MLExtensionsLibrary "MLExtensions"
A set of extension methods for a novel implementation of a Approximate Nearest Neighbors (ANN) algorithm in Lorentzian space.
normalizeDeriv(src, quadraticMeanLength)
Returns the smoothed hyperbolic tangent of the input series.
Parameters:
src (float) : The input series (i.e., the first-order derivative for price).
quadraticMeanLength (int) : The length of the quadratic mean (RMS).
Returns: nDeriv The normalized derivative of the input series.
normalize(src, min, max)
Rescales a source value with an unbounded range to a target range.
Parameters:
src (float) : The input series
min (float) : The minimum value of the unbounded range
max (float) : The maximum value of the unbounded range
Returns: The normalized series
rescale(src, oldMin, oldMax, newMin, newMax)
Rescales a source value with a bounded range to anther bounded range
Parameters:
src (float) : The input series
oldMin (float) : The minimum value of the range to rescale from
oldMax (float) : The maximum value of the range to rescale from
newMin (float) : The minimum value of the range to rescale to
newMax (float) : The maximum value of the range to rescale to
Returns: The rescaled series
getColorShades(color)
Creates an array of colors with varying shades of the input color
Parameters:
color (color) : The color to create shades of
Returns: An array of colors with varying shades of the input color
getPredictionColor(prediction, neighborsCount, shadesArr)
Determines the color shade based on prediction percentile
Parameters:
prediction (float) : Value of the prediction
neighborsCount (int) : The number of neighbors used in a nearest neighbors classification
shadesArr (array) : An array of colors with varying shades of the input color
Returns: shade Color shade based on prediction percentile
color_green(prediction)
Assigns varying shades of the color green based on the KNN classification
Parameters:
prediction (float) : Value (int|float) of the prediction
Returns: color
color_red(prediction)
Assigns varying shades of the color red based on the KNN classification
Parameters:
prediction (float) : Value of the prediction
Returns: color
tanh(src)
Returns the the hyperbolic tangent of the input series. The sigmoid-like hyperbolic tangent function is used to compress the input to a value between -1 and 1.
Parameters:
src (float) : The input series (i.e., the normalized derivative).
Returns: tanh The hyperbolic tangent of the input series.
dualPoleFilter(src, lookback)
Returns the smoothed hyperbolic tangent of the input series.
Parameters:
src (float) : The input series (i.e., the hyperbolic tangent).
lookback (int) : The lookback window for the smoothing.
Returns: filter The smoothed hyperbolic tangent of the input series.
tanhTransform(src, smoothingFrequency, quadraticMeanLength)
Returns the tanh transform of the input series.
Parameters:
src (float) : The input series (i.e., the result of the tanh calculation).
smoothingFrequency (int)
quadraticMeanLength (int)
Returns: signal The smoothed hyperbolic tangent transform of the input series.
n_rsi(src, n1, n2)
Returns the normalized RSI ideal for use in ML algorithms.
Parameters:
src (float) : The input series (i.e., the result of the RSI calculation).
n1 (simple int) : The length of the RSI.
n2 (simple int) : The smoothing length of the RSI.
Returns: signal The normalized RSI.
n_cci(src, n1, n2)
Returns the normalized CCI ideal for use in ML algorithms.
Parameters:
src (float) : The input series (i.e., the result of the CCI calculation).
n1 (simple int) : The length of the CCI.
n2 (simple int) : The smoothing length of the CCI.
Returns: signal The normalized CCI.
n_wt(src, n1, n2)
Returns the normalized WaveTrend Classic series ideal for use in ML algorithms.
Parameters:
src (float) : The input series (i.e., the result of the WaveTrend Classic calculation).
n1 (simple int)
n2 (simple int)
Returns: signal The normalized WaveTrend Classic series.
n_adx(highSrc, lowSrc, closeSrc, n1)
Returns the normalized ADX ideal for use in ML algorithms.
