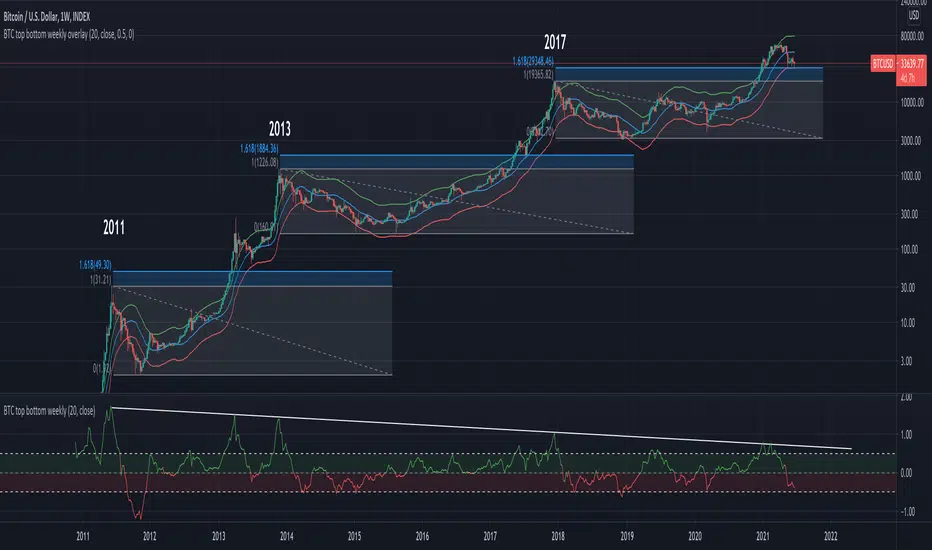
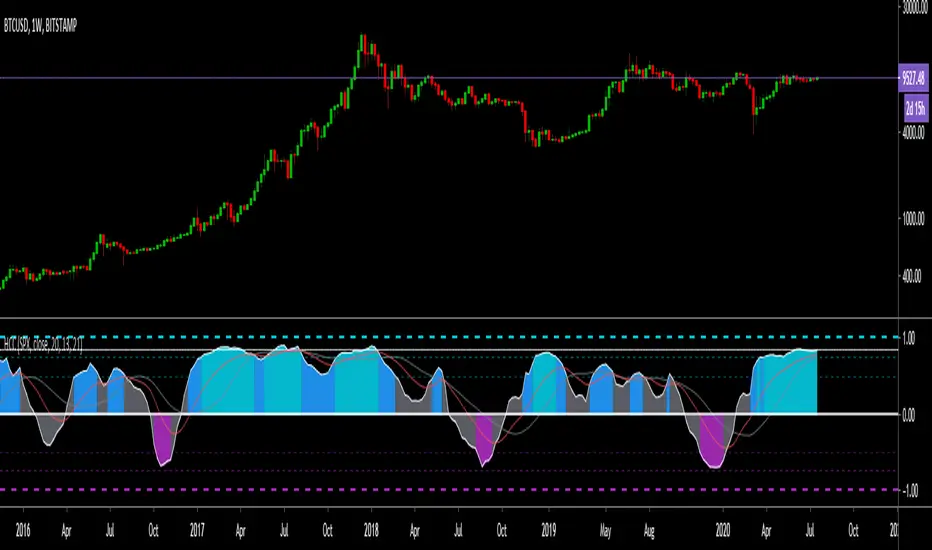
BTC top bottom weekly oscillatorThis indicator is based on the 20 weekly simple moving average and it could be used to help finding potential tops and bottoms on a weekly BTC chart.
This version uses an "oscillator" presentation, it fluctuates around the value zero.
The indicator plots 0 when the close price is near the 20 weekly moving average.
If it's below 0 it reflects the price being below the 20 weekly moving average, and opposite for above.
IT's possible to see how many times the price has hit the 0.5 coef support. In one case it hit 0.6 showing that the 0.5 support can be broken.
The indicator is calculated as Log(close / sma(close))
Instructions:
- Use with the symbol INDEX:BTCUSD so you can see the price since 2010
- Set the timeframe to weekly
Optionals:
- change the coef to 0.6 for a more conservative bottom
- change the coef to 0.4 for a more conservative top
Buscar en scripts para "通达信+选股公式+换手率+0.5+源码"
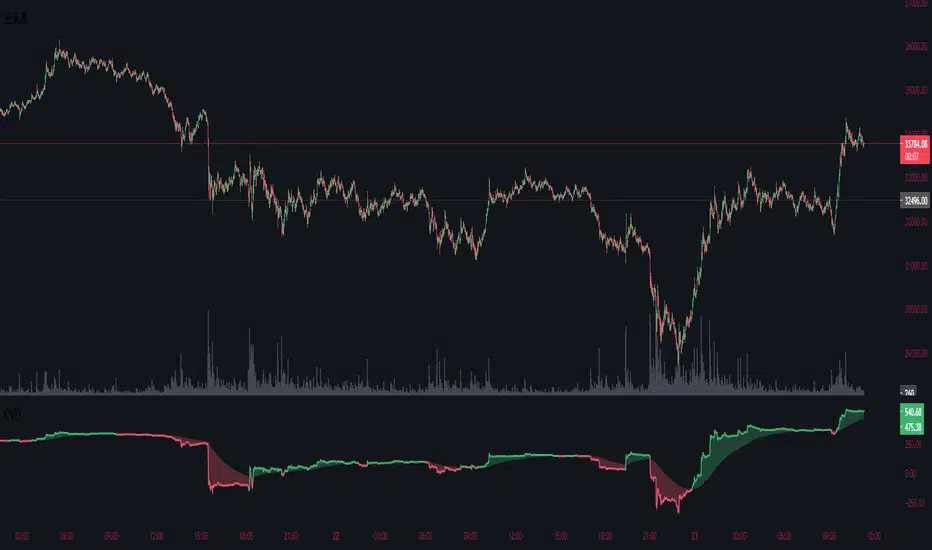
Cumulative Volume DeltaThis indicator is called Cumulative Volume Delta (CVD), and it is the cumulative difference between buying and selling pressure.
Note, however, that it is not an exact CVD, because Pine Script does not allow you to get the Bid Volume and Ask Volume.
Instead, it uses volume and candlestick length to determine the pressure.
Example: Volume is 100, price change is +1.0% → Buying pressure is 1
Volume is 100, price change is -0.5% → Selling pressure is 0.5
このインジケーターは、Cumulative Volume Delta(CVD)と呼ばれるもので、買い圧力と売り圧力の差を累積したものです。
しかし、Pine Scriptでは買い圧力と売り圧力(Bid VolumeとAsk Volume)を取得することはできないため、正確なCVDではないことに注意してください。
代わりに出来高とローソク足の長さで圧力を判断判断しています。
例:出来高が100、価格の変動が+1.0% → 買い圧力は1
出来高が100、価格の変動が-0.5% → 売り圧力は0.5
[blackcat] L2 Ehlers Adaptive Jon Andersen R-Squared IndicatorLevel: 2
Background
@pips_v1 has proposed an interesting idea that is it possible to code an "Adaptive Jon Andersen R-Squared Indicator" where the length is determined by DCPeriod as calculated in Ehlers Sine Wave Indicator? I agree with him and starting to construct this indicator. After a study, I found "(blackcat) L2 Ehlers Autocorrelation Periodogram" script could be reused for this purpose because Ehlers Autocorrelation Periodogram is an ideal candidate to calculate the dominant cycle. On the other hand, there are two inputs for R-Squared indicator:
Length - number of bars to calculate moment correlation coefficient R
AvgLen - number of bars to calculate average R-square
I used Ehlers Autocorrelation Periodogram to produced a dynamic value of "Length" of R-Squared indicator and make it adaptive.
Function
One tool available in forecasting the trendiness of the breakout is the coefficient of determination (R-squared), a statistical measurement. The R-squared indicates linear strength between the security's price (the Y - axis) and time (the X - axis). The R-squared is the percentage of squared error that the linear regression can eliminate if it were used as the predictor instead of the mean value. If the R-squared were 0.99, then the linear regression would eliminate 99% of the error for prediction versus predicting closing prices using a simple moving average.
When the R-squared is at an extreme low, indicating that the mean is a better predictor than regression, it can only increase, indicating that the regression is becoming a better predictor than the mean. The opposite is true for extreme high values of the R-squared.
To make this indicator adaptive, the dominant cycle is extracted from the spectral estimate in the next block of code using a center-of-gravity ( CG ) algorithm. The CG algorithm measures the average center of two-dimensional objects. The algorithm computes the average period at which the powers are centered. That is the dominant cycle. The dominant cycle is a value that varies with time. The spectrum values vary between 0 and 1 after being normalized. These values are converted to colors. When the spectrum is greater than 0.5, the colors combine red and yellow, with yellow being the result when spectrum = 1 and red being the result when the spectrum = 0.5. When the spectrum is less than 0.5, the red saturation is decreased, with the result the color is black when spectrum = 0.
Construction of the autocorrelation periodogram starts with the autocorrelation function using the minimum three bars of averaging. The cyclic information is extracted using a discrete Fourier transform (DFT) of the autocorrelation results. This approach has at least four distinct advantages over other spectral estimation techniques. These are:
1. Rapid response. The spectral estimates start to form within a half-cycle period of their initiation.
2. Relative cyclic power as a function of time is estimated. The autocorrelation at all cycle periods can be low if there are no cycles present, for example, during a trend. Previous works treated the maximum cycle amplitude at each time bar equally.
3. The autocorrelation is constrained to be between minus one and plus one regardless of the period of the measured cycle period. This obviates the need to compensate for Spectral Dilation of the cycle amplitude as a function of the cycle period.
4. The resolution of the cyclic measurement is inherently high and is independent of any windowing function of the price data.
