest conservative market posture.
2. 52-Week Range Position (NYSE Composite)
Evaluates the NYSE Composite’s distance from its annual high/low range.
A higher relative position indicates greater market confidence, whereas lower values capture prolonged weakness or systemic stress.
3. Advance/Decline Momentum (ADVN vs. DECN)
Applies smoothing to the net difference between advancing and declining issues.
This highlights internal market participation, breadth conditions, and the balance between accumulation and distribution phases.
4. Put/Call Ratio Pressure (PCC)
Uses a smoothed version of the equity put/call ratio.
A higher put/call ratio (inverted here) reflects risk aversion, while lower ratios align with speculative environments.
5. VIX Relative Position (VIX vs. 50-Day Average)
Compares the current VIX value to its 50-day moving average.
VIX above its mean implies elevated volatility and fear; values below suggest calmer conditions and stronger risk appetite.
6. Equity vs. Treasury Performance (SPX vs. US10Y)
Contrasts 20-day returns of equities and U.S. 10-year bonds.
Strong equity performance relative to treasuries is normally associated with risk-on flows, while the opposite reflects defensive positioning.
7. High-Yield Spread (JNK vs. US10Y)
Tracks the yield differential between high-yield bonds and U.S. Treasury rates.
A wider spread captures stress in credit markets; a narrower spread indicates improved confidence.
🧮 Composite Calculation
The indicator computes each component independently, normalizes the values into a 0–100 scale using a consistent methodology, and then calculates the simple average.
This ensures transparency and avoids hidden weighting schemes or model bias.
The final index is plotted as a continuous line with adaptive coloring based on its current level, visually highlighting shifts between fear-dominant and greed-dominant market states.
📈 Suggested Usage
The indicator can be applied to any tradable asset, but it tends to be especially informative for:
Cryptocurrencies, due to their pronounced reaction to global liquidity and risk sentiment.
High-beta stocks, which often mirror broader volatility cycles.
Macro-focused analysis, where risk-on/risk-off transitions impact multiple asset classes simultaneously.
This tool is intended as a contextual framework rather than a standalone signal generator. Market participants may use it to contextualize regime changes, identify extremes, or complement existing technical strategies.
📏 Fear & Greed Levels Included in the Indicator
These levels are plotted with dedicated labels and tooltips to offer additional visual clarity:
Level Interpretation
0 – “Holy 💩” Extreme market stress; structural capitulation environment.
20 – “Who Sells the DIP?” Strong fear signal; frequently aligns with oversold conditions.
40 – “C’mon Wake UP!” Cautious or bearish environment; transitional zone.
60 – “So What?” Neutral risk environment; consolidation or equilibrium.
80 – “To the MOON!” Elevated risk appetite; momentum-driven phases.
100 – “Sell the MOM!” Peak optimism; historically associated with overheated conditions.
These thresholds do not provide direct buy/sell instructions; they are reference bands designed to help illustrate the structural context of market behavior.
📌 Why This Indicator Is Uniquely Updated
Uses 7 fully technical components
Zero survey sentiment
Zero social media data
Zero alternative datasets or search trend metrics
Fully transparent, fully reproducible, and based only on market-derived inputs
Built on Pine Script® v6, aligned with modern TradingView standards
Does not rely on proprietary or black-box scoring systems
This positions the CCT Fear & Greed Sincere as one of the most technically grounded and transparent fear/greed-style indicators available using only TradingView-native data.
Michael's Custom Watermark🔷 MICHAEL'S CUSTOM WATERMARK INDICATOR
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
📊 OVERVIEW
A comprehensive chart watermark overlay that displays essential fundamental and technical information for stocks in a clean, customizable table format. Perfect for traders who want quick access to key metrics without cluttering their charts.
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
✨ KEY FEATURES
📊 Fundamental Data Display — Shows Industry, Sector, Market Cap, and P/E Ratio
📅 Earnings Information — Displays next earnings date with countdown timer
📈 ATR Volatility Indicator — 14-day ATR with color-coded visual alerts (🔴🟡🟢)
🎨 Auto Theme Detection — Automatically adjusts text color based on chart background
⚙️ Fully Customizable — Position, colors, size, and displayed metrics all adjustable
🏢 GICS Sector Mapping — Heuristic-based sector classification aligned with industry standards
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
🎯 WHAT MAKES THIS INDICATOR UNIQUE?
Unlike basic watermarks, this indicator provides:
Real-time fundamental data integration
Smart theme-aware color adaptation for both light and dark charts
Configurable volatility alerts using ATR thresholds
Earnings countdown feature to never miss important dates
Optimized display that only shows relevant data for the current symbol type
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
📖 HOW TO USE
1. BASIC SETUP
Add the indicator to your chart. By default, it displays in the top-left corner with all features enabled.
2. POSITIONING
Vertical Location: Top, Middle, or Bottom
Horizontal Location: Left, Center, or Right
Vertical Offset: Fine-tune position with 0-50 pixel offset from top
3. CUSTOMIZATION OPTIONS
TEXT APPEARANCE:
Auto Text Color — Enable to automatically adapt text color to your chart theme
Manual Color — Set a fixed text color if auto-color is disabled
Text Size — Choose from Huge, Large, Normal, or Small
Theme Colors — Customize text color for light and dark backgrounds separately
DATA DISPLAY TOGGLES:
Show Industry & Sector — Display heuristic-based GICS-aligned sector and industry classification
Show Market Cap — View market capitalization in T/B/M format
Show P/E Ratio — Display Price-to-Earnings ratio (stocks only)
Show ATR (14-Day) — Display Average True Range with percentage and visual indicator
Show Next Earnings — Display upcoming earnings information
Show Earnings Countdown — Show days remaining until next earnings (requires earnings display)
4. ATR VOLATILITY ALERTS
Configure custom thresholds to monitor volatility:
Red Threshold — ATR percentage that triggers red alert 🔴 (default: 6%)
Yellow Threshold — ATR percentage that triggers yellow alert 🟡 (default: 3%)
Green — Shows automatically when ATR is below yellow threshold 🟢
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
📐 UNDERSTANDING THE DISPLAY
🏢 SECTOR & INDUSTRY
Shows the GICS sector classification followed by the specific industry. The indicator uses heuristic-based mapping to align TradingView sectors with standard GICS classifications. Note that this mapping is based on keyword detection and industry analysis, so while generally accurate, it may not perfectly match official GICS classifications in all cases.
💰 MARKET CAP
Displays market capitalization using standard abbreviations:
T = Trillion
B = Billion
M = Million
📊 P/E RATIO
Shows the trailing twelve-month Price-to-Earnings ratio. Only displayed for stocks when enabled. Shows "N/A" if data is unavailable.
📈 ATR (14-DAY)
Displays the 14-period Average True Range in both absolute value and percentage terms, with a color-coded indicator:
🔴 Red: High volatility (above red threshold)
🟡 Yellow: Moderate volatility (between yellow and red thresholds)
🟢 Green: Low volatility (below yellow threshold)
📅 EARNINGS
Shows earnings information in three formats:
"X days remaining" — When countdown is enabled and earnings date is known
"Upcoming" — When date is in the future but countdown is disabled
"Recently Reported" — When earnings just occurred
"N/A" — When no earnings data is available
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
⚙️ TECHNICAL DETAILS
SUPPORTED INSTRUMENTS:
Optimized for stocks with full fundamental data
Works with other instruments (crypto, forex, futures) but only displays applicable metrics
Automatically suppresses irrelevant data (e.g., P/E for non-stocks)
PERFORMANCE:
Lightweight overlay with minimal resource usage
Updates only on last bar for efficiency
No historical recalculation needed
COMPATIBILITY:
Pine Script v6
Works on all timeframes
Compatible with all chart types
Auto-adapts to theme changes
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
💡 TIPS & BEST PRACTICES
Enable Auto Text Color for seamless theme switching between light and dark modes
Adjust vertical offset to avoid overlap with price action in high-volatility periods
Use ATR thresholds appropriate to your trading style and asset class
Disable features you don't use to keep the watermark clean and focused
Position in corners to maximize chart viewing space
Use smaller text size for multi-panel layouts
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
🔧 TROUBLESHOOTING
"N/A" SHOWING FOR P/E RATIO:
This is normal for non-stock instruments
May occur for stocks with negative earnings
Check if fundamental data is available for the symbol
EARNINGS SHOWING "N/A":
Earnings data may not be available for all stocks
Check TradingView's data coverage for your symbol
TEXT COLOR NOT VISIBLE:
Enable Auto Text Color feature
Manually set text color to contrast with your chart background
Adjust custom light/dark text colors in settings
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
⚠️ DISCLAIMER
This indicator is for informational purposes only. The fundamental data displayed is sourced from TradingView's data providers. Always verify critical information before making trading decisions. Past performance is not indicative of future results.
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
If you find this indicator helpful, please give it a boost 🚀 and share your feedback in the comments!
Version: 1.0
Pine Script Version: v6
Created by: Michael
Psychological Levels (Zones + Alerts) - StableThis technical indicator plot support and resistance levels based on the psychological numbers
MTF Candle Countdown — HUD V1 (By Price-Action-Art)
MTF Candle Countdown — HUD V1 (By Price-Action-Art)
A clean, lightweight HUD that shows you exactly how much time is left in multiple higher-timeframe candles — all in one place.
This tool is designed for traders who rely on multi-timeframe precision.
Instead of constantly switching charts or checking timers, the HUD gives you a real-time countdown for up to six timeframes (Daily, 4H, 1H, 30m, 15m, 5m by default).
You can fully customize the timeframes, text size, and HUD position on your chart.
Perfect for:
Intraday and scalping timing
Swing traders waiting for HTF candle closes
ICT / SMC structure-based traders
Anyone who needs exact candle close timing without distractions
Features:
Real-time multi-timeframe candle countdown
Fully adjustable HUD placement (all corners)
Customizable timeframes and text size
Clean, minimal, and non-intrusive design
Updates only on the last bar for performance efficiency
Optional border for a sharper HUD look
Whether you’re waiting for a Daily close to confirm structure or timing your entries around 5m/15m candles, this HUD keeps everything visible and precise at a glance.
If you find this tool helpful, feel free to like, comment, and follow — it motivates me to keep releasing more tools for the community.