Parameters:
highSrc (float) : The input series for the high price.
lowSrc (float) : The input series for the low price.
closeSrc (float) : The input series for the close price.
n1 (simple int) : The length of the ADX.
regime_filter(src, threshold, useRegimeFilter)
Parameters:
src (float)
threshold (float)
useRegimeFilter (bool)
filter_adx(src, length, adxThreshold, useAdxFilter)
filter_adx
Parameters:
src (float) : The source series.
length (simple int) : The length of the ADX.
adxThreshold (int) : The ADX threshold.
useAdxFilter (bool) : Whether to use the ADX filter.
Returns: The ADX.
filter_volatility(minLength, maxLength, useVolatilityFilter)
filter_volatility
Parameters:
minLength (simple int) : The minimum length of the ATR.
maxLength (simple int) : The maximum length of the ATR.
useVolatilityFilter (bool) : Whether to use the volatility filter.
Returns: Boolean indicating whether or not to let the signal pass through the filter.
backtest(high, low, open, startLongTrade, endLongTrade, startShortTrade, endShortTrade, isEarlySignalFlip, maxBarsBackIndex, thisBarIndex, src, useWorstCase)
Performs a basic backtest using the specified parameters and conditions.
Parameters:
high (float) : The input series for the high price.
low (float) : The input series for the low price.
open (float) : The input series for the open price.
startLongTrade (bool) : The series of conditions that indicate the start of a long trade.
endLongTrade (bool) : The series of conditions that indicate the end of a long trade.
startShortTrade (bool) : The series of conditions that indicate the start of a short trade.
endShortTrade (bool) : The series of conditions that indicate the end of a short trade.
isEarlySignalFlip (bool) : Whether or not the signal flip is early.
maxBarsBackIndex (int) : The maximum number of bars to go back in the backtest.
thisBarIndex (int) : The current bar index.
src (float) : The source series.
useWorstCase (bool) : Whether to use the worst case scenario for the backtest.
Returns: A tuple containing backtest values
init_table()
init_table()
Returns: tbl The backtest results.
update_table(tbl, tradeStatsHeader, totalTrades, totalWins, totalLosses, winLossRatio, winrate, earlySignalFlips)
update_table(tbl, tradeStats)
Parameters:
tbl (table) : The backtest results table.
tradeStatsHeader (string) : The trade stats header.
totalTrades (float) : The total number of trades.
totalWins (float) : The total number of wins.
totalLosses (float) : The total number of losses.
winLossRatio (float) : The win loss ratio.
winrate (float) : The winrate.
earlySignalFlips (float) : The total number of early signal flips.
Returns: Updated backtest results table.
Ml

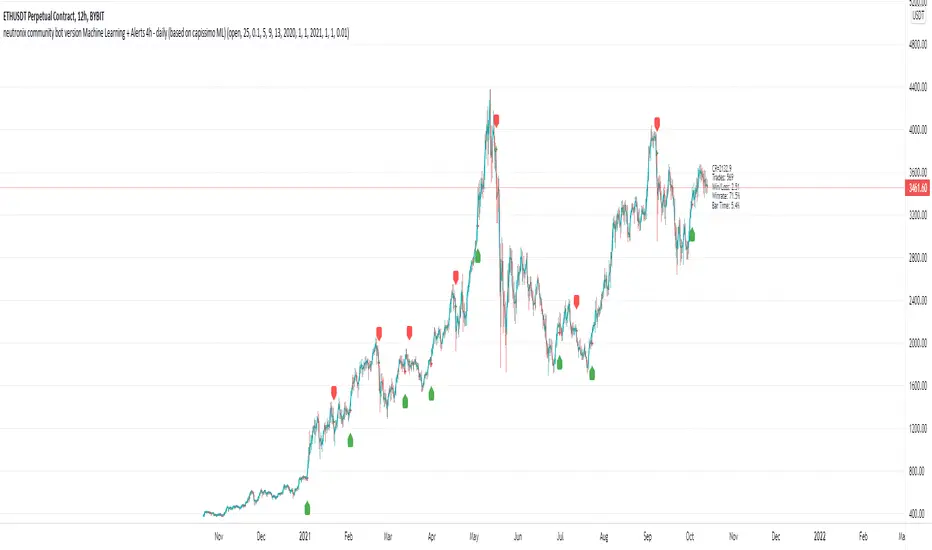
Machine Learning Moving Average [BackQuant]Machine Learning Moving Average
A powerful tool combining clustering, pseudo-machine learning, and adaptive prediction, enabling traders to understand and react to price behavior across multiple market regimes (Bullish, Neutral, Bearish). This script uses a dynamic clustering approach based on percentile thresholds and calculates an adaptive moving average, ideal for forecasting price movements with enhanced confidence levels.