Key Signal
DC --> Ehlers dominant cycle.
AvgSqrR --> R-squared output of the indicator.
Remarks
This is a Level 2 free and open source indicator.
Feedbacks are appreciated.

Pinescript - Common Label & Line Array Functions Library by RRBPinescript - Common Label & Line Array Functions Library by RagingRocketBull 2021
Version 1.0
This script provides a library of common array functions for arrays of label and line objects with live testing of all functions.
Using this library you can easily create, update, delete, join label/line object arrays, and get/set properties of individual label/line object array items.
You can find the full list of supported label/line array functions below.
There are several libraries:
- Common String Functions Library
- Standard Array Functions Library
- Common Fixed Type Array Functions Library
- Common Label & Line Array Functions Library
- Common Variable Type Array Functions Library
Features:
- 30 array functions in categories create/update/delete/join/get/set with support for both label/line objects (45+ including all implementations)
- Create, Update label/line object arrays from list/array params
- GET/SET properties of individual label/line array items by index
- Join label/line objects/arrays into a single string for output
- Supports User Input of x,y coords of 5 different types: abs/rel/rel%/inc/inc% list/array, auto transforms x,y input into list/array based on type, base and xloc, translates rel into abs bar indexes
- Supports User Input of lists with shortened names of string properties, auto expands all standard string properties to their full names for use in functions
- Live Output for all/selected functions based on User Input. Test any function for possible errors you may encounter before using in script.
- Output filters: hide all excluded and show only allowed functions using a list of function names
- Output Panel customization options: set custom style, color, text size, and line spacing
Usage:
- select create function - create label/line arrays from lists or arrays (optional). Doesn't affect the update functions. The only change in output should be function name regardless of the selected implementation.
- specify num_objects for both label/line arrays (default is 7)
- specify common anchor point settings x,y base/type for both label/line arrays and GET/SET items in Common Settings
- fill lists with items to use as inputs for create label/line array functions in Create Label/Line Arrays section
- specify label/line array item index and properties to SET in corresponding sections
- select label/line SET function to see the changes applied live
Code Structure:
- translate x,y depending on x,y type, base and xloc as specified in UI (required for all functions)
- expand all shortened standard property names to full names (required for create/update* from arrays and set* functions, not needed for create/update* from lists) to prevent errors in label.new and line.new
- create param arrays from string lists (required for create/update* from arrays and set* functions, not needed for create/update* from lists)
- create label/line array from string lists (property names are auto expanded) or param arrays (requires already expanded properties)
- update entire label/line array or
- get/set label/line array item properties by index
Transforming/Expanding Input values:
- for this script to work on any chart regardless of price/scale, all x*,y* are specified as % increase relative to x0,y0 base levels by default, but user can enter abs x,price values specific for that chart if necessary.
- all lists can be empty, contain 1 or several items, have the same/different lengths. Array Length = min(min(len(list*)), mum_objects) is used to create label/line objects. Missing list items are replaced with default property values.
- when a list contains only 1 item it is duplicated (label name/tooltip is also auto incremented) to match the calculated Array Length
- since this script processes user input, all x,y values must be translated to abs bar indexes before passing them to functions. Your script may provide all data internally and doesn't require this step.
- at first int x, float y arrays are created from user string lists, transformed as described below and returned as x,y arrays.
- translated x,y arrays can then be passed to create from arrays function or can be converted back to x,y string lists for the create from lists function if necessary.
- all translation logic is separated from create/update/set functions for the following reasons:
- to avoid redundant code/dependency on ext functions/reduce local scopes and to be able to translate everything only once in one place - should be faster
- to simplify internal logic of all functions
- because your script may provide all data internally without user input and won't need the translation step
- there are 5 types available for both x,y: abs, rel, rel%, inc, inc%. In addition to that, x can be: bar index or time, y is always price.
- abs - absolute bar index/time from start bar0 (x) or price (y) from 0, is >= 0
- rel - relative bar index/time from cur bar n (x) or price from y0 base level, is >= 0
- rel% - relative % increase of bar index/time (x) or price (y) from corresponding base level (x0 or y0), can be <=> 0
- inc - relative increment (step) for each new level of bar index/time (x) or price (y) from corresponding base level (x0 or y0), can be <=> 0
- inc% - relative % increment (% step) for each new level of bar index/time (x) or price (y) from corresponding base level (x0 or y0), can be <=> 0
- x base level >= 0
- y base level can be 0 (empty) or open, close, high, low of cur bar
- single item x1_list = "50" translates into:
- for x type abs: "50, 50, 50 ..." num_objects times regardless of xloc => x = 50
- for x type rel: "50, 50, 50 ... " num_objects times => x = x_base + 50
- for x type rel%: "50%, 50%, 50% ... " num_objects times => x_base * (1 + 0.5)
- for x type inc: "0, 50, 100 ... " num_objects times => x_base + 50 * i
- for x type inc%: "0%, 50%, 100% ... " num_objects times => x_base * (1 + 0.5 * i)
- when xloc = xloc.bar_index each rel*/inc* value in the above list is then subtracted from n: n - x to convert rel to abs bar index, values of abs type are not affected
- x1_list = "0, 50, 100, ..." of type rel is the same as "50" of type inc
- x1_list = "50, 50, 50, ..." of type abs/rel/rel% produces a sequence of the same values and can be shortened to just "50"
- single item y1_list = "2" translates into (ragardless of yloc):
- for y type abs: "2, 2, 2 ..." num_objects times => y = 2
- for y type rel: "2, 2, 2 ... " num_objects times => y = y_base + 2
- for y type rel%: "2%, 2%, 2% ... " num_objects times => y = y_base * (1 + 0.02)
- for y type inc: "0, 2, 4 ... " num_objects times => y = y_base + 2 * i
- for y type inc%: "0%, 2%, 4% ... " num_objects times => y = y_base * (1 + 0.02 * i)
- when yloc != yloc.price all calculated values above are simply ignored
- y1_list = "0, 2, 4" of type rel% is the same as "2" with type inc%
- y1_list = "2, 2, 2" of type abs/rel/rel% produces a sequence of the same values and can be shortened to just "2"
- you can enter shortened property names in lists. To lookup supported shortened names use corresponding dropdowns in Set Label/Line Array Item Properties sections
- all shortened standard property names must be expanded to full names (required for create/update* from arrays and set* functions, not needed for create/update* from lists) to prevent errors in label.new and line.new
- examples of shortened property names that can be used in lists: bar_index, large, solid, label_right, white, left, left, price
- expanded to their corresponding full names: xloc.bar_index, size.large, line.style_solid, label.style_label_right, color.white, text.align_left, extend.left, yloc.price
- all expanding logic is separated from create/update* from arrays and set* functions for the same reasons as above, and because param arrays already have different types, implying the use of final values.
- all expanding logic is included in the create/update* from lists functions because it seemed more natural to process string lists from user input directly inside the function, since they are already strings.
Creating Label/Line Objects:
- use study max_lines_count and max_labels_count params to increase the max number of label/line objects to 500 (+3) if necessary. Default number of label/line objects is 50 (+3)
- all functions use standard param sequence from methods in reference, except style always comes before colors.
- standard label/line.get* functions only return a few properties, you can't read style, color, width etc.
- label.new(na, na, "") will still create a label with x = n-301, y = NaN, text = "" because max default scope for a var is 300 bars back.
- there are 2 types of color na, label color requires color(na) instead of color_na to prevent error. text_color and line_color can be color_na
- for line to be visible both x1, x2 ends must be visible on screen, also when y1 == y2 => abs(x1 - x2) >= 2 bars => line is visible
- xloc.bar_index line uses abs x1, x2 indexes and can only be within 0 and n ends, where n <= 5000 bars (free accounts) or 10000 bars (paid accounts) limit, can't be plotted into the future
- xloc.bar_time line uses abs x1, x2 times, can't go past bar0 time but can continue past cur bar time into the future, doesn't have a length limit in bars.
- xloc.bar_time line with length = exact number of bars can be plotted only within bar0 and cur bar, can't be plotted into the future reliably because of future gaps due to sessions on some charts
- xloc.bar_index line can't be created on bar 0 with fixed length value because there's only 1 bar of horiz length
- it can be created on cur bar using fixed length x < n <= 5000 or
- created on bar0 using na and then assigned final x* values on cur bar using set_x*
- created on bar0 using n - fixed_length x and then updated on cur bar using set_x*, where n <= 5000
- default orientation of lines (for style_arrow* and extend) is from left to right (from bar 50 to bar 0), it reverses when x1 and x2 are swapped
- price is a function, not a line object property
Variable Type Arrays:
- you can't create an if/function that returns var type value/array - compiler uses strict types and doesn't allow that
- however you can assign array of any type to another array of any type creating an arr pointer of invalid type that must be reassigned to a matching array type before used in any expression to prevent error
- create_any_array2 uses this loophole to return an int_arr pointer of a var type array
- this works for all array types defined with/without var keyword and doesn't work for string arrays defined with var keyword for some reason
- you can't do this with var type vars, only var type arrays because arrays are pointers passed by reference, while vars are actual values passed by value.
- you can only pass a var type value/array param to a function if all functions inside support every type - otherwise error
- alternatively values of every type must be passed simultaneously and processed separately by corresponding if branches/functions supporting these particular types returning a common single type result
- get_var_types solves this problem by generating a list of dummy values of every possible type including the source type, tricking the compiler into allowing a single valid branch to execute without error, while ignoring all dummy results
Notes:
- uses Pinescript v3 Compatibility Framework
- uses Common String Functions Library, Common Fixed Type Array Functions Library, Common Variable Type Array Functions Library
- has to be a separate script to reduce the number of local scopes/compiled file size, can't be merged with another library.