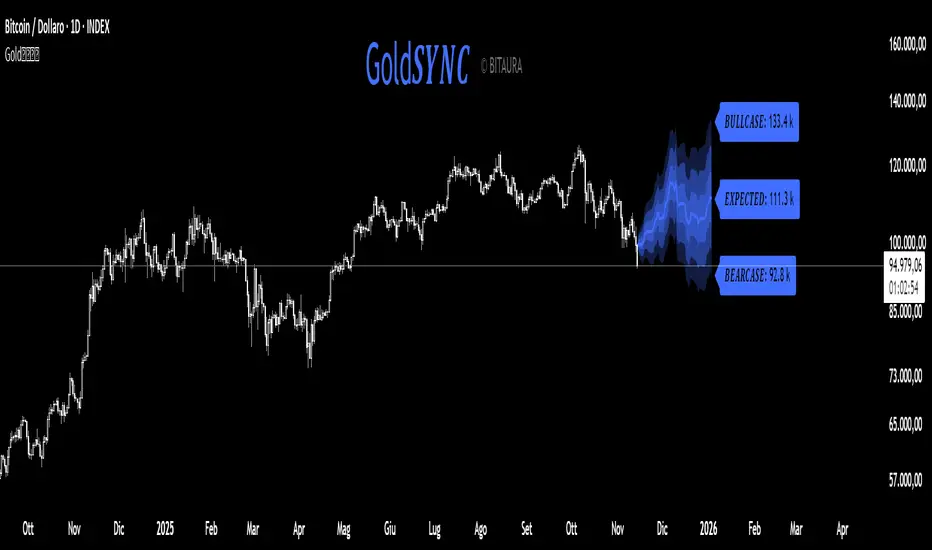
Gold𝑺𝒀𝑵𝑪🟡 Gold𝑺𝒀𝑵𝑪 - BTC follows GOLD
Gold𝑺𝒀𝑵𝑪 is a quantitative projection tool that visualizes how Bitcoin (BTC/USD) would perform if it mirrored the recent price behavior of Gold (XAU/USD).
It extends Gold’s last n days of normalized performance forward on the BTC chart and builds a volatility-adjusted projection corridor.
⚙️ Core Mechanics
Projection Engine:
Calculates Gold’s relative performance over the selected lookback window and applies it to BTC’s last closing price.
Volatility Scaling:
Computes the rolling standard deviation of Gold’s logarithmic returns to estimate the potential deviation range.
Dynamic Gradient Bands:
Three upper and lower standard deviation layers (1σ, 2σ, 3σ) are drawn using fading gradient fills to visualize increasing uncertainty.
Scenario Labels:
Displays key levels for:
𝑩𝑼𝑳𝑳𝑪𝑨𝑺𝑬 — +2σ projection
𝑬𝑿𝑷𝑬𝑪𝑻𝑬𝑫 — mean projection
𝑩𝑬𝑨𝑹𝑪𝑨𝑺𝑬 — −2σ projection
📈 Usage
Designed for 1D charts (daily timeframe).
Provides a comparative “sync” between Gold and Bitcoin to study cross-asset momentum, volatility symmetry, and directional bias.
Useful in macro correlation analysis or when modeling BTC’s potential movement under Gold-like conditions.
🧠 Interpretation
Gold𝑺𝒀𝑵𝑪 doesn’t predict - it synchronizes.
It offers a contextual view of BTC’s potential path if it followed Gold’s rhythm, enhanced by statistically derived volatility zones.
Created by: @SP_Quant
Credits: BitAura
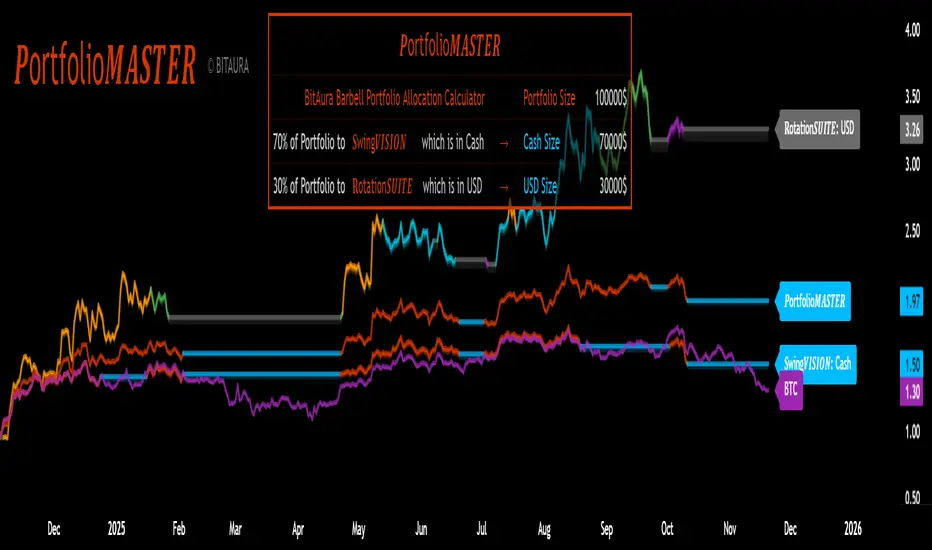
𝑷ortfolio𝑴𝑨𝑺𝑻𝑬𝑹 [BitAura]𝑷ortfolio𝑴𝑨𝑺𝑻𝑬𝑹
This Pine Script® indicator is meant to be used to manage a Barbell Portfolio composed of BitAura's various strategies in order to create a risk-reward balance for the investor's needs. The Portfolio is divided in two main parts, one being a lower-risk Bitcoin-only strategy while the other being the higher-risk, higher-reward 𝐑otation𝑺𝑼𝑰𝑻𝑬 V3 system. The user can choose the percentage splits between these two systems and then also configure them based on their risk profile.
Logic and Core Concepts
The 𝑷ortfolio𝑴𝑨𝑺𝑻𝑬𝑹 System uses the Barbell Portfolio theory to create a portfolio taylored for the final user and automatically calculates dollar allocation based on inputted settings.
Features
𝐑otation𝑺𝑼𝑰𝑻𝑬 : our advanced Strategy which allocates to the strongest asset amongst a pool of 4 Major Crypto Tokens, or de-risk to USD when these lack momentum.
BItcoin-only Strategy : This is theoretically a lower-risk system compared to 𝐑otation𝑺𝑼𝑰𝑻𝑬 and is made out of Universal Trend Following strategies. There are two variants, one being a Long-Term strategy (𝐂ycle𝑽𝑰𝑺𝑰𝑶𝑵) while the other one being of Medium-Term speed (𝐒wing𝑽𝑰𝑺𝑰𝑶𝑵).
Customizable Inputs : Allows users to adjust table settings, backtest date ranges, portfolio splits and portfolio dollar allocations.
Visual Outputs :
Allocation Table : Displays calculated allocation to each system based on user settings.
Equity Plots : Plots the Barbell Portfolio performance along with the two individual systems equities and allow comparisons between them and to Bitcoin Buy & Hold.
Color Presets : Offers five color themes (e.g., Arctic Blast, Fire vs. Ice) or custom color options for long/cash signals.
Pine Script v6 : Leverages matrices, tables, and gradient coloring for enhanced usability.
How to Use
Add to Chart : Apply the indicator to any chart on the 1D timeframe. The ticker doesn't matter as it doesn't affect the calculations, just make sure the ticker start date is earlier than the Backtest Start date applied in the script settings.
Input Portfolio size : Adjust the Dollar Portfolio size in the script settings in order to obtain accurate Portfolio Allocations in the respective table. Note that BitAura can't and won't be able to access your portfolio size.
Choose Barbell Split : Adjust based on your risk-profile how much to allocate to your preferred Bitcoin Strategy (default 70%) and how much to allocate to 𝐑otation𝑺𝑼𝑰𝑻𝑬 (default 30%).
Configure Systems : Select your preferred allocation type for 𝐑otation𝑺𝑼𝑰𝑻𝑬. Aggressive allocates 100% to the dominant asset, Moderate allocates 80% to the dominant asset and 20% to the second strongest one while Conservative does a 60/40 split between the first two assets.
Configure Settings : Adjust backtest start date (default: 31 Oct 2024) to properly track the Portfolio's performance.
Select Color Theme : Choose a preset color mode (e.g., Arctic Blast) or enable custom colors in the Colors group.
Monitor Outputs : Check the Table for Allocations and system signals, and view the equity curves to view the portfolio's performance.
Notes
The script is closed-source.
The script avoids lookahead bias by using barmerge.lookahead_off in request.security() calls.
The BitAura watermark can be toggled in the Script Settings .
Disclaimer : This script is for educational and analytical purposes only and does not constitute financial advice. Investing involves significant risk, and past performance is not indicative of future results. Always conduct your own research and apply proper risk management.
Reversal Point Dynamics - Machine Learning⇋ Reversal Point Dynamics - Machine Learning
RPD Machine Learning: Self-Adaptive Multi-Armed Bandit Trading System
RPD Machine Learning is an advanced algorithmic trading system that implements genuine machine learning through contextual multi-armed bandits, reinforcement learning, and online adaptation. Unlike traditional indicators that use fixed rules, RPD learns from every trade outcome , automatically discovers which strategies work in current market conditions, and continuously adapts without manual intervention .
Core Innovation: The system deploys six distinct trading policies (ranging from aggressive trend-following to conservative range-bound strategies) and uses LinUCB contextual bandit algorithms with Random Fourier Features to learn which policy performs best in each market regime. After the initial learning phase (50-100 trades), the system achieves autonomous adaptation , automatically shifting between policies as market conditions evolve.
Target Users: Quantitative traders, algorithmic trading developers, systematic traders, and data-driven investors who want a system that adapts over time . Suitable for stocks, futures, forex, and cryptocurrency on any liquid instrument with >100k daily volume.
The Problem This System Solves
Traditional Technical Analysis Limitations
Most trading systems suffer from three fundamental challenges :
Fixed Parameters: Static settings (like "buy when RSI < 30") work well in backtests but may struggle when markets change character. What worked in low-volatility environments may not work in high-volatility regimes.