What is Percentile Clustering?
Percentile clustering is a method that sorts and categorizes data into distinct groups based on its statistical distribution. In this script, the clustering process relies on the percentile values of a composite feature (based on technical indicators like RSI, CCI, ATR, etc.). By identifying key thresholds (lower and upper percentiles), the script assigns each data point (price movement) to a cluster (Bullish, Neutral, or Bearish), based on its proximity to these thresholds.
This approach mimics aspects of machine learning, where we “train” the model on past price behavior to predict future movements. The key difference is that this is not true machine learning; rather, it uses data-driven statistical techniques to "cluster" the market into patterns.
Why Percentile Clustering is Useful
Clustering price data into meaningful patterns (Bullish, Neutral, Bearish) helps traders visualize how price behavior can be grouped over time.
By leveraging past price behavior and technical indicators, percentile clustering adapts dynamically to evolving market conditions.
It helps you understand whether price behavior today aligns with past bullish or bearish trends, improving market context.
Clusters can be used to predict upcoming market conditions by identifying regimes with high confidence, improving entry/exit timing.
What This Script Does
Clustering Based on Percentiles : The script uses historical price data and various technical features to compute a "composite feature" for each bar. This feature is then sorted and clustered based on predefined percentile thresholds (e.g., 10th percentile for lower, 90th percentile for upper).
Cluster-Based Prediction : Once clustered, the script uses a weighted average, cluster momentum, or regime transition model to predict future price behavior over a specified number of bars.
Dynamic Moving Average : The script calculates a machine-learning-inspired moving average (MLMA) based on the current cluster, adjusting its behavior according to the cluster regime (Bullish, Neutral, Bearish).
Adaptive Confidence Levels : Confidence in the predicted return is calculated based on the distance between the current value and the other clusters. The further it is from the next closest cluster, the higher the confidence.
Visual Cluster Mapping : The script visually highlights different clusters on the chart with distinct colors for Bullish, Neutral, and Bearish regimes, and plots the MLMA line.
Prediction Output : It projects the predicted price based on the selected method and shows both predicted price and confidence percentage for each prediction horizon.
Trend Identification : Using the clustering output, the script colors the bars based on the current cluster to reflect whether the market is trending Bullish (green), Bearish (red), or is Neutral (gray).
How Traders Use It
Predicting Price Movements : The script provides traders with an idea of where prices might go based on past market behavior. Traders can use this forecast for short-term and long-term predictions, guiding their trades.
Clustering for Regime Analysis : Traders can identify whether the market is in a Bullish, Neutral, or Bearish regime, using that information to adjust trading strategies.
Adaptive Moving Average for Trend Following : The adaptive moving average can be used as a trend-following indicator, helping traders stay in the market when it’s aligned with the current trend (Bullish or Bearish).
Entry/Exit Strategy : By understanding the current cluster and its associated trend, traders can time entries and exits with higher precision, taking advantage of favorable conditions when the confidence in the predicted price is high.
Confidence for Risk Management : The confidence level associated with the predicted returns allows traders to manage risk better. Higher confidence levels indicate stronger market conditions, which can lead to higher position sizes.
Pseudo Machine Learning Aspect
While the script does not use conventional machine learning models (e.g., neural networks or decision trees), it mimics certain aspects of machine learning in its approach. By using clustering and the dynamic adjustment of a moving average, the model learns from historical data to adjust predictions for future price behavior. The "learning" comes from how the script uses past price data (and technical indicators) to create patterns (clusters) and predict future market movements based on those patterns.
Why This Is Important for Traders
Understanding market regimes helps to adjust trading strategies in a way that adapts to current market conditions.
Forecasting price behavior provides an additional edge, enabling traders to time entries and exits based on predicted price movements.
By leveraging the clustering technique, traders can separate noise from signal, improving the reliability of trading signals.
The combination of clustering and predictive modeling in one tool reduces the complexity for traders, allowing them to focus on actionable insights rather than manual analysis.