- lets you live test all label/line array functions for errors. If you see an error - change params in UI
- if you see "Loop too long" error - hide/unhide or reattach the script
- if you see "Chart references too many candles" error - change x type or value between abs/rel*. This can happen on charts with 5000+ bars when a rel bar index x is passed to label.new or line.new instead of abs bar index n - x
- create/update_label/line_array* use string lists, while create/update_label/line_array_from_arrays* use array params to create label/line arrays. "from_lists" is dropped to shorten the names of the most commonly used functions.
- create_label/line_array2,4 are preferable, 5,6 are listed for pure demonstration purposes only - don't use them, they don't improve anything but dramatically increase local scopes/compiled file size
- for this reason you would mainly be using create/update_label/line_array2,4 for list params or create/update_label/line_array_from_arrays2 for array params
- all update functions are executed after each create as proof of work and can be disabled. Only create functions are required. Use update functions when necessary - when list/array params are changed by your script.
- both lists and array item properties use the same x,y_type, x,y_base from common settings
- doesn't use pagination, a single str contains all output
- why is this so complicated? What are all these functions for?
- this script merges standard label/line object methods with standard array functions to create a powerful set of label/line object array functions to simplify manipulation of these arrays.
- this library also extends the functionality of Common Variable Type Array Functions Library providing support for label/line types in var type array functions (any_to_str6, join_any_array5)
- creating arrays from either lists or arrays adds a level of flexibility that comes with complexity. It's very likely that in your script you'd have to deal with both string lists as input, and arrays internally, once everything is converted.
- processing user input, allowing customization and targeting for any chart adds a whole new layer of complexity, all inputs must be translated and expanded before used in functions.
- different function implementations can increase/reduce local scopes and compiled file size. Select a version that best suits your needs. Creating complex scripts often requires rewriting your code multiple times to fit the limits, every line matters.
P.S. Don't rely too much on labels, for too often they are fables.
List of functions*:
* - functions from other libraries are not listed
1. Join Functions
Labels
- join_label_object(label_, d1, d2)
- join_label_array(arr, d1, d2)
- join_label_array2(arr, d1, d2, d3)
Lines
- join_line_object(line_, d1, d2)
- join_line_array(arr, d1, d2)
- join_line_array2(arr, d1, d2, d3)
Any Type
- any_to_str6(arr, index, type)
- join_any_array4(arr, d1, d2, type)
- join_any_array5(arr, d, type)
2. GET/SET Functions
Labels
- label_array_get_text(arr, index)
- label_array_get_xy(arr, index)
- label_array_get_fields(arr, index)
- label_array_set_text(arr, index, str)
- label_array_set_xy(arr, index, x, y)
- label_array_set_fields(arr, index, x, y, str)
- label_array_set_all_fields(arr, index, x, y, str, xloc, yloc, label_style, label_color, text_color, text_size, text_align, tooltip)
- label_array_set_all_fields2(arr, index, x, y, str, xloc, yloc, label_style, label_color, text_color, text_size, text_align, tooltip)
Lines
- line_array_get_price(arr, index, bar)
- line_array_get_xy(arr, index)
- line_array_get_fields(arr, index)
- line_array_set_text(arr, index, width)
- line_array_set_xy(arr, index, x1, y1, x2, y2)
- line_array_set_fields(arr, index, x1, y1, x2, y2, width)
- line_array_set_all_fields(arr, index, x1, y1, x2, y2, xloc, extend, line_style, line_color, width)
- line_array_set_all_fields2(arr, index, x1, y1, x2, y2, xloc, extend, line_style, line_color, width)
3. Create/Update/Delete Functions
Labels
- delete_label_array(label_arr)
- create_label_array(list1, list2, list3, list4, list5, d)
- create_label_array2(x_list, y_list, str_list, xloc_list, yloc_list, style_list, color1_list, color2_list, size_list, align_list, tooltip_list, d)
- create_label_array3(x_list, y_list, str_list, xloc_list, yloc_list, style_list, color1_list, color2_list, size_list, align_list, tooltip_list, d)
- create_label_array4(x_list, y_list, str_list, xloc_list, yloc_list, style_list, color1_list, color2_list, size_list, align_list, tooltip_list, d)
- create_label_array5(x_list, y_list, str_list, xloc_list, yloc_list, style_list, color1_list, color2_list, size_list, align_list, tooltip_list, d)
- create_label_array6(x_list, y_list, str_list, xloc_list, yloc_list, style_list, color1_list, color2_list, size_list, align_list, tooltip_list, d)
- update_label_array2(label_arr, x_list, y_list, str_list, xloc_list, yloc_list, style_list, color1_list, color2_list, size_list, align_list, tooltip_list, d)
- update_label_array4(label_arr, x_list, y_list, str_list, xloc_list, yloc_list, style_list, color1_list, color2_list, size_list, align_list, tooltip_list, d)
- create_label_array_from_arrays2(x_arr, y_arr, str_arr, xloc_arr, yloc_arr, style_arr, color1_arr, color2_arr, size_arr, align_arr, tooltip_arr, d)
- create_label_array_from_arrays4(x_arr, y_arr, str_arr, xloc_arr, yloc_arr, style_arr, color1_arr, color2_arr, size_arr, align_arr, tooltip_arr, d)
- update_label_array_from_arrays2(label_arr, x_arr, y_arr, str_arr, xloc_arr, yloc_arr, style_arr, color1_arr, color2_arr, size_arr, align_arr, tooltip_arr, d)
Lines
- delete_line_array(line_arr)
- create_line_array(list1, list2, list3, list4, list5, list6, d)
- create_line_array2(x1_list, y1_list, x2_list, y2_list, xloc_list, extend_list, style_list, color_list, width_list, d)
- create_line_array3(x1_list, y1_list, x2_list, y2_list, xloc_list, extend_list, style_list, color_list, width_list, d)
- create_line_array4(x1_list, y1_list, x2_list, y2_list, xloc_list, extend_list, style_list, color_list, width_list, d)
- create_line_array5(x1_list, y1_list, x2_list, y2_list, xloc_list, extend_list, style_list, color_list, width_list, d)
- create_line_array6(x1_list, y1_list, x2_list, y2_list, xloc_list, extend_list, style_list, color_list, width_list, d)
- update_line_array2(line_arr, x1_list, y1_list, x2_list, y2_list, xloc_list, extend_list, style_list, color_list, width_list, d)
- update_line_array4(line_arr, x1_list, y1_list, x2_list, y2_list, xloc_list, extend_list, style_list, color_list, width_list, d)
- create_line_array_from_arrays2(x1_arr, y1_arr, x2_arr, y2_arr, xloc_arr, extend_arr, style_arr, color_arr, width_arr, d)
- update_line_array_from_arrays2(line_arr, x1_arr, y1_arr, x2_arr, y2_arr, xloc_arr, extend_arr, style_arr, color_arr, width_arr, d)
72s Strat: Backtesting Adaptive HMA+ pt.1This is a follow up to my previous publication of Adaptive HMA+ few months ago, as a mean to provide some kind of initial backtesting tools. Which can be use to explore many possible strategies, optimise its settings to better conform user's pair/tf, and hopefully able to help tweaking your general strategy.
If you haven't read the study or use the indicator, kindly go here first to get the overall idea.
The first strategy introduce in this backtest is one most basic already described in the study; buy/sell is when movement is there and everything is on the right side; When RSI has turned to other side, we can use it as exit point (if in profit of course, else just let it hit our TP/SL, why would we exit before profit). Also, base on RSI when we make entry, we can further differentiate type of signals. --Please check all comments in code directly where the signals , entries , and exits section are.
Second additional strategy to check; is when we also use second faster Adaptive HMA+ for exit. So this is like a double orders on a signal but with different exit-rule (/more on this on snapshots below). Alternatively, you can also work the code so to only use this type of exit.
There's also an additional feature which you can enable its visuals, the Distance Zone , is to help measuring price distance to our xHMA+. It's just a simple atr based envelope really, I already put the sample code in study's comment section, but better gonna update it there directly for non-coder too, after this.
In this sample I use Lot for order quantity size just because that's what I use on my broker. Also what few friends use while we forward-testing it since the study is published, so we also checked/compared each profit/loss report by real number. To use default or other unit of measurement, change the entry code accordingly.
If you change your order size, you should also change the commission in Properties Tab. My broker commission is 5 USD per order/lot, so in there with example order size 0.1 lot I put commission 0.5$ per order (I'll put 2.5$ for 0.5 lot, 10$ for 2 lot, and so on). Crypto usually has higher charge. --It is important that you should fill it base on your broker.
SETTINGS
I'm trying to keep it short. Please explore it further again. (Beginner should also first get acquaintance with terms use here.)
ORDERS:
Base Minimum Profit Before Exit:
The number is multiplier of ongoing ATR. Means that when basic exit condition is met, algo will check whether you're already in minimum profit or not, if not, let it still run to TP or SL, or until it meets subsequent exit condition, then it will check again.
Default Target Profit:
Multiplier of ATR at signal. If reached before any eligible exit condition is met, exit TP.
Base StopLoss Point:
You can change directly in code to use other like ATR Trailing SL, fix percent SL, or whatever. In the sample, 4 options provided.
Maximum StopLoss:
This is like a safety-net, that if at some point your chosen SL point from input above happens to be exceeding this maximum input that you can tolerate, then this max point is the one will be use as SL.
Activate 2nd order...:
The additional doubling of certain buy/sell with different exits as described above. If enable, you should also set pyramiding to at least: 2. If not, it does nothing.
ADAPTIVE HMA+ PERIOD
Many users already have their own settings for these. So in here I only sample the default as first presented in the study. Make it to your adaptive.
MARKET MOVEMENT
(1) Now you can check in realtime how much slope degree is best to define your specific pair/tf is out of congestion (yellow) area. And (2) also able to check directly what ATR lengths are more suitable defining your pair's volatility.