Strategy Degradation: Manual optimization (curve-fitting) produces systems that perform well on historical data but may underperform in live trading. The system never adapts to new market conditions.
Cognitive Overload: Running multiple strategies simultaneously forces traders to manually decide which one to trust. This leads to hesitation, late entries, and inconsistent execution.
How RPD Machine Learning Addresses These Challenges
Automated Strategy Selection: Instead of requiring you to choose between trend-following and mean-reversion strategies, RPD runs all six policies simultaneously and uses machine learning to automatically select the best one for current conditions. The decision happens algorithmically, removing human hesitation.
Continuous Learning: After every trade, the system updates its understanding of which policies are working. If the market shifts from trending to ranging, RPD automatically detects this through changing performance patterns and adjusts selection accordingly.
Context-Aware Decisions: Unlike simple voting systems that treat all conditions equally, RPD analyzes market context (ADX regime, entropy levels, volatility state, volume patterns, time of day, historical performance) and learns which combinations of context features correlate with policy success.
Machine Learning Architecture: What Makes This "Real" ML
Component 1: Contextual Multi-Armed Bandits (LinUCB)
What Is a Multi-Armed Bandit Problem?
Imagine facing six slot machines, each with unknown payout rates. The exploration-exploitation dilemma asks: Should you keep pulling the machine that's worked well (exploitation) or try others that might be better (exploration)? RPD solves this for trading policies.
Academic Foundation:
RPD implements Linear Upper Confidence Bound (LinUCB) from the research paper "A Contextual-Bandit Approach to Personalized News Article Recommendation" (Li et al., 2010, WWW Conference). This algorithm is used in content recommendation and ad placement systems.
How It Works:
Each policy (AggressiveTrend, ConservativeRange, VolatilityBreakout, etc.) is treated as an "arm." The system maintains:
Reward History: Tracks wins/losses for each policy
Contextual Features: Current market state (8-10 features including ADX, entropy, volatility, volume)
Uncertainty Estimates: Confidence in each policy's performance
UCB Formula: predicted_reward + α × uncertainty
The system selects the policy with highest UCB score , balancing proven performance (predicted_reward) with potential for discovery (uncertainty bonus). Initially, all policies have high uncertainty, so the system explores broadly. After 50-100 trades, uncertainty decreases, and the system focuses on known-performing policies.
Why This Matters:
Traditional systems pick strategies based on historical backtests or user preference. RPD learns from actual outcomes in your specific market, on your timeframe, with your execution characteristics.
Component 2: Random Fourier Features (RFF)
The Non-Linearity Challenge:
Market relationships are often non-linear. High ADX may indicate favorable conditions when volatility is normal, but unfavorable when volatility spikes. Simple linear models struggle to capture these interactions.
Academic Foundation:
RPD implements Random Fourier Features from "Random Features for Large-Scale Kernel Machines" (Rahimi & Recht, 2007, NIPS). This technique approximates kernel methods (like Support Vector Machines) while maintaining computational efficiency for real-time trading.
How It Works:
The system transforms base features (ADX, entropy, volatility, etc.) into a higher-dimensional space using random projections and cosine transformations:
Input: 8 base features
Projection: Through random Gaussian weights
Transformation: cos(W×features + b)
Output: 16 RFF dimensions
This allows the bandit to learn non-linear relationships between market context and policy success. For example: "AggressiveTrend performs well when ADX >25 AND entropy <0.6 AND hour >9" becomes naturally encoded in the RFF space.
Why This Matters:
Without RFF, the system could only learn "this policy has X% historical performance." With RFF, it learns "this policy performs differently in these specific contexts" - enabling more nuanced selection.
Component 3: Reinforcement Learning Stack
Beyond bandits, RPD implements a complete RL framework :
Q-Learning: Value-based RL that learns state-action values. Maps 54 discrete market states (trend×volatility×RSI×volume combinations) to 5 actions (4 policies + no-trade). Updates via Bellman equation after each trade. Converges toward optimal policy after 100-200 trades.
TD(λ) with Eligibility Traces: Extension of Q-Learning that propagates credit backwards through time . When a trade produces an outcome, TD(λ) updates not just the final state-action but all states visited during the trade, weighted by eligibility decay (λ=0.90). This accelerates learning from multi-bar trades.
Policy Gradient (REINFORCE): Learns a stochastic policy directly from 12 continuous market features without discretization. Uses gradient ascent to increase probability of actions that led to positive outcomes. Includes baseline (average reward) for variance reduction.
Meta-Learning: The system learns how to learn by adapting its own learning rates based on feature stability and correlation with outcomes. If a feature (like volume ratio) consistently correlates with success, its learning rate increases. If unstable, rate decreases.
Why This Matters:
Q-Learning provides fast discrete decisions. Policy Gradient handles continuous features. TD(λ) accelerates learning. Meta-learning optimizes the optimization. Together, they create a robust, multi-approach learning system that adapts more quickly than any single algorithm.
Component 4: Policy Momentum Tracking (v2 Feature)
The Recency Challenge:
Standard bandits treat all historical data equally. If a policy performed well historically but struggles in current conditions due to regime shift, the system may be slow to adapt because historical success outweighs recent underperformance.
RPD's Solution:
Each policy maintains a ring buffer of the last 10 outcomes. The system calculates:
Momentum: recent_win_rate - global_win_rate (range: -1 to +1)
Confidence: consistency of recent results (1 - variance)
Policies with positive momentum (recent outperformance) get an exploration bonus. Policies with negative momentum and high confidence (consistent recent underperformance) receive a selection penalty.
Effect: When markets shift, the system detects the shift more quickly through momentum tracking, enabling faster adaptation than standard bandits.
Signal Generation: The Core Algorithm
Multi-Timeframe Fractal Detection
RPD identifies reversal points using three complementary methods :
1. Quantum State Analysis:
Divides price range into discrete states (default: 6 levels)
Peak signals require price in top states (≥ state 5)
Valley signals require price in bottom states (≤ state 1)
Prevents mid-range signals that may struggle in strong trends
2. Fractal Geometry:
Identifies swing highs/lows using configurable fractal strength
Confirms local extremum with neighboring bars
Validates reversal only if price crosses prior extreme
3. Multi-Timeframe Confirmation:
Analyzes higher timeframe (4× default) for alignment
MTF confirmation adds probability bonus
Designed to reduce false signals while preserving valid setups
Probability Scoring System
Each signal receives a dynamic probability score (40-99%) based on:
Base Components:
Trend Strength: EMA(velocity) / ATR × 30 points
Entropy Quality: (1 - entropy) × 10 points
Starting baseline: 40 points
Enhancement Bonuses:
Divergence Detection: +20 points (price/momentum divergence)
RSI Extremes: +8 points (RSI >65 for peaks, <40 for valleys)
Volume Confirmation: +5 points (volume >1.2× average)
Adaptive Momentum: +10 points (strong directional velocity)
MTF Alignment: +12 points (higher timeframe confirms)
Range Factor: (high-low)/ATR × 3 - 1.5 points (volatility adjustment)
Regime Bonus: +8 points (trending ADX >25 with directional agreement)
Penalties:
High Entropy: -5 points (entropy >0.85, chaotic price action)
Consolidation Regime: -10 points (ADX <20, no directional conviction)
Final Score: Clamped to 40-99% range, classified as ELITE (>85%), STRONG (75-85%), GOOD (65-75%), or FAIR (<65%)
Entropy-Based Quality Filter
What Is Entropy?
Entropy measures randomness in price changes . Low entropy indicates orderly, directional moves. High entropy indicates chaotic, unpredictable conditions.
Calculation:
Count up/down price changes over adaptive period
Calculate probability: p = ups / total_changes
Shannon entropy: -p×log(p) - (1-p)×log(1-p)
Normalized to 0-1 range
Application:
Entropy <0.5: Highly ordered (ELITE signals possible)
Entropy 0.5-0.75: Mixed (GOOD signals)
Entropy >0.85: Chaotic (signals blocked or heavily penalized)
Why This Matters:
Prevents trading during choppy, news-driven conditions where technical patterns may be less reliable. Automatically raises quality bar when market is unpredictable.
Regime Detection & Market Microstructure - ADX-Based Regime Classification
RPD uses Wilder's Average Directional Index to classify markets:
Bull Trend: ADX >25, +DI > -DI (directional conviction bullish)
Bear Trend: ADX >25, +DI < -DI (directional conviction bearish)
Consolidation: ADX <20 (no directional conviction)
Transitional: ADX 20-25 (forming direction, ambiguous)
Filter Logic:
Blocks all signals during Transitional regime (avoids trading during uncertain conditions)
Blocks Consolidation signals unless ADX ≥ Min Trend Strength
Adds probability bonus during strong trends (ADX >30)
Effect: Designed to reduce signal frequency while focusing on higher-quality setups.
Divergence Detection
Bearish Divergence:
Price makes higher high
Velocity (price momentum) makes lower high
Indicates weakening upward pressure → SHORT signal quality boost
Bullish Divergence:
Price makes lower low
Velocity makes higher low
Indicates weakening downward pressure → LONG signal quality boost
Bonus: Adds probability points and additional acceleration factor. Divergence signals have historically shown higher success rates in testing.