How to Interpret the Output
Bullish (Green) Zone : When the price behavior clusters into the Bullish zone, expect upward price movement. The MLMA line will help confirm if the trend remains upward.
Bearish (Red) Zone : When the price behavior clusters into the Bearish zone, expect downward price movement. The MLMA line will assist in tracking any downward trends.
Neutral (Gray) Zone : A neutral market condition signals indecision or range-bound behavior. The MLMA line can help track any potential breakouts or trend reversals.
Predicted Price : The projected price is shown on the chart, based on the cluster's predicted behavior. This provides a useful reference for where the price might move in the near future.
Prediction Confidence : The confidence percentage helps you gauge the reliability of the predicted price. A higher percentage indicates stronger market confidence in the forecasted move.
Tips for Use
Combining with Other Indicators : Use the output of this indicator in combination with your existing strategy (e.g., RSI, MACD, or moving averages) to enhance signal accuracy.
Position Sizing with Confidence : Increase position size when the prediction confidence is high, and decrease size when it’s low, based on the confidence interval.
Regime-Based Strategy : Consider developing a multi-strategy approach where you use this tool for Bullish or Bearish regimes and a separate strategy for Neutral markets.
Optimization : Adjust the lookback period and percentile settings to optimize the clustering algorithm based on your asset’s characteristics.
Conclusion
The Machine Learning Moving Average offers a novel approach to price prediction by leveraging percentile clustering and a dynamically adapting moving average. While not a traditional machine learning model, this tool mimics the adaptive behavior of machine learning by adjusting to evolving market conditions, helping traders predict price movements and identify trends with improved confidence and accuracy.

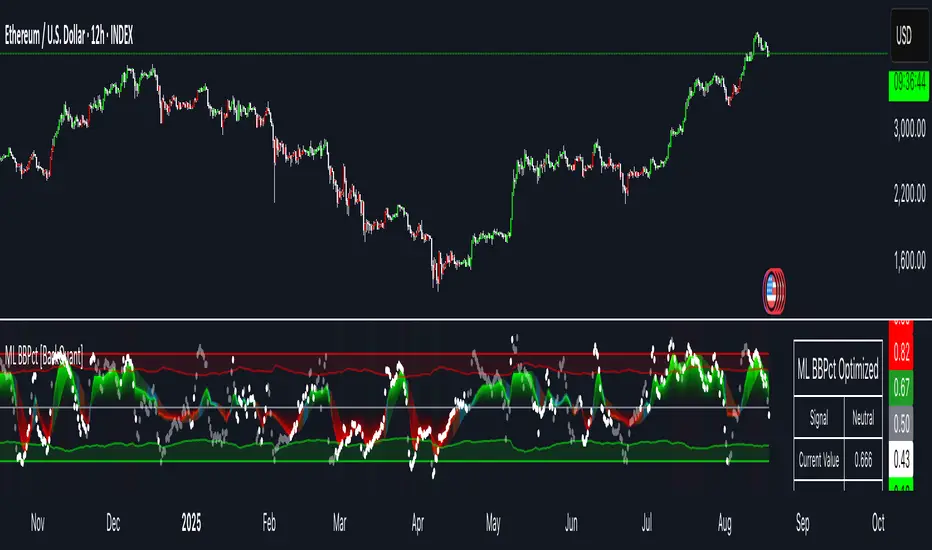
Machine Learning BBPct [BackQuant]Machine Learning BBPct
What this is (in one line)
A Bollinger Band %B oscillator enhanced with a simplified K-Nearest Neighbors (KNN) pattern matcher. The model compares today’s context (volatility, momentum, volume, and position inside the bands) to similar situations in recent history and blends that historical consensus back into the raw %B to reduce noise and improve context awareness. It is informational and diagnostic—designed to describe market state, not to sell a trading system.
Background: %B in plain terms
Bollinger %B measures where price sits inside its dynamic envelope: 0 at the lower band, 1 at the upper band, ~ 0.5 near the basis (the moving average). Readings toward 1 indicate pressure near the envelope’s upper edge (often strength or stretch), while readings toward 0 indicate pressure near the lower edge (often weakness or stretch). Because bands adapt to volatility, %B is naturally comparable across regimes.