DISTANCE ZONE
Distance Multiplier. Each pair/tf has its own best distance zone (in xHMA+ perspective). The zone also determine whether a signal should appear or not. (Or what type of signal, if you wanna go more detail in constructing your strategy)
USAGE
(Provided you already have your own comfortable settings for minimum-maximum period of Adaptive HMA+. Best if you already have backtested it manually too and/or apply as an add-on to your working strategy)
1. In our experiences, first most important to define is both elements in the Market Movement Settings . These also tend to be persistent for whole season since it's kinda describing that pair/tf overall behaviour. Don't worry if you still get a low Profit Factor here, but by tweaking you should start to see positive changes in one of Max Drawdown and Net Profit, or Percent Profitable.
2. Afterwards, find your pair/tf Distance Zone . When optimising this, what we seek is just a "not to bad" equity curves to start forming. At least Max Drawdown should lessen more. Doesn't have to be great already, but should be better, no red in Net Profit.
3. Then go manage the "Trailing Minimum Profit", TP, SL, and max SL.
4. Repeat 1,2,3. 👻
5. Manage order size, commission, and/or enable double-order (need pyramiding) if you like. Check if your equity can handle max drawdown before margin call.
6. After getting an acceptable backtest result, go to List of Trades tab and find the biggest loss or when many sequencing loss in a row happened. Click on it to go to exact point on chart, observe why the signal failed and get at least general idea how it can be prevented . The rest is yours, you should know your pair/tf more than other.
You can also re-explore your minimum-maximum period for both Major and minor xHMA+.
Keep in mind that all numbers in Setting are conceptually in a form of range . You don't want to get superb equity curves but actually a "fragile" , means one can easily turn it to disaster just by changing only a fraction in one/two of the setting.
---
If you just wanna test the strength of the indicator alone, you can disable "Use StopLoss" temporarily while optimising settings.
Using no SL might be tempting in overall result data in some cases, but NOTE: It is not recommended to not using SL, don't forget that we deliberately enter when it's in high volatility. If want to add flexibility or trading for long-term, just maximise your SL. ie.: chose SL Point>ATR only and set it maximum. (Check your max drawdown after this).
I think this is quite important specially for beginners, so here's an example; Hypothetically in below scenario, because of some settings, the buy order after the loss sell signal didn't appear. Let's say if our initial capital only 1000$ using leverage and order size 0,5 lot (risky position sizing already), moreover if this happens at the beginning of your trading season, that's half of account gone already in one trade . Your max SL should've made you exit after that pumping bar.
The Trailing Minimum Profit is actually look like this. Search in the code if you want to plot it. I just don't like too many lines on chart.
To maximise profit we can try enabling double-order. The only added rule coded is: RSI should rising when buy and falling when sell. 2nd signal will appears above or below default buy/sell signal. (Of course it's also prone to double-loss, re-check your max drawdown after. Profit factor play its part in here for a long run). Snapshot in comparison:
Two default sell signals on left closed at RSI exit, the additional sell signal closed later on when price crossover minor xHMA+. On buy side, price haven't met our minimum profit when first crossunder minor xHMA+. If later on we hit SL on this "+buy" signal, at least we already profited from default buy signal. You can also consider/treat this as multiple TP points.
For longer-term trading, what you need to maximise is the Minimum Profit , so it won't exit whenever an exit condition happened, it can happen several times before reaching minimum profit. Hopefully this snapshot can explain:
Notice in comparison default sell and buy signal now close in average after 3 days. What's best is when we also have confirmation from higher TF. It's like targeting higher TF by entering from smaller TF.
As also mention in the study, we can still experiment via original HMA by putting same value for minimum-maximum period setting. This is experimental EU 1H with Major xHMA+: 144-144, Flat market 13, Distance multiplier 3.6, with 2nd order activated.
Kiwi was a bit surprising for me. It's flat market is effectively below 6, with quite far distance zone of 3.5. Probably because I'm using big numbers in adaptive period.
---
The result you see in strategy tester report below for EURUSD 15m is using just default settings you see in code, as follow:
0,1 lot for each order (which is the smallest allowed by my broker).
No pyramiding. Commission: 0.5 usd per order. Slippage: 3
Opening position is only using basic strategy #1 (RSI exit). Additional exit not activated.
Minimum Profit: 1. TP: 3.
SL use: Half-distance zone. Max SL: 4.5.
Major xHMA+: 172-233. minor xHMA+: 89-121
Distance Zone Multiplier: 2.7
RSI: Standard 14.
(From our forward-testing, the difference we get from net profit is because of the spread, our entry isn't exactly at the close/open price. Not so much though, but not the same. If somebody can direct me to any example where we can code our entry via current bid/ask price, that would be awesome!)
It's already a long post (sorry), think I'm gonna pause here. Check out the code :)
---
DISCLAIMER: Past performance is no guarantee of future results , and so on.. you know the drill ;)
Please read whole description first before using, don't take 1-2 paragraph and claim it's the whole logic, you are responsible of your own actions and understanding.

Hurst ExponentMy first try to implement Full Hurst Exponent.
The Hurst exponent is used as a measure of long-term memory of time series. It relates to the autocorrelations of the time series and the rate at which these decrease as the lag between pairs of values increases
The Hurst exponent is referred to as the "index of dependence" or "index of long-range dependence". It quantifies the relative tendency of a time series either to regress strongly to the mean or to cluster in a direction.
In short, depending on the value you can spot the trending / reversing market.
Values 0.5 to 1 - market trending
Values 0 to 0.5 - market tend to mean revert
Hurst Exponent is computed using Rescaled range (R/S) analysis.
I split the lookback period (N) in the number of shorter samples (for ex. N/2, N/4, N/8, etc.). Then I calculate rescaled range for each sample size.
The Hurst exponent is estimated by fitting the power law. Basically finding the slope of log(samples_size) to log(RS).
You can choose lookback and sample sizes yourself. Max 8 possible at the moment, if you want to use less use 0 in inputs.
It's pretty computational intensive, so I added an input so you can limit from what date you want it to be calculated. If you hit the time limit in PineScript - limit the history you're using for calculations.
####################
Disclaimer
Please remember that past performance may not be indicative of future results.
Due to various factors, including changing market conditions, the strategy may no longer perform as good as in historical backtesting.
This post and the script don’t provide any financial advice.

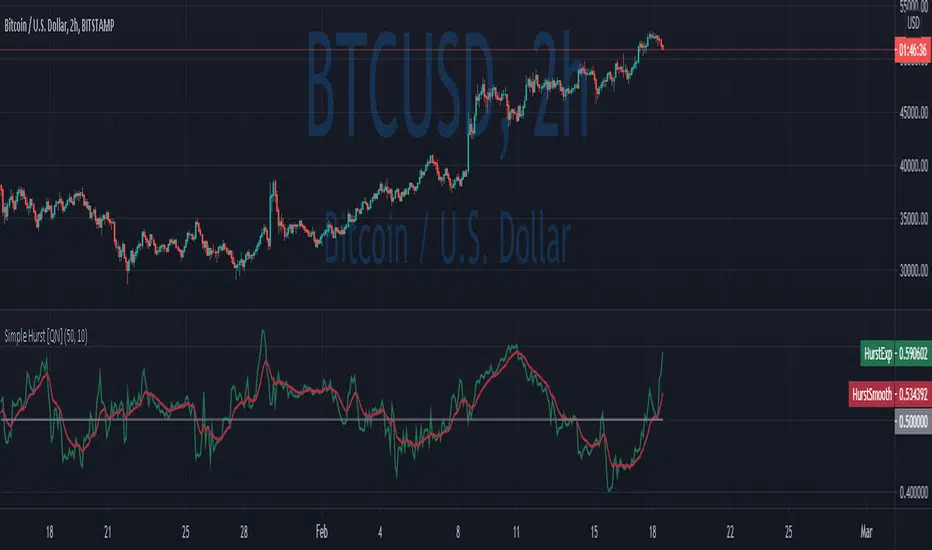
Simple Hurst Exponent [QuantNomad]This is a simplified version of the Hurst Exponent indicator.
In the meantime, I'm working on the full version. It's computationally intensive, so it's a challenge to squeeze it to PineScript limits. It will require some time to optimize it, so I decided to publish a simplified version for now.
The Hurst exponent is used as a measure of long-term memory of time series. It relates to the autocorrelations of the time series, and the rate at which these decrease as the lag between pairs of values increases
The Hurst exponent is referred to as the "index of dependence" or "index of long-range dependence". It quantifies the relative tendency of a time series either to regress strongly to the mean or to cluster in a direction.
In short depend on value you can spot trending / reversing market.
Values 0.5 to 1 - market trending
Values 0 to 0.5 - market tend to mean revert
####################
Disclaimer
Please remember that past performance may not be indicative of future results.
Due to various factors, including changing market conditions, the strategy may no longer perform as good as in historical backtesting.
This post and the script don’t provide any financial advice.
Pin Bar CandlesPinbar Identification.
One must apply Fibonacchi extension 0,0.5,1,2, 3, 4.
0 being SL
1 Being Entry
0.5 Being 2nd Entry.
4 Being target.
Use this to enter trade near crucial levels only.