Hierarchical Policy System - The Six Trading Policies
1. AggressiveTrend (Policy 0):
Probability Threshold: 60% (trades more frequently)
Entropy Threshold: 0.70 (tolerates moderate chaos)
Stop Multiplier: 2.5× ATR (wider stops for trends)
Target Multiplier: 5.0R (larger targets)
Entry Mode: Pyramid (scales into winners)
Best For: Strong trending markets, breakouts, momentum continuation
2. ConservativeRange (Policy 1):
Probability Threshold: 75% (more selective)
Entropy Threshold: 0.60 (requires order)
Stop Multiplier: 1.8× ATR (tighter stops)
Target Multiplier: 3.0R (modest targets)
Entry Mode: Single (one-shot entries)
Best For: Range-bound markets, low volatility, mean reversion
3. VolatilityBreakout (Policy 2):
Probability Threshold: 65% (moderate)
Entropy Threshold: 0.80 (accepts high entropy)
Stop Multiplier: 3.0× ATR (wider stops)
Target Multiplier: 6.0R (larger targets)
Entry Mode: Tiered (splits entry)
Best For: Compression breakouts, post-consolidation moves, gap opens
4. EntropyScalp (Policy 3):
Probability Threshold: 80% (very selective)
Entropy Threshold: 0.40 (requires extreme order)
Stop Multiplier: 1.5× ATR (tightest stops)
Target Multiplier: 2.5R (quick targets)
Entry Mode: Single
Best For: Low-volatility grinding moves, tight ranges, highly predictable patterns
5. DivergenceHunter (Policy 4):
Probability Threshold: 70% (quality-focused)
Entropy Threshold: 0.65 (balanced)
Stop Multiplier: 2.2× ATR (moderate stops)
Target Multiplier: 4.5R (balanced targets)
Entry Mode: Tiered
Best For: Divergence-confirmed reversals, exhaustion moves, trend climax
6. AdaptiveBlend (Policy 5):
Probability Threshold: 68% (balanced)
Entropy Threshold: 0.75 (balanced)
Stop Multiplier: 2.0× ATR (standard)
Target Multiplier: 4.0R (standard)
Entry Mode: Single
Best For: Mixed conditions, general trading, fallback when no clear regime
Policy Clustering (Advanced/Extreme Modes)
Policies are grouped into three clusters based on regime affinity:
Cluster 1 (Trending): AggressiveTrend, DivergenceHunter
High regime affinity (0.8): Performs well when ADX >25
Moderate vol affinity (0.6): Works in various volatility
Cluster 2 (Ranging): ConservativeRange, AdaptiveBlend
Low regime affinity (0.3): Better suited for ADX <20
Low vol affinity (0.4): Optimized for calm markets
Cluster 3 (Breakout): VolatilityBreakout
Moderate regime affinity (0.6): Works in multiple regimes
High vol affinity (0.9): Requires high volatility for optimal characteristics
Hierarchical Selection Process:
Calculate cluster scores based on current regime and volatility
Select best-matching cluster
Run UCB selection within chosen cluster
Apply momentum boost/penalty
This two-stage process reduces learning time - instead of choosing among 6 policies from scratch, system first narrows to 1-2 policies per cluster, then optimizes within cluster.
Risk Management & Position Sizing
Dynamic Kelly Criterion Sizing (Optional)
Traditional Fixed Sizing Challenge:
Using the same position size for all signal probabilities may be suboptimal. Higher-probability signals could justify larger positions, lower-probability signals smaller positions.
Kelly Formula:
f = (p × b - q) / b
Where:
p = win probability (from signal score)
q = loss probability (1 - p)
b = win/loss ratio (average_win / average_loss)
f = fraction of capital to risk
RPD Implementation:
Uses Fractional Kelly (1/4 Kelly default) for safety. Full Kelly is theoretically optimal but can recommend large position sizes. Fractional Kelly reduces volatility while maintaining adaptive sizing benefits.
Enhancements:
Probability Bonus: Normalize(prob, 65, 95) × 0.5 multiplier
Divergence Bonus: Additional sizing on divergence signals
Regime Bonus: Additional sizing during strong trends (ADX >30)
Momentum Adjustment: Hot policies receive sizing boost, cold policies receive reduction
Safety Rails:
Minimum: 1 contract (floor)
Maximum: User-defined cap (default 10 contracts)
Portfolio Heat: Max total risk across all positions (default 4% equity)
Multi-Mode Stop Loss System
ATR Mode (Default):
Stop = entry ± (ATR × base_mult × policy_mult)
Consistent risk sizing
Ignores market structure
Best for: Futures, forex, algorithmic trading
Structural Mode:
Finds swing low (long) or high (short) over last 20 bars
Identifies fractal pivots within lookback
Places stop below/above structure + buffer (0.1× ATR)
Best for: Stocks, instruments that respect structure
Hybrid Mode (Intelligent):
Attempts structural stop first
Falls back to ATR if:
Structural level is invalid (beyond entry)
Structural stop >2× ATR away (too wide)
Best for: Mixed instruments, adaptability
Dynamic Adjustments:
Breakeven: Move stop to entry + 1 tick after 1.0R profit
Trailing: Trail stop 0.8R behind price after 1.5R profit
Timeout: Force close after 30 bars (optional)
Tiered Entry System
Challenge: Equal sizing on all signals may not optimize capital allocation relative to signal quality.
Solution:
Tier 1 (40% of size): Enters immediately on all signals
Tier 2 (60% of size): Enters only if probability ≥ Tier 2 trigger (default 75%)
Example:
Calculated optimal size: 10 contracts
Signal probability: 72%
Tier 2 trigger: 75%
Result: Enter 4 contracts only (Tier 1)
Same signal at 80% probability
Result: Enter 10 contracts (4 Tier 1 + 6 Tier 2)
Effect: Automatically scales size to signal quality, optimizing capital allocation.
Performance Optimization & Learning Curve
Warmup Phase (First 50 Trades)
Purpose: Ensure all policies get tested before system focuses on preferred strategies.
Modifications During Warmup:
Probability thresholds reduced 20% (65% becomes 52%)
Entropy thresholds increased 20% (more permissive)
Exploration rate stays high (30%)
Confidence width (α) doubled (more exploration)
Why This Matters:
Without warmup, system might commit to early-performing policy without testing alternatives. Warmup forces thorough exploration before focusing on best-performing strategies.
Curriculum Learning
Phase 1 (Trades 1-50): Exploration
Warmup active
All policies tested
High exploration (30%)
Learning fundamental patterns
Phase 2 (Trades 50-100): Refinement
Warmup ended, thresholds normalize
Exploration decaying (30% → 15%)
Policy preferences emerging
Meta-learning optimizing
Phase 3 (Trades 100-200): Specialization
Exploration low (15% → 8%)
Clear policy preferences established
Momentum tracking fully active
System focusing on learned patterns
Phase 4 (Trades 200+): Maturity
Exploration minimal (8% → 5%)
Regime-policy relationships learned
Auto-adaptation to market shifts
Stable performance expected
Convergence Indicators
System is learning well when:
Policy switch rate decreasing over time (initially ~50%, should drop to <20%)
Exploration rate decaying smoothly (30% → 5%)
One or two policies emerge with >50% selection frequency
Performance metrics stabilizing over time
Consistent behavior in similar market conditions
System may need adjustment when:
Policy switch rate >40% after 100 trades (excessive exploration)
Exploration rate not decaying (parameter issue)
All policies showing similar selection (not differentiating)
Performance declining despite relaxed thresholds (underlying signal issue)
Highly erratic behavior after learning phase
Advanced Features
Attention Mechanism (Extreme Mode)
Challenge: Not all features are equally important. Trading hour might matter more than price-volume correlation, but standard approaches treat them equally.
Solution:
Each RFF dimension has an importance weight . After each trade:
Calculate correlation: sign(feature - 0.5) × sign(reward)
Update importance: importance += correlation × 0.01
Clamp to range
Effect: Important features get amplified in RFF transformation, less important features get suppressed. System learns which features correlate with successful outcomes.
Temporal Context (Extreme Mode)
Challenge: Current market state alone may be incomplete. Historical context (was volatility rising or falling?) provides additional information.
Solution:
Includes 3-period historical context with exponential decay (0.85):
Current features (weight 1.0)
1 bar ago (weight 0.85)
2 bars ago (weight 0.72)
Effect: Captures momentum and acceleration of market features. System learns patterns like "rising volatility with falling entropy" that may precede significant moves.
Transfer Learning via Episodic Memory
Short-Term Memory (STM):
Last 20 trades
Fast adaptation to immediate regime
High learning rate
Long-Term Memory (LTM):
Condensed historical patterns
Preserved knowledge from past regimes
Low learning rate
Transfer Mechanism:
When STM fills (20 trades), patterns consolidated into LTM . When similar regime recurs later, LTM provides faster adaptation than starting from scratch.
Practical Implementation Guide - Recommended Settings by Instrument
Futures (ES, NQ, CL):
Adaptive Period: 20-25
ML Mode: Advanced
RFF Dimensions: 16
Policies: 6
Base Risk: 1.5%
Stop Mode: ATR or Hybrid
Timeframe: 5-15 min
Forex Majors (EURUSD, GBPUSD):
Adaptive Period: 25-30
ML Mode: Advanced
RFF Dimensions: 16
Policies: 6
Base Risk: 1.0-1.5%
Stop Mode: ATR
Timeframe: 5-30 min
Cryptocurrency (BTC, ETH):
Adaptive Period: 20-25
ML Mode: Extreme (handles non-stationarity)
RFF Dimensions: 32 (captures complexity)
Policies: 6
Base Risk: 1.0% (volatility consideration)
Stop Mode: Hybrid
Timeframe: 15 min - 4 hr
Stocks (Large Cap):
Adaptive Period: 25-30
ML Mode: Advanced
RFF Dimensions: 16
Policies: 5-6
Base Risk: 1.5-2.0%
Stop Mode: Structural or Hybrid
Timeframe: 15 min - Daily
Scaling Strategy
Phase 1 (Testing - First 50 Trades):
Max Contracts: 1-2
Goal: Validate system on your instrument
Monitor: Performance stabilization, learning progress
Phase 2 (Validation - Trades 50-100):
Max Contracts: 2-3
Goal: Confirm learning convergence
Monitor: Policy stability, exploration decay
Phase 3 (Scaling - Trades 100-200):
Max Contracts: 3-5
Enable: Kelly sizing (1/4 Kelly)
Goal: Optimize capital efficiency
Monitor: Risk-adjusted returns
Phase 4 (Full Deployment - Trades 200+):
Max Contracts: 5-10
Enable: Full momentum tracking
Goal: Sustained consistent performance
Monitor: Ongoing adaptation quality
Limitations & Disclaimers
Statistical Limitations
Learning Sample Size: System requires minimum 50-100 trades for basic convergence, 200+ trades for robust learning. Early performance (first 50 trades) may not reflect mature system behavior.
Non-Stationarity Risk: Markets change over time. A system trained on one market regime may need time to adapt when conditions shift (typically 30-50 trades for adjustment).
Overfitting Possibility: With 16-32 RFF dimensions and 6 policies, system has substantial parameter space. Small sample sizes (<200 trades) increase overfitting risk. Mitigated by regularization (λ) and fractional Kelly sizing.