Why add (simplified) KNN?
Classic %B is reactive and can be whippy in fast regimes. The simplified KNN layer builds a “nearest-neighbor memory” of recent market states and asks: “When the market looked like this before, where did %B tend to be next bar?” It then blends that estimate with the current %B. Key ideas:
• Feature vector . Each bar is summarized by up to five normalized features:
– %B itself (normalized)
– Band width (volatility proxy)
– Price momentum (ROC)
– Volume momentum (ROC of volume)
– Price position within the bands
• Distance metric . Euclidean distance ranks the most similar recent bars.
• Prediction . Average the neighbors’ prior %B (lagged to avoid lookahead), inverse-weighted by distance.
• Blend . Linearly combine raw %B and KNN-predicted %B with a configurable weight; optional filtering then adapts to confidence.
This remains “simplified” KNN: no training/validation split, no KD-trees, no scaling beyond windowed min-max, and no probabilistic calibration.
How the script is organized (by input groups)
1) BBPct Settings
• Price Source – Which price to evaluate (%B is computed from this).
• Calculation Period – Lookback for SMA basis and standard deviation.
• Multiplier – Standard deviation width (e.g., 2.0).
• Apply Smoothing / Type / Length – Optional smoothing of the %B stream before ML (EMA, RMA, DEMA, TEMA, LINREG, HMA, etc.). Turning this off gives you the raw %B.
2) Thresholds
• Overbought/Oversold – Default 0.8 / 0.2 (inside ).
• Extreme OB/OS – Stricter zones (e.g., 0.95 / 0.05) to flag stretch conditions.
3) KNN Machine Learning
• Enable KNN – Switch between pure %B and hybrid.
• K (neighbors) – How many historical analogs to blend (default 8).
• Historical Period – Size of the search window for neighbors.
• ML Weight – Blend between raw %B and KNN estimate.
• Number of Features – Use 2–5 features; higher counts add context but raise the risk of overfitting in short windows.
4) Filtering
• Method – None, Adaptive, Kalman-style (first-order),
or Hull smoothing.
• Strength – How aggressively to smooth. “Adaptive” uses model confidence to modulate its alpha: higher confidence → stronger reliance on the ML estimate.
5) Performance Tracking
• Win-rate Period – Simple running score of past signal outcomes based on target/stop/time-out logic (informational, not a robust backtest).
• Early Entry Lookback – Horizon for forecasting a potential threshold cross.
• Profit Target / Stop Loss – Used only by the internal win-rate heuristic.
6) Self-Optimization
• Enable Self-Optimization – Lightweight, rolling comparison of a few canned settings (K = 8/14/21 via simple rules on %B extremes).
• Optimization Window & Stability Threshold – Governs how quickly preferred K changes and how sensitive the overfitting alarm is.
• Adaptive Thresholds – Adjust the OB/OS lines with volatility regime (ATR ratio), widening in calm markets and tightening in turbulent ones (bounded 0.7–0.9 and 0.1–0.3).
7) UI Settings
• Show Table / Zones / ML Prediction / Early Signals – Toggle informational overlays.
• Signal Line Width, Candle Painting, Colors – Visual preferences.
Step-by-step logic
A) Compute %B
Basis = SMA(source, len); dev = stdev(source, len) × multiplier; Upper/Lower = Basis ± dev.
%B = (price − Lower) / (Upper − Lower). Optional smoothing yields standardBB .
B) Build the feature vector
All features are min-max normalized over the KNN window so distances are in comparable units. Features include normalized %B, normalized band width, normalized price ROC, normalized volume ROC, and normalized position within bands. You can limit to the first N features (2–5).
C) Find nearest neighbors
For each bar inside the lookback window, compute the Euclidean distance between current features and that bar’s features. Sort by distance, keep the top K .
D) Predict and blend
Use inverse-distance weights (with a strong cap for near-zero distances) to average neighbors’ prior %B (lagged by one bar). This becomes the KNN estimate. Blend it with raw %B via the ML weight. A variance of neighbor %B around the prediction becomes an uncertainty proxy ; combined with a stability score (how long parameters remain unchanged), it forms mlConfidence ∈ . The Adaptive filter optionally transforms that confidence into a smoothing coefficient.