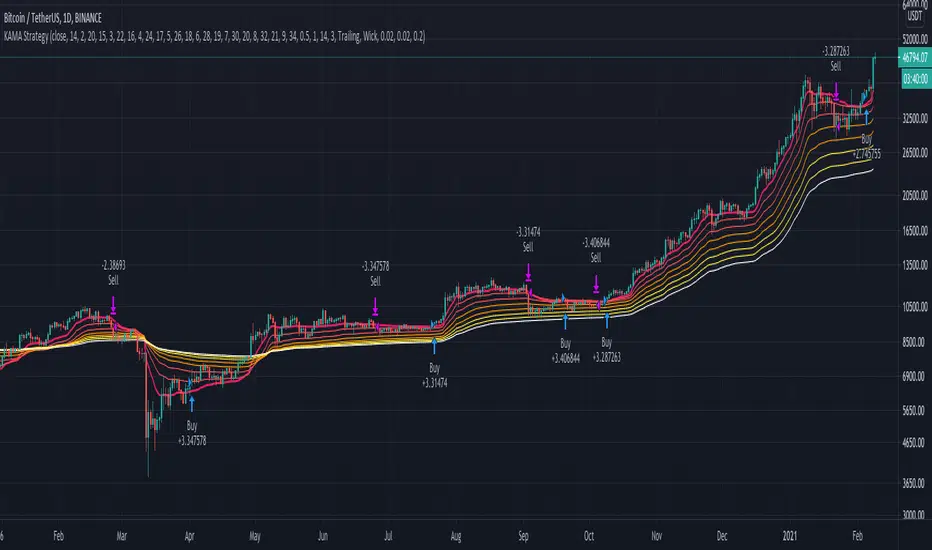
KAMA Strategy - Kaufman's Adaptive Moving AverageThis strategy combines Kaufman's Adaptive Moving Average for entry with optional KAMA, PSAR, and Trailing ATR stops for exits.
Kaufman's Adaptive Moving Average is, in my opinion, a gem among the plethora of indicators. It is underrated considering it offers a solution that intuitively makes a lot of sense. When I first read about it, it was a real 'aha!' moment. Look at the top, pink line. Notice how during trending times it follows the trend quickly and closely, but during choppy, non-trending periods, the KAMA stays absolutely flat? Interesting! To trade with it, we simply follow the direction the KAMA is pointing. Is it up? Go long. Is it down? Go short. Is it flat? Hold on.
How does it manage to quickly follow real trends like a fast EMA but ignore choppy conditions that would whipsaw a fast EMA back and forth? It analyses whether recent price moves are significant relative to recent noise and then adapts the length of the EMA window accordingly. If price movement is big compared to the recent noise, the EMA window gets smaller. If price movement is relatively small or average compared to the recent noise, the EMA window gets bigger. In practice it means:
The KAMA would be flat if a 20 point upwards move occurred during a period that has had, on average, regular 20 point moves BUT
the KAMA would point up if a 20 point move occurred during a period that has, on average, had moves of only around 5 points.
In other words, it's a slow EMA during choppy flat / quiet flat periods, and a fast EMA as soon as significant volatility occurs. Perfect!
-----
The Strategy
The strategy is more than just a KAMA indicator. It contains:
KAMA exit (optional)
ATR trailing stop loss exit (optional)
PSAR stop loss exit (optional)
KAMA filter for entry and exits
All features are adjustable in the strategy settings
The Technical Details:
Check out the strategy's 'Inputs' panel. The buy and sell signals are based on the 'KAMA 1' there.
KAMA 1: Length -- 14 is the default. This is the length of the window the KAMA looks back over. In this instance, it c
KAMA 1: Fast KAMA Length -- 2 is the default. This is the tightest the EMA length is allowed to get. It will tend towards this length when volatility is high.
KAMA 1: Slow KAMA Length -- 20 is the default. This is the biggest the EMA length is allowed to get. It will tend towards this length when volatility is low.
KAMA Filter
The strategy buys when the KAMA begins to point up and sells when the KAMA points down. Generally, the KAMA is very good at filtering out the noise itself - it will go flat during noisy/choppy periods. But to add another layer of safety, its author, Perry Kaufman, proposed a KAMA filter. It works by taking the standard deviation of returns over the length of the the 'KAMA 1: Length' I mentioned above and multiplying it by an 'Entry Filter' (1 by default) and 'Exit Filter' (0.5 by default). The entry condition to go long is that the KAMA is pointing up and and it moved up more than 1 x St. Dev. of Returns. The exit condition is when the KAMA is pointing down and it moved down by more than 0.5 x St. Dev. of Returns.
Thanks
Thanks to ChuckBanger, cheatcountry, millerrh, and racer8 for parts of the code. I was able to build upon their good work.
-----
I hope this strategy is helpful to you.
Do you have any thoughts, ideas, or questions? Let me know in the comments or send me a message! I'd be glad to help you out.
If you need an indicator or strategy to be built or customised for you, let me know! I'll be glad to help and it'll probably be cheaper than you think!
[blackcat] L2 Ehlers DFT Spectral EstimateLevel: 2
Background
John F. Ehlers introduced DFT Spectral Estimate in his "Cycle Analytics for Traders" chapter 9 on 2013.
Function
The DFT is accomplished by correlating the data with the cosine and sine of each period of interest over the selected window period. The sum of the squares of each of these correlated values represents the relative power at each period. The only user input is whether to select Spectral Dilation compensation. The default selection is NOT to use the compensation.
The spectrum values vary between 0 and 1 after being normalized. These values are converted to colors. When the spectrum is greater than 0.5 the colors combine red and yellow, with yellow being the result when spectrum = 1 and red being the result when the spectrum = 0.5. When the spectrum is less than 0.5, the red saturation is decreased, with the result that the color is black when spectrum = 0.
Key Signal
DominantCycle --> Dominant Cycle signal
Pros and Cons
100% John F. Ehlers definition translation of original work, even variable names are the same. This help readers who would like to use pine to read his book. If you had read his works, then you will be quite familiar with my code style.
Remarks
The 51th script for Blackcat1402 John F. Ehlers Week publication.
Readme
In real life, I am a prolific inventor. I have successfully applied for more than 60 international and regional patents in the past 12 years. But in the past two years or so, I have tried to transfer my creativity to the development of trading strategies. Tradingview is the ideal platform for me. I am selecting and contributing some of the hundreds of scripts to publish in Tradingview community. Welcome everyone to interact with me to discuss these interesting pine scripts.
The scripts posted are categorized into 5 levels according to my efforts or manhours put into these works.
Level 1 : interesting script snippets or distinctive improvement from classic indicators or strategy. Level 1 scripts can usually appear in more complex indicators as a function module or element.
Level 2 : composite indicator/strategy. By selecting or combining several independent or dependent functions or sub indicators in proper way, the composite script exhibits a resonance phenomenon which can filter out noise or fake trading signal to enhance trading confidence level.
Level 3 : comprehensive indicator/strategy. They are simple trading systems based on my strategies. They are commonly containing several or all of entry signal, close signal, stop loss, take profit, re-entry, risk management, and position sizing techniques. Even some interesting fundamental and mass psychological aspects are incorporated.
Level 4 : script snippets or functions that do not disclose source code. Interesting element that can reveal market laws and work as raw material for indicators and strategies. If you find Level 1~2 scripts are helpful, Level 4 is a private version that took me far more efforts to develop.
Level 5 : indicator/strategy that do not disclose source code. private version of Level 3 script with my accumulated script processing skills or a large number of custom functions. I had a private function library built in past two years. Level 5 scripts use many of them to achieve private trading strategy.

[blackcat] L2 Ehlers Autocorrelation PeriodogramLevel: 2
Background
John F. Ehlers introduced Autocorrelation Periodogram in his "Cycle Analytics for Traders" chapter 8 on 2013.
Function
Construction of the autocorrelation periodogram starts with the autocorrelation function using the minimum three bars of averaging. The cyclic information is extracted using a discrete Fourier transform (DFT) of the autocorrelation results. This approach has at least four distinct advantages over other spectral estimation techniques. These are:
1. Rapid response. The spectral estimates start to form within a half-cycle period of their initiation.
2. Relative cyclic power as a function of time is estimated. The autocorrelation at all cycle periods can be low if there are no cycles present, for example, during a trend. Previous works treated the maximum cycle amplitude at each time bar equally.
3. The autocorrelation is constrained to be between minus one and plus one regardless of the period of the measured cycle period. This obviates the need to compensate for Spectral Dilation of the cycle amplitude as a function of the cycle period.
4. The resolution of the cyclic measurement is inherently high and is independent of any windowing function of the price data.
The dominant cycle is extracted from the spectral estimate in the next block of code using a center-of-gravity (CG) algorithm. The CG algorithm measures the average center of two-dimensional objects. The algorithm computes the average period at which the powers are centered. That is the dominant cycle. The dominant cycle is a value that varies with time. The spectrum values vary between 0 and 1 after being normalized. These values are converted to colors. When the spectrum is greater than 0.5, the colors combine red and yellow, with yellow being the result when spectrum = 1 and red being the result when the spectrum = 0.5. When the spectrum is less than 0.5, the red saturation is decreased, with the result the color is black when spectrum = 0.
Key Signal
DominantCycle --> Dominant Cycle
Period --> Autocorrelation Periodogram Array
Pros and Cons
100% John F. Ehlers definition translation of original work, even variable names are the same. This help readers who would like to use pine to read his book. If you had read his works, then you will be quite familiar with my code style.
Remarks
The 49th script for Blackcat1402 John F. Ehlers Week publication.
Courtesy of @RicardoSantos for RGB functions.
Readme
In real life, I am a prolific inventor. I have successfully applied for more than 60 international and regional patents in the past 12 years. But in the past two years or so, I have tried to transfer my creativity to the development of trading strategies. Tradingview is the ideal platform for me. I am selecting and contributing some of the hundreds of scripts to publish in Tradingview community. Welcome everyone to interact with me to discuss these interesting pine scripts.
The scripts posted are categorized into 5 levels according to my efforts or manhours put into these works.
Level 1 : interesting script snippets or distinctive improvement from classic indicators or strategy. Level 1 scripts can usually appear in more complex indicators as a function module or element.
Level 2 : composite indicator/strategy. By selecting or combining several independent or dependent functions or sub indicators in proper way, the composite script exhibits a resonance phenomenon which can filter out noise or fake trading signal to enhance trading confidence level.