Technical Limitations
Computational Complexity: Extreme mode with 32 RFF dimensions, 6 policies, and full RL stack requires significant computation. May perform slowly on lower-end systems or with many other indicators loaded.
Pine Script Constraints:
No true matrix inversion (uses diagonal approximation for LinUCB)
No cryptographic RNG (uses market data as entropy)
No proper random number generation for RFF (uses deterministic pseudo-random)
These approximations reduce mathematical precision compared to academic implementations but remain functional for trading applications.
Data Requirements: Needs clean OHLCV data. Missing bars, gaps, or low liquidity (<100k daily volume) can degrade signal quality.
Forward-Looking Bias Disclaimer
Reward Calculation Uses Future Data: The RL system evaluates trades using an 8-bar forward-looking window. This means when a position enters at bar 100, the reward calculation considers price movement through bar 108.
Why This is Disclosed:
Entry signals do NOT look ahead - decisions use only data up to entry bar
Forward data used for learning only, not signal generation
In live trading, system learns identically as bars unfold in real-time
Simulates natural learning process (outcomes are only known after trades complete)
Implication: Backtested metrics reflect this 8-bar evaluation window. Live performance may vary if:
- Positions held longer than 8 bars
- Slippage/commissions differ from backtest settings
- Market microstructure changes (wider spreads, different execution quality)
Risk Warnings
No Guarantee of Profit: All trading involves substantial risk of loss. Machine learning systems can fail if market structure fundamentally changes or during unprecedented events.
Maximum Drawdown: With 1.5% base risk and 4% max total risk, expect potential drawdowns. Historical drawdowns do not predict future drawdowns. Extreme market conditions can exceed expectations.
Black Swan Events: System has not been tested under: flash crashes, trading halts, circuit breakers, major geopolitical shocks, or other extreme events. Such events can exceed stop losses and cause significant losses.
Leverage Risk: Futures and forex involve leverage. Adverse moves combined with leverage can result in losses exceeding initial investment. Use appropriate position sizing for your risk tolerance.
System Failures: Code bugs, broker API failures, internet outages, or exchange issues can prevent proper execution. Always monitor automated systems and maintain appropriate safeguards.
Appropriate Use
This System Is:
✅ A machine learning framework for adaptive strategy selection
✅ A signal generation system with probabilistic scoring
✅ A risk management system with dynamic sizing
✅ A learning system designed to adapt over time
This System Is NOT:
❌ A price prediction system (does not forecast exact prices)
❌ A guarantee of profits (can and will experience losses)
❌ A replacement for due diligence (requires monitoring and understanding)
❌ Suitable for complete beginners (requires understanding of ML concepts, risk management, and trading fundamentals)
Recommended Use:
Paper trade for 100 signals before risking capital
Start with minimal position sizing (1-2 contracts) regardless of calculated size
Monitor learning progress via dashboard
Scale gradually over several months only after consistent results
Combine with fundamental analysis and broader market context
Set account-level risk limits (e.g., maximum drawdown threshold)
Never risk more than you can afford to lose
What Makes This System Different
RPD implements academically-derived machine learning algorithms rather than simple mathematical calculations or optimization:
✅ LinUCB Contextual Bandits - Algorithm from WWW 2010 conference (Li et al.)
✅ Random Fourier Features - Kernel approximation from NIPS 2007 (Rahimi & Recht)
✅ Q-Learning, TD(λ), REINFORCE - Standard RL algorithms from Sutton & Barto textbook
✅ Meta-Learning - Learning rate adaptation based on feature correlation
✅ Online Learning - Real-time updates from streaming data
✅ Hierarchical Policies - Two-stage selection with clustering
✅ Momentum Tracking - Recent performance analysis for faster adaptation
✅ Attention Mechanism - Feature importance weighting
✅ Transfer Learning - Episodic memory consolidation
Key Differentiators:
Actually learns from trade outcomes (not just parameter optimization)
Updates model parameters in real-time (true online learning)
Adapts to changing market regimes (not static rules)
Improves over time through reinforcement learning
Implements published ML algorithms with proper citations
Conclusion
RPD Machine Learning represents a different approach from traditional technical analysis to adaptive, self-learning systems . Instead of manually optimizing parameters (which can overfit to historical data), RPD learns behavior patterns from actual trading outcomes in your specific market.
The combination of contextual bandits, reinforcement learning, random fourier features, hierarchical policy selection, and momentum tracking creates a multi-algorithm learning system designed to handle non-stationary markets better than static approaches.
After the initial learning phase (50-100 trades), the system achieves autonomous adaptation - automatically discovering which strategies work in current conditions and shifting allocation without human intervention. This represents an approach where systems adapt over time rather than remaining static.
Use responsibly. Paper trade extensively. Scale gradually. Understand that past performance does not guarantee future results and all trading involves risk of loss.
Taking you to school. — Dskyz, Trade with insight. Trade with anticipation.

Any Strategy BacktestA simple script for backtesting your strategies with TP and SL settings. For this to work, your indicators must have sources for long and short conditions.


Rons Custom WatermarkRon's Custom Watermark (RCW)
This is a lightweight, all-in-one watermark indicator that displays essential fundamental and technical data directly on your chart. It's designed to give you a quick, at-a-glance overview of any asset without cluttering your screen.
Features
The watermark displays the following information in a clean table:
* Company Info: Full Name & Market Cap (e.g., "AST SpaceMobile, Inc. (18.85B)")
* Symbol & Timeframe: Ticker and current chart period (e.g., "ASTS, 1D")
* Sector & Industry: The asset's classification.
* Technical Status (MA): Shows if the price is Above or Below the SMA (with a 🟢/🔴 emoji).
* Technical Status (EMA): Shows if the price is Above or Below the EMA (with a 🟢/🔴 emoji).
* Earnings: A countdown showing "X days remaining" until the next earnings report.
* (Optional) Volatility: The 14-day ATR value and its percentage of the current price.

Weekly Fibonacci Pivot Signals (4H) - S1/R1 & S3/R3 rulesThis Indicator used weekly price range to calculate the pivot R1,R3,S1 and S3 ,when price crossed and closed below R3 in 4H timeframe the indicator gives sell signal, when the price crossed and close above the S3 the indicator gives buy signal. This indicator can give approximately 50% win Rate .

Algorithm Predator - ProAlgorithm Predator - Pro: Advanced Multi-Agent Reinforcement Learning Trading System
Algorithm Predator - Pro combines four specialized market microstructure agents with a state-of-the-art reinforcement learning framework . Unlike traditional indicator mashups, this system implements genuine machine learning to automatically discover which detection strategies work best in current market conditions and adapts continuously without manual intervention.
Core Innovation: Rather than forcing traders to interpret conflicting signals, this system uses 15 different multi-armed bandit algorithms and a full reinforcement learning stack (Q-Learning, TD(λ) with eligibility traces, and Policy Gradient with REINFORCE) to learn optimal agent selection policies. The result is a self-improving system that gets smarter with every trade.
Target Users: Swing traders, day traders, and algorithmic traders seeking systematic signal generation with mathematical rigor. Suitable for stocks, forex, crypto, and futures on liquid instruments (>100k daily volume).
Why These Components Are Combined
The Fundamental Problem
No single indicator works consistently across all market regimes. What works in trending markets fails in ranging conditions. Traditional solutions force traders to manually switch indicators (slow, error-prone) or interpret all signals simultaneously (cognitive overload).
This system solves the problem through automated meta-learning: Deploy multiple specialized agents designed for specific market microstructure conditions, then use reinforcement learning to discover which agent (or combination) performs best in real-time.
Why These Specific Four Agents?
The four agents provide orthogonal failure mode coverage —each agent's weakness is another's strength:
Spoofing Detector - Optimal in consolidation/manipulation; fails in trending markets (hedged by Exhaustion Detector)
Exhaustion Detector - Optimal at trend climax; fails in range-bound markets (hedged by Liquidity Void)
Liquidity Void - Optimal pre-breakout compression; fails in established trends (hedged by Mean Reversion)
Mean Reversion - Optimal in low volatility; fails in strong trends (hedged by Spoofing Detector)
This creates complete market state coverage where at least one agent should perform well in any condition. The bandit system identifies which one without human intervention.
Why Reinforcement Learning vs. Simple Voting?
Traditional consensus systems have fatal flaws: equal weighting assumes all agents are equally reliable (false), static thresholds don't adapt, and no learning means past mistakes repeat indefinitely.
Reinforcement learning solves this through the exploration-exploitation tradeoff: Continuously test underused agents (exploration) while primarily relying on proven winners (exploitation). Over time, the system builds a probability distribution over agent quality reflecting actual market performance.
Mathematical Foundation: Multi-armed bandit problem from probability theory, where each agent is an "arm" with unknown reward distribution. The goal is to maximize cumulative reward while efficiently learning each arm's true quality.
The Four Trading Agents: Technical Explanation
Agent 1: 🎭 Spoofing Detector (Institutional Manipulation Detection)
Theoretical Basis: Market microstructure theory on order flow toxicity and information asymmetry. Based on research by Easley, López de Prado, and O'Hara on high-frequency trading manipulation.
What It Detects:
1. Iceberg Orders (Hidden Liquidity Absorption)
Method: Monitors volume spikes (>2.5× 20-period average) with minimal price movement (<0.3× ATR)
Formula: score += (close > open ? -2.5 : 2.5) when volume > vol_avg × 2.5 AND abs(close - open) / ATR < 0.3
Interpretation: Large volume without price movement indicates institutional absorption (buying) or distribution (selling) using hidden orders
Signal Logic: Contrarian—fade false breakouts caused by institutional manipulation
2. Spoofing Patterns (Fake Liquidity via Layering)
Method: Analyzes candlestick wick-to-body ratios during volume spikes
Formula: if upper_wick > body × 2 AND volume_spike: score += 2.0
Mechanism: Spoofing creates large wicks (orders pulled before execution) with volume evidence
Signal Logic: Wick direction indicates trapped participants; trade against the failed move
3. Post-Manipulation Reversals
Method: Tracks volume decay after manipulation events
Formula: if volume > vol_avg × 3 AND volume / volume < 0.3: score += (close > open ? -1.5 : 1.5)
Interpretation: Sharp volume drop after manipulation indicates exhaustion of manipulative orders
Why It Works: Institutional manipulation creates detectable microstructure anomalies. While retail traders see "mysterious reversals," this agent quantifies the order flow patterns causing them.