E) Adaptive thresholds
Volatility regime (ATR(14) divided by its 50-bar SMA) nudges OB/OS thresholds wider or narrower within fixed bounds. The aim: comparable extremeness across regimes.
F) Early entry heuristic
A tiny two-step slope/acceleration probe extrapolates finalBB forward a few bars. If it is on track to cross OB/OS soon (and slope/acceleration agree), it flags an EARLY_BUY/SELL candidate with an internal confidence score. This is explicitly a heuristic—use as an attention cue, not a signal by itself.
G) Informational win-rate
The script keeps a rolling array of trade outcomes derived from signal transitions + rudimentary exits (target/stop/time). The percentage shown is a rough diagnostic , not a validated backtest.
Outputs and visual language
• ML Bollinger %B (finalBB) – The main line after KNN blending and optional filtering.
• Gradient fill – Greenish tones above 0.5, reddish below, with intensity following distance from the midline.
• Adaptive zones – Overbought/oversold and extreme bands; shaded backgrounds appear at extremes.
• ML Prediction (dots) – The KNN estimate plotted as faint circles; becomes bright white when confidence > 0.7.
• Early arrows – Optional small triangles for approaching OB/OS.
• Candle painting – Light green above the midline, light red below (optional).
• Info panel – Current value, signal classification, ML confidence, optimized K, stability, volatility regime, adaptive thresholds, overfitting flag, early-entry status, and total signals processed.
Signal classification (informational)
The indicator does not fire trade commands; it labels state:
• STRONG_BUY / STRONG_SELL – finalBB beyond extreme OS/OB thresholds.
• BUY / SELL – finalBB beyond adaptive OS/OB.
• EARLY_BUY / EARLY_SELL – forecast suggests a near-term cross with decent internal confidence.
• NEUTRAL – between adaptive bands.
Alerts (what you can automate)
• Entering adaptive OB/OS and extreme OB/OS.
• Midline cross (0.5).
• Overfitting detected (frequent parameter flipping).
• Early signals when early confidence > 0.7.
These are purely descriptive triggers around the indicator’s state.
Practical interpretation
• Mean-reversion context – In range markets, adaptive OS/OB with ML smoothing can reduce whipsaws relative to raw %B.
• Trend context – In persistent trends, the KNN blend can keep finalBB nearer the mid/upper region during healthy pullbacks if history supports similar contexts.
• Regime awareness – Watch the volatility regime and adaptive thresholds. If thresholds compress (high vol), “OB/OS” comes sooner; if thresholds widen (calm), it takes more stretch to flag.
• Confidence as a weight – High mlConfidence implies neighbors agree; you may rely more on the ML curve. Low confidence argues for de-emphasizing ML and leaning on raw %B or other tools.
• Stability score – Rising stability indicates consistent parameter selection and fewer flips; dropping stability hints at a shifting backdrop.
Methodological notes
• Normalization uses rolling min-max over the KNN window. This is simple and scale-agnostic but sensitive to outliers; the distance metric will reflect that.
• Distance is unweighted Euclidean. If you raise featureCount, you increase dimensionality; consider keeping K larger and lookback ample to avoid sparse-neighbor artifacts.
• Lag handling intentionally uses neighbors’ previous %B for prediction to avoid lookahead bias.
• Self-optimization is deliberately modest: it only compares a few canned K/threshold choices using simple “did an extreme anticipate movement?” scoring, then enforces a stability regime and an overfitting guard. It is not a grid search or GA.
• Kalman option is a first-order recursive filter (fixed gain), not a full state-space estimator.
• Hull option derives a dynamic length from 1/strength; it is a convenience smoothing alternative.
Limitations and cautions
• Non-stationarity – Nearest neighbors from the recent window may not represent the future under structural breaks (policy shifts, liquidity shocks).
• Curse of dimensionality – Adding features without sufficient lookback can make genuine neighbors rare.
• Overfitting risk – The script includes a crude overfitting detector (frequent parameter flips) and will fall back to defaults when triggered, but this is only a guardrail.