Level 3 : comprehensive indicator/strategy. They are simple trading systems based on my strategies. They are commonly containing several or all of entry signal, close signal, stop loss, take profit, re-entry, risk management, and position sizing techniques. Even some interesting fundamental and mass psychological aspects are incorporated.
Level 4 : script snippets or functions that do not disclose source code. Interesting element that can reveal market laws and work as raw material for indicators and strategies. If you find Level 1~2 scripts are helpful, Level 4 is a private version that took me far more efforts to develop.
Level 5 : indicator/strategy that do not disclose source code. private version of Level 3 script with my accumulated script processing skills or a large number of custom functions. I had a private function library built in past two years. Level 5 scripts use many of them to achieve private trading strategy.

Horcrux OscilatorDoes your oscilator give exit signal on time? Mine does. However worst the idea is, I had to come up with a horcrux plan :P
Concept is as below:
I use 7 standard deviation Bollinger bands to identify which level current price is in. Standard deviations used are from 0.5 (lowest level) to 3.5(highest level) with 0.5 step . This creates overall 16 levels ranging from 0 to 15 with 0 being the highest level and 15 being the lowest.
LookbackPeriod is used to calculate max and min values of these threshold over certain bars. Average of max and min constitutes threshold.
Horcrux value is difference between max state and current state in LookbackPeriod.
Lower the horcrux much closer the current state to the highest state. Hence, horcrux higher than threshold is considered as green region where prices are moving up. Decrease in number of horcruxes means price state moving closer to highest state (which is the lower level). Hence, indicates reduced momentum or reversal.
Use higher LookbackPeriod for increased accuracy. Increase BBLength for long term trades. Adjustment is used to adjust threshold line by up to + or - 20%

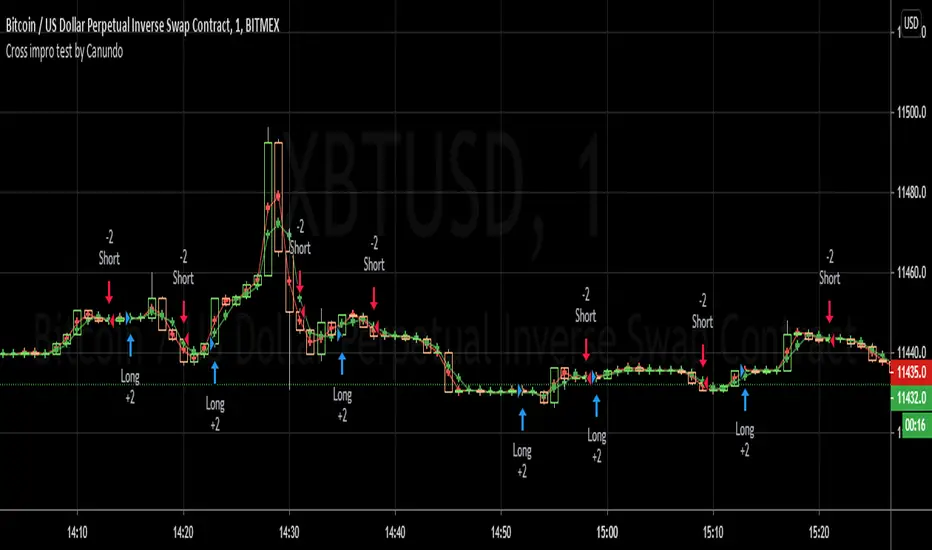
Cross impro test by Canundo Crossover Crossunder Tick valuesThis is a script where I tried to check the following things:
Even thought the tick of an asset is, for example 0.5, there are calculated prices, like SMA's that have even more decimals. Leading to crosses happening that for example happen at the same price. Consequently triggering totally useless in side markets. What happens if SMA values are restricted to the tick resolution? (Option works on it's own or with a combination of the others.)
What happens if I set my own tick value, like 0.8 instead of 0.5, what will be the effect for calculated values that are used for crossings? Will tick sizes improve the success rate? (This option will work only when the first option is active.)
Can success rate, especially for sideway markets be improved when adding a spread between MA's, so that it triggers less in sideway markets? (Option works on it's own or with a combination of the others.)
First of all, I had a hard time to round prices properly when it needs to be dynamic and working for different assets with different amounts of decimal values in the tick. The solution is that abs(floor(syminfo.mintick)) will give you the amount of decimals a tick has. It works for all ticks that are at least lower than 10. I'm not sure how huge ticks are out there. I did not implement this solution at the end since I found another way to test it.
Findings:
The first option, when activated, takes out half the trades and raises the percent profitability by 8% so there is some effect. However, all of the tested options have less advantage than I hoped for but are nevertheless something worthy for sideway markets. The first option just forces the MA's from the example to use the tick resolution.
See these two images. One when the first option is off, the second when it's active.
The lines are the MA's with adjusted values, the crosses are the places of the MA's when left as is.
Here a screenshot of the third option set to the value 2 on the 1 minute XBTUSD chart.
The advantage is that less trades trigger that have a low change in price and so less trading fees will happen.
The disadvantage is that all options can implement some delay for a crossing since the crossing will trigger once a slightly bigger move into the direction was taken.
This test environment was not meant to be profitable but to test the effects.
Maybe someone finds it interesting or wanted to test the same, so here you can save some work.
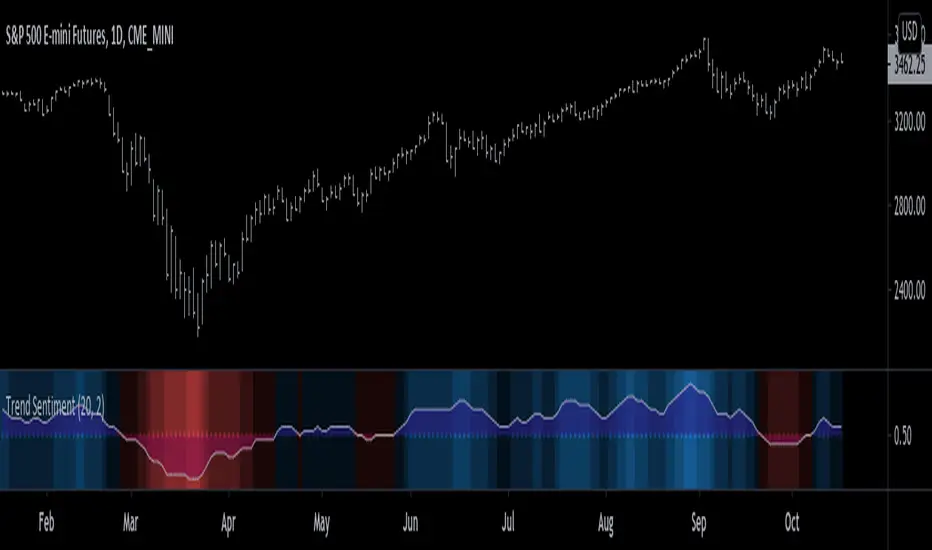
Trend Sentiment [racer8]Trend Sentiment is a trend indicator with enhanced graphics, that is, it has many different shades of blue and red.
The brighter the blue, the more bullish.
The brighter the red, the more bearish.
It is a simple indicator with a basic formula:
a = close > prev.close? ---> If yes, a = 1, otherwise a = 0.
b = sma of a over n periods -----1st parameter, n...."Length"
c = sma of b over j periods ----- 2nd parmeter, j..."Smoothing"
plot (c)
Is c > 0.5? ---> If yes, background color = blue, otherwise red.
plot background color.
plot 0.5 as dotted midline.
The Trend Sentiment value represents the percentage of bullish force in the market.
Signals are generated when it crosses the 50% mark.
Values above 0.50 are bullish and values below 0.50 are bearish.
Enjoy and hit the like button :)
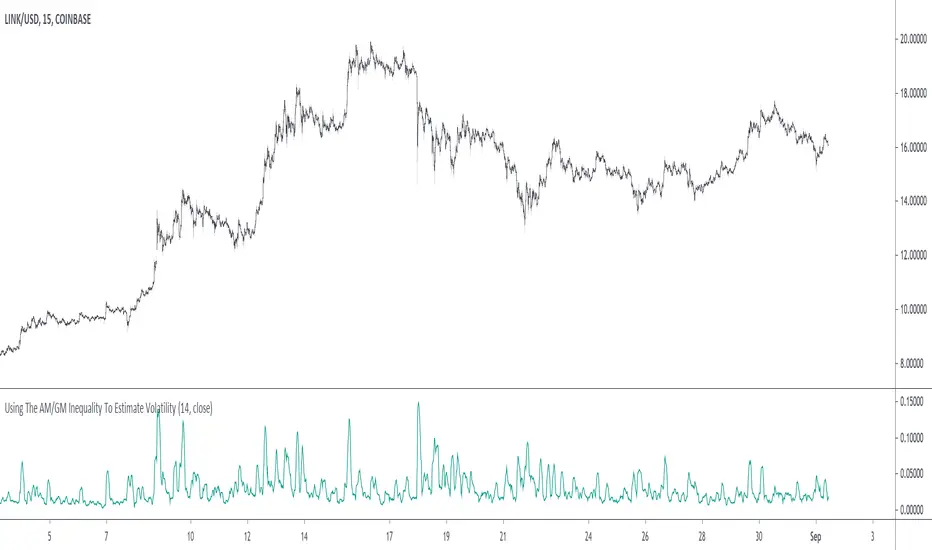
Using The AM/GM Inequality To Estimate VolatilityA volatility indicator derived from the AM/GM inequality. I don't think it will be necessary to describe the usage and interpretation of such indicator, and I don't think it is super useful, however, this is not the case of the script, which contains three ways to compute the geometric mean, with a classic, a simple, and an efficient way. The AM/GM inequality is also a really interesting concept, and I'll try to"prove" it in this post by using DSP. I also added more comments in the script in order to highlight some stuff.