Parameter: i_spoof (sensitivity 0.5-2.0) - Controls detection threshold
Best Markets: Consolidations before breakouts, London/NY overlap windows, stocks with institutional ownership >70%
Agent 2: ⚡ Exhaustion Detector (Momentum Failure Analysis)
Theoretical Basis: Technical analysis divergence theory combined with VPIN reversals from market microstructure literature.
What It Detects:
1. Price-RSI Divergence (Momentum Deceleration)
Method: Compares 5-bar price ROC against RSI change
Formula: if price_roc > 5% AND rsi_current < rsi : score += 1.8
Mathematics: Second derivative detecting inflection points
Signal Logic: When price makes higher highs but momentum makes lower highs, expect mean reversion
2. Volume Exhaustion (Buying/Selling Climax)
Method: Identifies strong price moves (>5% ROC) with declining volume (<-20% volume ROC)
Formula: if price_roc > 5 AND vol_roc < -20: score += 2.5
Interpretation: Price extension without volume support indicates retail chasing while institutions exit
3. Momentum Deceleration (Acceleration Analysis)
Method: Compares recent 3-bar momentum to prior 3-bar momentum
Formula: deceleration = abs(mom1) < abs(mom2) × 0.5 where momentum significant (> ATR)
Signal Logic: When rate of price change decelerates significantly, anticipate directional shift
Why It Works: Momentum is lagging, but momentum divergence is leading. By comparing momentum's rate of change to price, this agent detects "weakening conviction" before reversals become obvious.
Parameter: i_momentum (sensitivity 0.5-2.0)
Best Markets: Strong trends reaching climax, parabolic moves, instruments with high retail participation
Agent 3: 💧 Liquidity Void Detector (Breakout Anticipation)
Theoretical Basis: Market liquidity theory and order book dynamics. Based on research into "liquidity holes" and volatility compression preceding expansion.
What It Detects:
1. Bollinger Band Squeeze (Volatility Compression)
Method: Monitors Bollinger Band width relative to 50-period average
Formula: bb_width = (upper_band - lower_band) / middle_band; triggers when < 0.6× average
Mathematical Foundation: Regression to the mean—low volatility precedes high volatility
Signal Logic: When volatility compresses AND cumulative delta shows directional bias, anticipate breakout
2. Volume Profile Gaps (Thin Liquidity Zones)
Method: Identifies sharp volume transitions indicating few limit orders
Formula: if volume < vol_avg × 0.5 AND volume < vol_avg × 0.5 AND volume > vol_avg × 1.5
Interpretation: Sudden volume drop after spike indicates price moved through order book to low-opposition area
Signal Logic: Price accelerates through low-liquidity zones
3. Stop Hunts (Liquidity Grabs Before Reversals)
Method: Detects new 20-bar highs/lows with immediate reversal and rejection wick
Formula: if new_high AND close < high - (high - low) × 0.6: score += 3.0
Mechanism: Market makers push price to trigger stop-loss clusters, then reverse
Signal Logic: Enter reversal after stop-hunt completes
Why It Works: Order book theory shows price moves fastest through zones with minimal liquidity. By identifying these zones before major moves, this agent provides early entry for high-reward breakouts.
Parameter: i_liquidity (sensitivity 0.5-2.0)
Best Markets: Range-bound pre-breakout setups, volatility compression zones, instruments prone to gap moves
Agent 4: 📊 Mean Reversion (Statistical Arbitrage Engine)
Theoretical Basis: Statistical arbitrage theory, Ornstein-Uhlenbeck mean-reverting processes, and pairs trading methodology applied to single instruments.
What It Detects:
1. Z-Score Extremes (Standard Deviation Analysis)
Method: Calculates price distance from 20-period and 50-period SMAs in standard deviation units
Formula: zscore_20 = (close - SMA20) / StdDev(50)
Statistical Interpretation: Z-score >2.0 means price is 2 standard deviations above mean (97.5th percentile)
Trigger Logic: if abs(zscore_20) > 2.0: score += zscore_20 > 0 ? -1.5 : 1.5 (fade extremes)
2. Ornstein-Uhlenbeck Process (Mean-Reverting Stochastic Model)
Method: Models price as mean-reverting stochastic process: dx = θ(μ - x)dt + σdW
Implementation: Calculates spread = close - SMA20, then z-score of spread vs. spread distribution
Formula: ou_signal = (spread - spread_mean) / spread_std
Interpretation: Measures "tension" pulling price back to equilibrium
3. Correlation Breakdown (Regime Change Detection)
Method: Compares 50-period price-volume correlation to 10-period correlation
Formula: corr_breakdown = abs(typical_corr - recent_corr) > 0.5
Enhancement: if corr_breakdown AND abs(zscore_20) > 1.0: score += zscore_20 > 0 ? -1.2 : 1.2
Why It Works: Mean reversion is the oldest quantitative strategy (1970s pairs trading at Morgan Stanley). While simple, it remains effective because markets exhibit periodic equilibrium-seeking behavior. This agent applies rigorous statistical testing to identify when mean reversion probability is highest.
Parameter: i_statarb (sensitivity 0.5-2.0)
Best Markets: Range-bound instruments, low-volatility periods (VIX <15), algo-dominated markets (forex majors, index futures)
Multi-Armed Bandit System: 15 Algorithms Explained
What Is a Multi-Armed Bandit Problem?
Origin: Named after slot machines ("one-armed bandits"). Imagine facing multiple slot machines, each with unknown payout rates. How do you maximize winnings?
Formal Definition: K arms (agents), each with unknown reward distribution with mean μᵢ. Goal: Maximize cumulative reward over T trials. Challenge: Balance exploration (trying uncertain arms to learn quality) vs. exploitation (using known-best arm for immediate reward).
Trading Application: Each agent is an "arm." After each trade, receive reward (P&L). Must decide which agent to trust for next signal.
Algorithm Categories
Bayesian Approaches (probabilistic, optimal for stationary environments):
Thompson Sampling
Bootstrapped Thompson Sampling
Discounted Thompson Sampling
Frequentist Approaches (confidence intervals, deterministic):
UCB1
UCB1-Tuned
KL-UCB
SW-UCB (Sliding Window)
D-UCB (Discounted)
Adversarial Approaches (robust to non-stationary environments):
EXP3-IX
Hedge
FPL-Gumbel
Reinforcement Learning Approaches (leverage learned state-action values):
Q-Values (from Q-Learning)
Policy Network (from Policy Gradient)
Simple Baseline:
Epsilon-Greedy
Softmax
Key Algorithm Details
Thompson Sampling (DEFAULT - RECOMMENDED)
Theoretical Foundation: Bayesian decision theory with conjugate priors. Published by Thompson (1933), rediscovered for bandits by Chapelle & Li (2011).
How It Works:
Model each agent's reward distribution as Beta(α, β) where α = wins, β = losses
Each step, sample from each agent's beta distribution: θᵢ ~ Beta(αᵢ, βᵢ)
Select agent with highest sample: argmaxᵢ θᵢ
Update winner's distribution after observing outcome
Mathematical Properties:
Optimality: Achieves logarithmic regret O(K log T) (proven optimal)
Bayesian: Maintains probability distribution over true arm means
Automatic Balance: High uncertainty → more exploration; high certainty → exploitation
⚠️ CRITICAL APPROXIMATION: This is a pseudo-random approximation of true Thompson Sampling. True implementation requires random number generation from beta distributions, which Pine Script doesn't provide. This version uses Box-Muller transform with market data (price/volume decimal digits) as entropy source. While not mathematically pure, it maintains core exploration-exploitation balance and learns agent preferences effectively.
When To Use: Best all-around choice. Handles non-stationary markets reasonably well, balances exploration naturally, highly sample-efficient.
UCB1 (Upper Confidence Bound)
Formula: UCB_i = reward_mean_i + sqrt(2 × ln(total_pulls) / pulls_i)
Interpretation: First term (exploitation) + second term (exploration bonus for less-tested arms)
Mathematical Properties:
Deterministic : Always selects same arm given same state
Regret Bound: O(K log T) — same optimality as Thompson Sampling
Interpretable: Can visualize confidence intervals
When To Use: Prefer deterministic behavior, want to visualize uncertainty, stable markets
EXP3-IX (Exponential Weights - Adversarial)
Theoretical Foundation: Adversarial bandit algorithm. Assumes environment may be actively hostile (worst-case analysis).
How It Works:
Maintain exponential weights: w_i = exp(η × cumulative_reward_i)
Select agent with probability proportional to weights: p_i = (1-γ)w_i/Σw_j + γ/K
After outcome, update with importance weighting: estimated_reward = observed_reward / p_i
Mathematical Properties:
Adversarial Regret: O(sqrt(TK log K)) even if environment is adversarial
No Assumptions: Doesn't assume stationary or stochastic reward distributions
Robust: Works even when optimal arm changes continuously
When To Use: Extreme non-stationarity, don't trust reward distribution assumptions, want robustness over efficiency
KL-UCB (Kullback-Leibler Upper Confidence Bound)
Theoretical Foundation: Uses KL-divergence instead of Hoeffding bounds. Tighter confidence intervals.
Formula (conceptual): Find largest q such that: n × KL(p||q) ≤ ln(t) + 3×ln(ln(t))
Mathematical Properties:
Tighter Bounds: KL-divergence adapts to reward distribution shape
Asymptotically Optimal: Better constant factors than UCB1
Computationally Intensive: Requires iterative binary search (15 iterations)
When To Use: Maximum sample efficiency needed, willing to pay computational cost, long-term trading (>500 bars)
Q-Values & Policy Network (RL-Based Selection)
Unique Feature: Instead of treating agents as black boxes with scalar rewards, these algorithms leverage the full RL state representation .
Q-Values Selection:
Uses learned Q-values: Q(state, agent_i) from Q-Learning
Selects agent via softmax over Q-values for current market state
Advantage: Selects based on state-conditional quality (which agent works best in THIS market state)
Policy Network Selection:
Uses neural network policy: π(agent | state, θ) from Policy Gradient
Direct policy over agents given market features
Advantage: Can learn non-linear relationships between market features and agent quality
When To Use: After 200+ RL updates (Q-Values) or 500+ updates (Policy Network) when models converged
Machine Learning & Reinforcement Learning Stack
Why Both Bandits AND Reinforcement Learning?