• Win-rate display – The internal score is illustrative; it does not constitute a tradable backtest.
• Latency vs. smoothness – Smoothing and ML blending reduce noise but add lag; tune to your timeframe and objectives.
Tuning guide
• Short-term scalping – Lower len (10–14), slightly lower multiplier (1.8–2.0), small K (5–8), featureCount 3–4, Adaptive filter ON, moderate strength.
• Swing trading – len (20–30), multiplier ~2.0, K (8–14), featureCount 4–5, Adaptive thresholds ON, filter modest.
• Strong trends – Consider higher adaptive_upper/lower bounds (or let volatility regime do it), keep ML weight moderate so raw %B still reflects surges.
• Chop – Higher ML weight and stronger Adaptive filtering; accept lag in exchange for fewer false extremes.
How to use it responsibly
Treat this as a state descriptor and context filter. Pair it with your execution signals (structure breaks, volume footprints, higher-timeframe bias) and risk management. If mlConfidence is low or stability is falling, lean less on the ML line and more on raw %B or external confirmation.
Summary
Machine Learning BBPct augments a familiar oscillator with a transparent, simplified KNN memory of recent conditions. By blending neighbors’ behavior into %B and adapting thresholds to volatility regime—while exposing confidence, stability, and a plain early-entry heuristic—it provides an informational, probability-minded view of stretch and reversion that you can interpret alongside your own process.
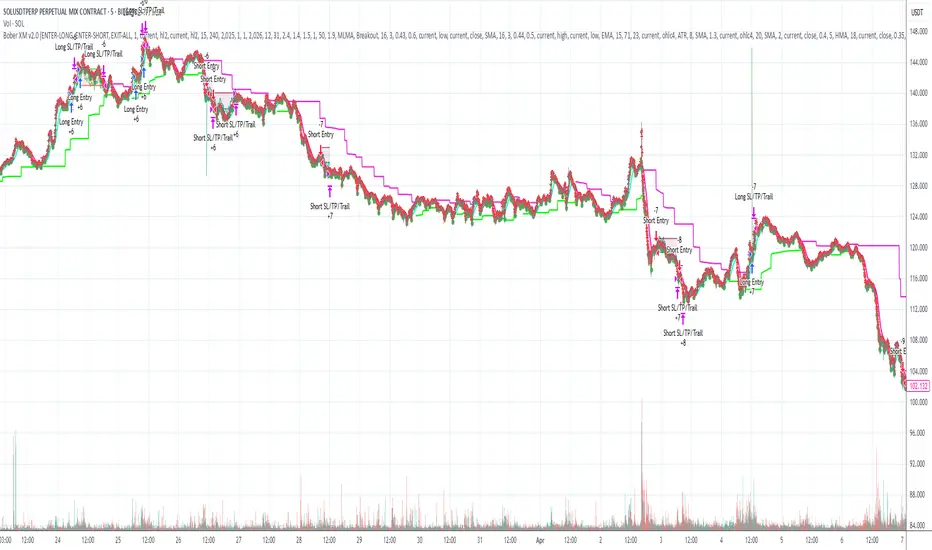
Bober XM v2.0# ₿ober XM v2.0 Trading Bot Documentation
**Developer's Note**: While our previous Bot 1.3.1 was removed due to guideline violations, this setback only fueled our determination to create something even better. Rising from this challenge, Bober XM 2.0 emerges not just as an update, but as a complete reimagining with multi-timeframe analysis, enhanced filters, and superior adaptability. This adversity pushed us to innovate further and deliver a strategy that's smarter, more agile, and more powerful than ever before. Challenges create opportunity - welcome to Cryptobeat's finest work yet.
## !!!!You need to tune it for your own pair and timeframe and retune it periodicaly!!!!!
## Overview
The ₿ober XM v2.0 is an advanced dual-channel trading bot with multi-timeframe analysis capabilities. It integrates multiple technical indicators, customizable risk management, and advanced order execution via webhook for automated trading. The bot's distinctive feature is its separate channel systems for long and short positions, allowing for asymmetric trade strategies that adapt to different market conditions across multiple timeframes.