The AM/GM Inequality
When we talk about the mean, we are referring to the "arithmetic" one by default, but there exist more types of means. Two other ones include the "geometric" and "harmonic" means, both are part of the Pythagorean means with the arithmetic mean.
Each one of them as several properties, but the most interesting aspect is their inequality, that is:
HM <= GM <= AM
The arithmetic mean is the one with the highest value, while the harmonic mean is the one with the lowest value. In the case each data point is equal to each other, all the means have the same value.
In our case, the inequality of interest is the inequality between the geometric and arithmetic mean, where the geometric mean is lower or equal than the arithmetic one. Many proofs/explanations exist, I'll try my version using DSP, where instead of thinking about means, we think about rolling means, which allows us to interpret them as low-pass filters. So we end up having the geometric moving average (GMA) and arithmetic moving average (SMA).
We know that GMA <= SMA , the SMA has a unity passband, this implies that the GMA has a passband lower than 1 (for non-equal input values), this explains why the GMA is smaller than the SMA. In order for a FIR filter to have a passband lower than 1, the sum of the filter coefficients must be lower than 1. In order to further proves this consider the following equation:
sqrt(a×b) = k×a + k×b
Here sqrt(a×b) is the geometric mean of a and b , the right-hand side of the equation is a weighted sum between a and b and coefficient k , we want to solve the equation with respect to k , if k×2 < 1 then we have the proof that GMA < SMA . The solution with respect to k is:
k = sqrt(a×b)/(a+b)
which always gives a number lower than 0.5, as such k×2 < 1 and thus the passband is lower than 1. If our input values are equal to each other, we end up with the following solution for k :
k = sqrt(a×a)/(a+a) = a/(2×a) = 0.5
as such the GMA has the coefficients of an SMA as long as the input values are equal to each other.
Because of this inequality, we can subtract the SMA to a GMA and take the square root of the result in order to have a volatility indicator, however, both moving averages are still pretty close to each other, which gives a very small result for the indicator.
Uwu I am a bit tired, better indicators coming up
Grid Like StrategyIt is possible to use progressive position sizing in order to recover from past losses, a well-known position sizing system being the "martingale", which consists of doubling your position size after a loss, this allows you to recover any previous losses in a losing streak + winning an extra. This system has seen a lot of attention from the trading community (mostly from beginners), and many strategies have been designed around the martingale, one of them being "grid trading strategies".
While such strategies often shows promising results on paper, they are often subjects to many frictions during live trading that makes them totally unusable and dangerous to the trader. The motivations behind posting such a strategy isn't to glorify such systems, but rather to present the problems behind them, many users come to me with their ideas and glorious ways to make money, sometimes they present strategies using the martingale, and it is important to present the flaws of this methodology rather than blindly saying "you shouldn't use it".
Strategy Settings
Point determines the "grid" size and should be adjusted accordingly to the scale of the symbol you are applying the strategy to. Higher value would require larger price movements in order to trigger a trade, as such higher values will generate fewer trades.
The order size determines the number of contracts/shares to purchase.
The martingale multiplier determines the factor by which the position size is multiplied after a loss, using values higher to 2 will "squarify" your balance, while a value of 1 would use a constant position sizing.
Finally, the anti-martingale parameter determines whether the strategy uses a reverse martingale or not, if set to true then the position size is multiplied after any wins.
The Grid
Grid strategies are commons and do not present huge problems until we use certain position sizing methods such as the martingale. A martingale is extremely sensitive to any kind of friction (frictional costs, slippage...etc), the grid strategy aims to provide a stable and simple environment where a martingale might possibly behave well.
The goal of a simple grid strategy is to go long once the price crossover a certain level, a take profit is set at the level above the current one and stop loss is placed at the level below the current one, in a winning scenario the price reach the take profit, the position is closed and a new one is opened with the same setup. In a losing scenario, the price reaches the stop loss level, the position is closed and a short one is opened, the take profit is set at the level below the current one, and a stop loss is set at the level above the current one. Note that all levels are equally spaced.
It follows from this strategy that wins and losses should be constant over time, as such our balance would evolve in a linear fashion. This is a great setup for a martingale, as we are theoretically assured to recover all the looses in a losing streak.
Martingale - Exponential Decays - Risk/Reward
By using a martingale we double our position size (exposure) each time we lose a trade, if we look at our balance when using a martingale we see significant drawdowns, with our balance peaking down significantly. The martingale sequence is subject to exponential growth, as such using a martingale makes our balance exposed to exponential decays, that's really bad, we could basically lose all the initially invested capital in a short amount of time, it follows from this that the theoretical success of a martingale is determined by what is the maximum losing streak you can endure
Now consider how a martingale affects our risk-reward ratio, assuming unity position sizing our martingale sequence can be described by 2^(x-1) , using this formula we would get the amount of shares/contracts we need to purchase at the x trade of a losing streak, we would need to purchase 256 contracts in order to recover from a losing streak of size 9, this is enormous when you take into account that your wins are way smaller, the risk-reward ratio is totally unfair.
Of course, some users might think that a losing streak of size 9 is pretty unlikely, if the probability of winning and losing are both equal to 0.5, then the probability of 9 consecutive losses is equal to 0.5^9 , there are approximately 0.2% of chance of having such large losing streak, note however that under a ranging market such case scenario could happen, but we will see later that the length of a losing streak is not the only problem.
Other Problems
Having a capital large enough to tank 9any number of consecutive losses is not the only thing one should focus on, as we have to take into account market prices and trading dynamics, that's where the ugly part start.
Our first problem is frictional costs, one example being the spread, but this is a common problem for any strategy, however here a martingale is extra sensitive to it, if the strategy does not account for it then we will still double our positions costs but we might not recover all the losses of a losing streak, instead we would be recovering only a proportion of it, under such scenario you would be certain to lose over time.
Another problem are gaps, market price might open under a stop-loss without triggering it, and this is a big no-no.
Equity of the strategy on AMD, in a desired scenario the equity at the second arrow should have been at a higher position than the equity at the first arrow.
In order for the strategy to be more effective, we would need to trade a market that does not close, such as the cryptocurrency market. Finally, we might be affected by slippage, altho only extreme values might drastically affect our balance.
The Anti Martingale
The strategy lets you use an anti-martingale, which double the position size after a win instead of a loss, the goal here is not to recover from a losing strike but instead to profit from a potential winning streak.
Here we are exposing your balance to exponential gross but you might also lose a trade at the end a winning streak, you will generally want to reinitialize your position size after a few wins instead of waiting for the end of a streak.
Alternative
You can use other-kind of progressions for position sizing, such as a linear one, increasing your position size by a constant number each time you lose. More gentle progressions will recover a proportion of your losses in a losing streak.
You can also simulate the effect of a martingale without doubling your position size by doubling your target profit, if for example you have a 10$ profit-target/stop-loss and lose a trade, you can use a 20$ profit target to recover from the lost trade + gain a profit of 10$. While this approach does not introduce exponential decay in your balance, you are betting on the market reaching your take profits, considering the fact that you are doubling their size you are expecting market volatility to increase drastically over time, as such this approach would not be extremely effective for high losing streak.
Conclusion
You will see a lot of auto-trading strategies that are based on a grid approach, they might even use a martingale. While the backtests will look appealing, you should think twice before using such kind of strategy, remember that frictional costs will be a huge challenge for the strategy, and that it assumes that the trader has an important initial capital. We have also seen that the risk/reward ratio is theoretically the worst you can have on a strategy, having a low reward and a high risk. This does not mean that progressive position sizing is bad, but it should not be pushed to the extreme.
It is nice to note that the martingale is originally a betting system designed for casino games, which unlike trading are not subject to frictional costs, but even casino players don't use it, so why would you?
Thx for reading

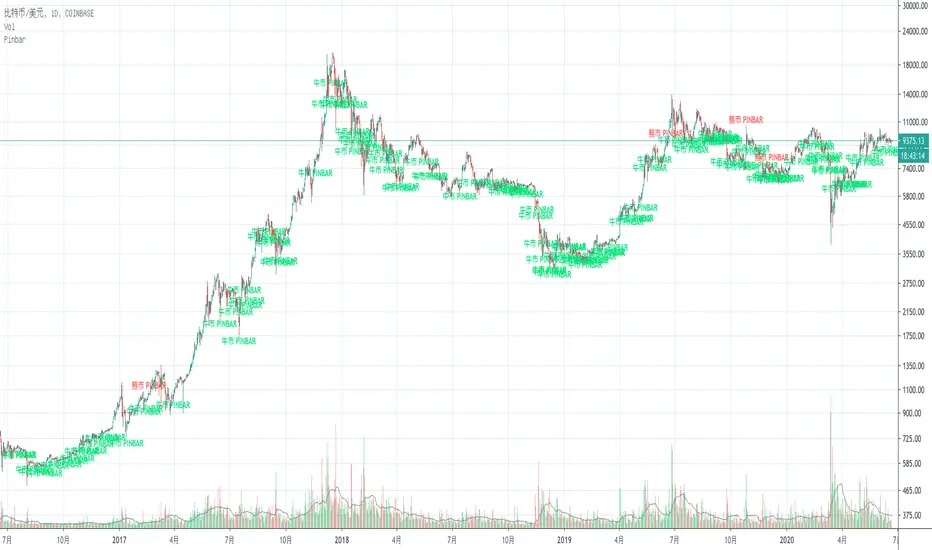
Pinbar识别器This is a Pinbar Monitor which design for Chinese.