Critical Distinction:
Bandits treat agents as contextless black boxes: "Agent 2 has 60% win rate"
Reinforcement Learning adds state context: "Agent 2 has 60% win rate WHEN trend_score > 2 and RSI < 40"
Power of Combination: Bandits provide fast initial learning with minimal assumptions. RL provides state-dependent policies for superior long-term performance.
Component 1: Q-Learning (Value-Based RL)
Algorithm: Temporal Difference Learning with Bellman equation.
State Space: 54 discrete states formed from:
trend_state = {0: bearish, 1: neutral, 2: bullish} (3 values)
volatility_state = {0: low, 1: normal, 2: high} (3 values)
RSI_state = {0: oversold, 1: neutral, 2: overbought} (3 values)
volume_state = {0: low, 1: high} (2 values)
Total states: 3 × 3 × 3 × 2 = 54 states
Action Space: 5 actions (No trade, Agent 1, Agent 2, Agent 3, Agent 4)
Total state-action pairs: 54 × 5 = 270 Q-values
Bellman Equation:
Q(s,a) ← Q(s,a) + α ×
Parameters:
α (learning rate): 0.01-0.50, default 0.10 - Controls step size for updates
γ (discount factor): 0.80-0.99, default 0.95 - Values future rewards
ε (exploration): 0.01-0.30, default 0.10 - Probability of random action
Update Mechanism:
Position opens with state s, action a (selected agent)
Every bar position is open: Calculate floating P&L → scale to reward
Perform online TD update
When position closes: Perform terminal update with final reward
Gradient Clipping: TD errors clipped to ; Q-values clipped to for stability.
Why It Works: Q-Learning learns "quality" of each agent in each market state through trial and error. Over time, builds complete state-action value function enabling optimal state-dependent agent selection.
Component 2: TD(λ) Learning (Temporal Difference with Eligibility Traces)
Enhancement Over Basic Q-Learning: Credit assignment across multiple time steps.
The Problem TD(λ) Solves:
Position opens at t=0
Market moves favorably at t=3
Position closes at t=8
Question: Which earlier decisions contributed to success?
Basic Q-Learning: Only updates Q(s₈, a₈) ← reward
TD(λ): Updates ALL visited state-action pairs with decayed credit
Eligibility Trace Formula:
e(s,a) ← γ × λ × e(s,a) for all s,a (decay all traces)
e(s_current, a_current) ← 1 (reset current trace)
Q(s,a) ← Q(s,a) + α × TD_error × e(s,a) (update all with trace weight)
Lambda Parameter (λ): 0.5-0.99, default 0.90
λ=0: Pure 1-step TD (only immediate next state)
λ=1: Full Monte Carlo (entire episode)
λ=0.9: Balance (recommended)
Why Superior: Dramatically faster learning for multi-step tasks. Q-Learning requires many episodes to propagate rewards backwards; TD(λ) does it in one.
Component 3: Policy Gradient (REINFORCE with Baseline)
Paradigm Shift: Instead of learning value function Q(s,a), directly learn policy π(a|s).
Policy Network Architecture:
Input: 12 market features
Hidden: None (linear policy)
Output: 5 actions (softmax distribution)
Total parameters: 12 features × 5 actions + 5 biases = 65 parameters
Feature Set (12 Features):
Price Z-score (close - SMA20) / ATR
Volume ratio (volume / vol_avg - 1)
RSI deviation (RSI - 50) / 50
Bollinger width ratio
Trend score / 4 (normalized)
VWAP deviation
5-bar price ROC
5-bar volume ROC
Range/ATR ratio - 1
Price-volume correlation (20-period)
Volatility ratio (ATR / ATR_avg - 1)
EMA50 deviation
REINFORCE Update Rule:
θ ← θ + α × ∇log π(a|s) × advantage
where advantage = reward - baseline (variance reduction)
Why Baseline? Raw rewards have high variance. Subtracting baseline (running average) centers rewards around zero, reducing gradient variance by 50-70%.
Learning Rate: 0.001-0.100, default 0.010 (much lower than Q-Learning because policy gradients have high variance)
Why Policy Gradient?
Handles 12 continuous features directly (Q-Learning requires discretization)
Naturally maintains exploration through probability distribution
Can converge to stochastic optimal policy
Component 4: Ensemble Meta-Learner (Stacking)
Architecture: Level-1 meta-learner combines Level-0 base learners (Q-Learning, TD(λ), Policy Gradient).
Three Meta-Learning Algorithms:
1. Simple Average (Baseline)
Final_prediction = (Q_prediction + TD_prediction + Policy_prediction) / 3
2. Weighted Vote (Reward-Based)
weight_i ← 0.95 × weight_i + 0.05 × (reward_i + 1)
3. Adaptive Weighting (Gradient-Based) — RECOMMENDED
Loss Function: L = (y_true - ŷ_ensemble)²
Gradient: ∂L/∂weight_i = -2 × (y_true - ŷ_ensemble) × agent_contribution_i
Updates weights via gradient descent with clipping and normalization
Why It Works: Unlike simple averaging, meta-learner discovers which base learner is most reliable in current regime. If Policy Gradient excels in trending markets while Q-Learning excels in ranging, meta-learner learns these patterns and weights accordingly.
Feature Importance Tracking
Purpose: Identify which of 12 features contribute most to successful predictions.
Update Rule: importance_i ← 0.95 × importance_i + 0.05 × |feature_i × reward|
Use Cases:
Feature selection: Drop low-importance features
Market regime detection: Importance shifts reveal regime changes
Agent tuning: If VWAP deviation has high importance, consider boosting agents using VWAP
RL Position Tracking System
Critical Innovation: Proper reinforcement learning requires tracking which decisions led to outcomes.
State Tracking (When Signal Validates):
active_rl_state ← current_market_state (0-53)
active_rl_action ← selected_agent (1-4)
active_rl_entry ← entry_price
active_rl_direction ← 1 (long) or -1 (short)
active_rl_bar ← current_bar_index
Online Updates (Every Bar Position Open):
floating_pnl = (close - entry) / entry × direction
reward = floating_pnl × 10 (scale to meaningful range)
reward = clip(reward, -5.0, 5.0)
Update Q-Learning, TD(λ), and Policy Gradient
Terminal Update (Position Close):
Final Q-Learning update (no next Q-value, terminal state)
Update meta-learner with final result
Update agent memory
Clear position tracking
Exit Conditions:
Time-based: ≥3 bars held (minimum hold period)
Stop-loss: 1.5% adverse move
Take-profit: 2.0% favorable move
Market Microstructure Filters
Why Microstructure Matters
Traditional technical analysis assumes fair, efficient markets. Reality: Markets have friction, manipulation, and information asymmetry. Microstructure filters detect when market structure indicates adverse conditions.
Filter 1: VPIN (Volume-Synchronized Probability of Informed Trading)
Theoretical Foundation: Easley, López de Prado, & O'Hara (2012). "Flow Toxicity and Liquidity in a High-Frequency World."
What It Measures: Probability that current order flow is "toxic" (informed traders with private information).
Calculation:
Classify volume as buy or sell (close > close = buy volume)
Calculate imbalance over 20 bars: VPIN = |Σ buy_volume - Σ sell_volume| / Σ total_volume
Compare to moving average: toxic = VPIN > VPIN_MA(20) × sensitivity
Interpretation:
VPIN < 0.3: Normal flow (uninformed retail)
VPIN 0.3-0.4: Elevated (smart money active)
VPIN > 0.4: Toxic flow (informed institutions dominant)
Filter Logic:
Block LONG when: VPIN toxic AND price rising (don't buy into institutional distribution)
Block SHORT when: VPIN toxic AND price falling (don't sell into institutional accumulation)
Adaptive Threshold: If VPIN toxic frequently, relax threshold; if rarely toxic, tighten threshold. Bounded .
Filter 2: Toxicity (Kyle's Lambda Approximation)
Theoretical Foundation: Kyle (1985). "Continuous Auctions and Insider Trading."
What It Measures: Price impact per unit volume — market depth and informed trading.
Calculation:
price_impact = (close - close ) / sqrt(Σ volume over 10 bars)
impact_zscore = (price_impact - impact_mean) / impact_std
toxicity = abs(impact_zscore)
Interpretation:
Low toxicity (<1.0): Deep liquid market, large orders absorbed easily
High toxicity (>2.0): Thin market or informed trading
Filter Logic: Block ALL SIGNALS when toxicity > threshold. Most dangerous when price breaks from VWAP with high toxicity.
Filter 3: Regime Filter (Counter-Trend Protection)
Purpose: Prevent counter-trend trades during strong trends.
Trend Scoring:
trend_score = 0
trend_score += close > EMA8 ? +1 : -1
trend_score += EMA8 > EMA21 ? +1 : -1
trend_score += EMA21 > EMA50 ? +1 : -1
trend_score += close > EMA200 ? +1 : -1
Range:
Regime Classification:
Strong Bull: trend_score ≥ +3 → Block all SHORT signals
Strong Bear: trend_score ≤ -3 → Block all LONG signals
Neutral: -2 ≤ trend_score ≤ +2 → Allow both directions
Filter 4: Liquidity Boost (Signal Enhancer)
Unique: Unlike other filters (which block), this amplifies signals during low liquidity.
Logic: if volume < vol_avg × 0.7: agent_scores × 1.2
Why It Works: Low liquidity often precedes explosive moves (breakouts). By increasing agent sensitivity during compression, system catches pre-breakout signals earlier.
Technical Implementation & Approximations
⚠️ Critical Approximations Required by Pine Script
1. Thompson Sampling: Pseudo-Random Beta Distribution
Academic Standard: True random sampling from beta distributions using cryptographic RNG
This Implementation: Box-Muller transform for normal distribution using market data (price/volume decimal digits) as entropy source, then scale to beta distribution mean/variance
Impact: Not cryptographically random, may have subtle biases in specific price ranges, but maintains correct mean and approximate variance. Sufficient for bandit agent selection.
2. VPIN: Simplified Volume Classification
Academic Standard: Lee-Ready algorithm or exchange-provided aggressor flags with tick-by-tick data
This Implementation: Bar-based classification: if close > close : buy_volume += volume
Impact: 10-15% precision loss. Works well in directional markets, misclassifies in choppy conditions. Still captures order flow imbalance signal.
3. Policy Gradient: Simplified Per-Action Updates
Academic Standard: Full softmax gradient updating all actions (selected action UP, others DOWN proportionally)
This Implementation: Only updates selected action's weights
Impact: Valid approximation for small action spaces (5 actions). Slower convergence than full softmax but still learns optimal policy.
4. Kyle's Lambda: Simplified Price Impact
Academic Standard: Regression over multiple time scales with signed order flow
This Implementation: price_impact = Δprice_10 / sqrt(Σvolume_10); z_score calculation
Impact: 15-20% precision loss. No proper signed order flow. Still detects informed trading signals at extremes (>2σ).
5. Other Simplifications:
Hawkes Process: Fixed exponential decay (0.9) not MLE-optimized
Entropy: Ratio approximation not true Shannon entropy H(X) = -Σ p(x)·log₂(p(x))
Feature Engineering: 12 features vs. potential 100+ with polynomial interactions
RL Hybrid Updates: Both online and terminal (non-standard but empirically effective)
Overall Precision Loss Estimate: 10-15% compared to academic implementations with institutional data feeds.
Practical Trade-off: For retail trading with OHLCV data, these approximations provide 90%+ of the edge while maintaining full transparency, zero latency, no external dependencies, and runs on any TradingView plan.
How to Use: Practical Guide
Initial Setup (5 Minutes)
Select Trading Mode: Start with "Balanced" for most users
Enable ML/RL System: Toggle to TRUE, select "Full Stack" ML Mode
Bandit Configuration: Algorithm: "Thompson Sampling", Mode: "Switch" or "Blend"
Microstructure Filters: Enable all four filters, enable "Adaptive Microstructure Thresholds"
Visual Settings: Enable dashboard (Top Right), enable all chart visuals
Learning Phase (First 50-100 Signals)
What To Monitor:
Agent Performance Table: Watch win rates develop (target >55%)
Bandit Weights: Should diverge from uniform (0.25 each) after 20-30 signals
RL Core Metrics: "RL Updates" should increase when position open
Filter Status: "Blocked" count indicates filter activity
Optimization Tips:
Too few signals: Lower min_confidence to 0.25, increase agent sensitivities to 1.1-1.2
Too many signals: Raise min_confidence to 0.35-0.40, decrease agent sensitivities to 0.8-0.9
One agent dominates (>70%): Consider "Lock Agent" feature
Signal Interpretation
Dashboard Signal Status:
⚪ WAITING FOR SIGNAL: No agent signaling
⏳ ANALYZING...: Agent signaling but not confirmed
🟡 CONFIRMING 2/3: Building confirmation (2 of 3 bars)
🟢 LONG ACTIVE : Validated long entry
🔴 SHORT ACTIVE : Validated short entry
Kill Zone Boxes: Entry price (triangle marker), Take Profit (Entry + 2.5× ATR), Stop Loss (Entry - 1.5× ATR). Risk:Reward = 1:1.67
Risk Management
Position Sizing:
Risk per trade = 1-2% of capital
Position size = (Capital × Risk%) / (Entry - StopLoss)
Stop-Loss Placement:
Initial: Entry ± 1.5× ATR (shown in kill zone)
Trailing: After 1:1 R:R achieved, move stop to breakeven
Take-Profit Strategy:
TP1 (2.5× ATR): Take 50% off
TP2 (Runner): Trail stop at 1× ATR or use opposite signal as exit
Memory Persistence
Why Save Memory: Every chart reload resets the system. Saving learned parameters preserves weeks of learning.
When To Save: After 200+ signals when agent weights stabilize
What To Save: From Memory Export panel, copy all alpha/beta/weight values and adaptive thresholds
How To Restore: Enable "Restore From Saved State", input all values into corresponding fields
What Makes This Original
Innovation 1: Genuine Multi-Armed Bandit Framework
This implements 15 mathematically rigorous bandit algorithms from academic literature (Thompson Sampling from Chapelle & Li 2011, UCB family from Auer et al. 2002, EXP3 from Auer et al. 2002, KL-UCB from Garivier & Cappé 2011). Each algorithm maintains proper state, updates according to proven theory, and converges to optimal behavior. This is real learning, not superficial parameter changes.
Innovation 2: Full Reinforcement Learning Stack
Beyond bandits learning which agent works best globally, RL learns which agent works best in each market state. After 500+ positions, system builds 54-state × 5-action value function (270 learned parameters) capturing context-dependent agent quality.
Innovation 3: Market Microstructure Integration
Combines retail technical analysis with institutional-grade microstructure metrics: VPIN from Easley, López de Prado, O'Hara (2012), Kyle's Lambda from Kyle (1985), Hawkes Processes from Hawkes (1971). These detect informed trading, manipulation, and liquidity dynamics invisible to technical analysis.
Innovation 4: Adaptive Threshold System
Dynamic quantile-based thresholds: Maintains histogram of each agent's score distribution (24 bins, exponentially decayed), calculates 80th percentile threshold from histogram. Agent triggers only when score exceeds its own learned quantile. Proper non-parametric density estimation automatically adapts to instrument volatility, agent behavior shifts, and market regime changes.
Innovation 5: Episodic Memory with Transfer Learning
Dual-layer architecture: Short-term memory (last 20 trades, fast adaptation) + Long-term memory (condensed episodes, historical patterns). Transfer mechanism consolidates knowledge when STM reaches threshold. Mimics hippocampus → neocortex consolidation in human memory.
Limitations & Disclaimers
General Limitations
No Predictive Guarantee: Pattern recognition ≠ prediction. Past performance ≠ future results.
Learning Period Required: Minimum 50-100 bars for reliable statistics. Initial performance may be suboptimal.
Overfitting Risk: System learns patterns in historical data. May not generalize to unprecedented conditions.
Approximation Limitations: See technical implementation section (10-15% precision loss vs. academic standards)
Single-Instrument Limitation: No multi-asset correlation, sector context, or VIX integration.
Forward-Looking Bias Disclaimer
CRITICAL TRANSPARENCY: The RL system uses an 8-bar forward-looking window for reward calculation.
What This Means: System learns from rewards incorporating future price information (bars 101-108 relative to entry at bar 100).
Why Acceptable:
✅ Signals do NOT look ahead: Entry decisions use only data ≤ entry bar
✅ Learning only: Forward data used for optimization, not signal generation
✅ Real-time mirrors backtest: In live trading, system learns identically
⚠️ Implication: Dashboard "Agent Win%" reflects this 8-bar evaluation. Real-time performance may differ slightly if positions held longer, slippage/fees not captured, or market microstructure changes.
Risk Warnings
No Guarantee of Profit: All trading involves risk of loss
System Failures: Bugs possible despite extensive testing
Market Conditions: Optimized for liquid markets (>100k daily volume). Performance degrades in illiquid instruments, major news events, flash crashes
Broker-Specific Issues: Execution slippage, commission/fees, overnight financing costs
Appropriate Use
This Indicator Is:
✅ Entry trigger system
✅ Risk management framework (stop/target)
✅ Adaptive agent selection engine
✅ Learning system that improves over time
This Indicator Is NOT:
❌ Complete trading strategy (requires position sizing, portfolio management)
❌ Replacement for fundamental analysis
❌ Guaranteed profit generator
❌ Suitable for complete beginners without training
Recommended Complementary Analysis: Market context (support/resistance), volume profile, fundamental catalysts, correlation with related instruments, broader market regime
Recommended Settings by Instrument
Stocks (Large Cap, >$1B):
Mode: Balanced | ML/RL: Enabled, Full Stack | Bandit: Thompson Sampling, Switch
Agent Sensitivity: Spoofing 1.0-1.2, Exhaustion 0.9-1.1, Liquidity 0.8-1.0, StatArb 1.1-1.3
Microstructure: All enabled, VPIN 1.2, Toxicity 1.5 | Timeframe: 15min-1H
Forex Majors (EURUSD, GBPUSD):
Mode: Balanced to Conservative | ML/RL: Enabled, Full Stack | Bandit: Thompson Sampling, Blend
Agent Sensitivity: Spoofing 0.8-1.0, Exhaustion 0.9-1.1, Liquidity 0.7-0.9, StatArb 1.2-1.5
Microstructure: All enabled, VPIN 1.0-1.1, Toxicity 1.3-1.5 | Timeframe: 5min-30min
Crypto (BTC, ETH):
Mode: Aggressive to Balanced | ML/RL: Enabled, Full Stack | Bandit: Thompson Sampling OR EXP3-IX
Agent Sensitivity: Spoofing 1.2-1.5, Exhaustion 1.1-1.3, Liquidity 1.2-1.5, StatArb 0.7-0.9
Microstructure: All enabled, VPIN 1.4-1.6, Toxicity 1.8-2.2 | Timeframe: 15min-4H
Futures (ES, NQ, CL):
Mode: Balanced | ML/RL: Enabled, Full Stack | Bandit: UCB1 or Thompson Sampling
Agent Sensitivity: All 1.0-1.2 (balanced)
Microstructure: All enabled, VPIN 1.1-1.3, Toxicity 1.4-1.6 | Timeframe: 5min-30min
Conclusion
Algorithm Predator - Pro synthesizes academic research from market microstructure theory, reinforcement learning, and multi-armed bandit algorithms. Unlike typical indicator mashups, this system implements 15 mathematically rigorous bandit algorithms, deploys a complete RL stack (Q-Learning, TD(λ), Policy Gradient), integrates institutional microstructure metrics (VPIN, Kyle's Lambda), adapts continuously through dual-layer memory and meta-learning, and provides full transparency on approximations and limitations.
The system is designed for serious algorithmic traders who understand that no indicator is perfect, but through proper machine learning, we can build systems that improve over time and adapt to changing markets without manual intervention.
Use responsibly. Risk disclosure applies. Past performance ≠ future results.
Taking you to school. — Dskyz, Trade with insight. Trade with anticipation.