这是一个Pinbar识别器。
本脚本的目的在于帮助使用中文的人了解该指标,特别是其用法。同时将该指标代码添加完整的中文注释,方便使用中文的人学习Pine语言。
Pinbar概念来自于Price Action,基本类似于国内K线分析中的十字星,锤子线。该指标的主要功用在于帮助识别盘面出现的Pinbar,分为牛市Pinbar和熊市Pinbar。
对Pinbar的量化定义
熊市Pinbar
1 前一根K线,必须为阳线;
2 K线实体必须小于前一根K线;
3 下影线高度至少大于0.5倍实体高度;
4 上影线高度至少是2倍实体高度。
牛市Pinbar
1 前一根K线,必须为阴线;
2 K线实体必须小于前一根K线;
3 上影线高度至少大于0.5倍实体高度;
4 下影线高度至少是2倍实体高度。
指标局限性
因为Pinbar出现的概率比较高,所以切勿直接按信号交易,应考虑其他的分析方法,综合考虑再决定是否交易。
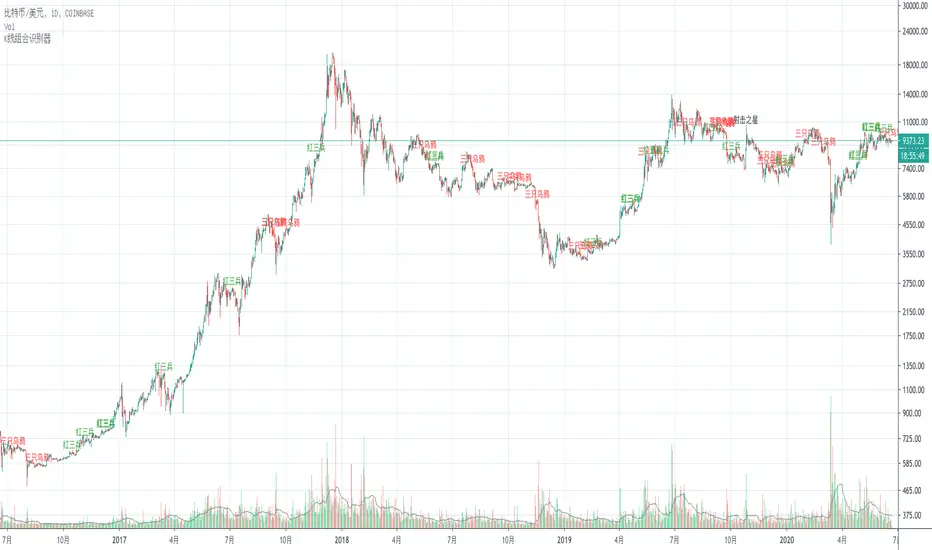
K线组合识别器(Candlestick Pattern Monitor)This is a Candlestick Pattern Monitor which design for Chinese.
这是一个K线组合的识别器。
本脚本的目的在于帮助使用中文的人了解该指标,特别是其用法。同时将该指标代码添加完整的中文注释,方便使用中文的人学习Pine语言。
K线组合是国内技术分析里最常见的分析方式之一。K线组合种类丰富,各类证券类书籍中均有总结,本识别器选取其中几种传播度最高几个K线组合,将其量化,使用机器辅助识别K线组合。
射击之星
射击之星,在股价运行的高位,一根中阳或者大阳线之后出现长上影K线,往往是较为强烈的看空信号,K线的实体部分很小或者为十字线,上影线一般为实体K线的两倍以上。
量化要点:
1 上一根K线须是一根实体高度必须大于最近10根K线实体平均值1.5倍;
2 上影线至少是实体的2倍;
3 下影线不大于实体的0.5倍。
乌云盖顶
乌云盖顶组合,第一根K线为大阳线或者中阳线,第二天跳空高开,第二根K线的开盘价远高于第一根K线的最高价,但是收盘却跌入第一根K线的实体部分,第二根K线收盘价越底,则拐点的信号越明确。
量化要点:
1 跳开,即当前K线开盘价大于上一根收盘价;
2 上一根K线须是一根实体高度必须大于最近10根K线实体平均值1.5倍;
3 当前K线收于前一根K线实体下半部分。
三只乌鸦
三只乌鸦组合的构成,股价上涨的高位区域,一根大阳线之后连续出现三根小阴线,每一根阴线都是跳空高开,但是收在当日最低附近。
量化要点:
1 连续三根阴线;
2 三根阴线的实体都小于最近十根K线实体的平均值。
下跌三部曲
下跌三部曲的构成,一根大阴线或者中阴线之后,随后的交易日连续三根价量逐日萎缩的小阳线,三根小阳线的最高价未能击破前面阴线的开盘价,随即股价重回下跌趋势,并再报收大阴线或者中阴线。
量化要点:
1 组合第一根K线为阴线;
2 组合的第二至第四根K线都为阳线;
3 第四根K线收盘价不高于第一根K线开盘价;
4 第五根K线为阴线,且收盘价低于第二根K线开盘价。
早晨之星
早晨之星由三根K线组合成,第一根是中阴线或者大阴线,第二根是小阳线或者小阴线,第三根为中阳线或者大阳线,如果第二根是十字线,也成为早晨之星,第三根阳线实体切入第一根阴线的实体之内,切入的幅度越大,信号越明确。
量化要点:
1 第一根K线为阴线,且实体高度大于最近十根K线实体的平均值的1.5倍;
2 第二根K线实体高度小于最近十根K线实体的平均值,且上影线小于实体的0.5倍,下影线大于实体的2倍;
3 第三根K线为阳线,且收盘价大于第一根K线开盘价。
红三兵
红三兵构成,三根上涨的小阳K线,如果出现在大跌之后的底部区域或者盘整区域,再配合成交量,往往成为上涨行情的先兆。
量化要点:
1 三根K线均为阳线;
2 三根K线的实体均小于最近十根K线实体的平均值。
指标局限性
因K线组合出现的频次均较高,所以K线组合需结合其他分析方式一起考虑。
Hashem Correlation CoefficientCorrelation Coefficient
Core Code from: www.tradingview.com
This indicator Show Correlation between the Current Ticker & timeframe and a Customizable Ticker. After adding the indicator you can change the second ticker in the settings.
The Correlation Coeff is between -1 to 1 which 1 means 100% correlation and -1 means -100% correlation ( Inverse Correlation ).
The color of the area changes when:
Blue : CC > 0.5
Aqua : CC > 0.75
Purple : CC < -0.5
Red : CC < -0.75
Hancock - IFT RSI T3MAThis is a version of the Inverse Fisher Transform Relative Strength Index with T3MA smoothing and histogram difference based on EMA signal line.
Configurable parameters:
RSI length - This is the period used for the RSI .
RSI Smooth Length - This is the smoothing period of the Weighted Moving Average used for the smoothing in Inverse Fisher Transform .
RSI Signal - This is the period used for EMA signal line.
RSI Overbought - Configures the overbought threshold (0.5 default).
RSI Oversold - Configures the oversold threshold (-0.5 default).
T3 Smoothing - Enabling this applies T3MA smoothing to the RSI .
T3 Length - This is the period used for the T3MA smoothing of the RSI .
T3 Factor - This is the factor used for the T3MA smoothing of the RSI .
I've added a histogram plotting the difference between the signal line and RSI to make it easier to make trades. Oversold and Overbought thresholds are indicated by the red and green horizontal lines. Signal line is coloured for trade direction.
Happy trading folks!
Hancock

CPR WidthThe indicator shows the width of the Central Pivot Range. Frank Ochoa call it It Pivot Range Histogram in his book.
Use it in conjunction with the Central Pivot Range indicator.
Below is the interpretation of the reading.
CPR Width > 0.5 - Sideways or Trading Range Day,
CPR Width > 0.75 - increases the likelihood of sideways trading behavior,
CPR Width < 0.5 - Trending type of day,
CPR Width < 0.25 - increases the likelihood of a trending market.
The above reading only increases the likely-hood of the possibility and not always right.

Powered Kaufman Adaptive Moving AverageIntroduction
The ability the Kaufman adaptive moving average (KAMA) has to be flat during ranging markets and close to the price during trending markets is what make this moving average one of the most useful in technical analysis. KAMA is calculated by using exponential averaging using the efficiency ratio (ER) as smoothing variable where 1 > ER > 0 . An increasing efficiency ratio indicate a trending market. Based on one of my latest indicator (see Kaufman Adaptive Bands) i propose this modified KAMA that allow to emphasis the abilities of KAMA by powering the efficiency ratio. I also added a new option that allow for even more adaptivity.
The Indicator
The indicator is a simple KAMA of period length that use a powered ER with exponent factor .
When factor = 1 the indicator is a simple KAMA, however when factor > 1 there can be more emphasis on the flattening effect of KAMA.
You can also restrain this effect by using 1 > factor > 0
Note that when the exponent is lower than 1 and greater than 0 you are basically applying a nth square root to the value, for example pow(2,0.5) = sqrt(2) because 1/0.5 = 2, in our case :
pow(ER,factor > 1) < ER and pow(ER,1 > factor > 0) > ER
Self Powered P-KAMA
When the self powered option is checked you are basically powering ER with the reciprocal of ER as exponent, however factor does no longer change anything. This can give interesting results since the exponent depend on the market trend strength.
In orange the self powered KAMA of period length = 50 and in blue a basic powered KAMA with a factor of 3 and a period of length = 50.
Conclusion
Applying basic math to indicators is always fun and easy to do, if you have adaptive moving averages using exponential averaging try powering your smoothing variable in order to see interesting results. I hope you like this indicator. Thanks for reading !

RVOL - Final on 814 for 3m Candles ONLYRelative Volume for 3 minute charts ONLY.
Lookback 20 days.
Historical and average values are used to formulate the ratio.
Thank you to R4Rocket for the initial code.
I also researched the RVOL output in Trade Ideas to align the final ratio as close as possible.
The colors change at different levels:
<0.5 ; Red
0.5 > and <=.65 ; Orange
0.65 > and <=1 ; Dark Yellow
1 > and <=1.25 ; Bright Yellow
1.25 < and <=1.5 ; Dark Green
1.5 < and <=2 ; Brighter Green
Above 2 ; Very Bright Green