### Key Features
- **Multi-Timeframe Analysis**: Analyze price data across multiple timeframes simultaneously
- **Dual Channel System**: Separate parameter sets for long and short positions
- **Advanced Entry Filters**: RSI, Volatility, Volume, Bollinger Bands, and KEMAD filters
- **Machine Learning Moving Average**: Adaptive prediction-based channels
- **Multiple Entry Strategies**: Breakout, Pullback, and Mean Reversion modes
- **Risk Management**: Customizable stop-loss, take-profit, and trailing stop settings
- **Webhook Integration**: Compatible with external trading bots and platforms
### Strategy Components
| Component | Description |
|---------|-------------|
| **Dual Channel Trading** | Uses either Keltner Channels or Machine Learning Moving Average (MLMA) with separate settings for long and short positions |
| **MLMA Implementation** | Machine learning algorithm that predicts future price movements and creates adaptive bands |
| **Pivot Point SuperTrend** | Trend identification and confirmation system based on pivot points |
| **Three Entry Strategies** | Choose between Breakout, Pullback, or Mean Reversion approaches |
| **Advanced Filter System** | Multiple customizable filters with multi-timeframe support to avoid false signals |
| **Custom Exit Logic** | Exits based on OBV crossover of its moving average combined with pivot trend changes |
### Note for Novice Users
This is a fully featured real trading bot and can be tweaked for any ticker — SOL is just an example. It follows this structure:
1. **Indicator** – gives the initial signal
2. **Entry strategy** – decides when to open a trade
3. **Exit strategy** – defines when to close it
4. **Trend confirmation** – ensures the trade follows the market direction
5. **Filters** – cuts out noise and avoids weak setups
6. **Risk management** – controls losses and protects your capital
To tune it for a different pair, you'll need to start from scratch:
1. Select the timeframe (candle size)
2. Turn off all filters and trend entry/exit confirmations
3. Choose a channel type, channel source and entry strategy
4. Adjust risk parameters
5. Tune long and short settings for the channel
6. Fine-tune the Pivot Point Supertrend and Main Exit condition OBV
This will generate a lot of signals and activity on the chart. Your next task is to find the right combination of filters and settings to reduce noise and tune it for profitability.
### Default Strategy values
Default values are tuned for: Symbol BITGET:SOLUSDT.P 5min candle
Filters are off by default: Try to play with it to understand how it works
## Configuration Guide
### General Settings
| Setting | Description | Default Value |
|---------|-------------|---------------|
| **Long Positions** | Enable or disable long trades | Enabled |
| **Short Positions** | Enable or disable short trades | Enabled |
| **Risk/Reward Area** | Visual display of stop-loss and take-profit zones | Enabled |
| **Long Entry Source** | Price data used for long entry signals | hl2 (High+Low/2) |
| **Short Entry Source** | Price data used for short entry signals | hl2 (High+Low/2) |
The bot allows you to trade long positions, short positions, or both simultaneously. Each direction has its own set of parameters, allowing for fine-tuned strategies that recognize the asymmetric nature of market movements.
### Multi-Timeframe Settings
1. **Enable Multi-Timeframe Analysis**: Toggle 'Enable Multi-Timeframe Analysis' in the Multi-Timeframe Settings section
2. **Configure Timeframes**: Set appropriate higher timeframes based on your trading style:
- Timeframe 1: Default is now 15 minutes (intraday confirmation)
- Timeframe 2: Default is 4 hours (trend direction)
3. **Select Sources per Indicator**: For each indicator (RSI, KEMAD, Volume, etc.), choose:
- The desired timeframe (current, mtf1, or mtf2)
- The appropriate price type (open, high, low, close, hl2, hlc3, ohlc4)
### Entry Strategies
- **Breakout**: Enter when price breaks above/below the channel
- **Pullback**: Enter when price pulls back to the channel
- **Mean Reversion**: Enter when price is extended from the channel
You can enable different strategies for long and short positions.
### Core Components
### Risk Management
- **Position Size**: Control risk with percentage-based position sizing
- **Stop Loss Options**:
- Fixed: Set a specific price or percentage from entry
- ATR-based: Dynamic stop-loss based on market volatility
- Swing: Uses recent swing high/low points
- **Take Profit**: Multiple targets with percentage allocation
- **Trailing Stop**: Dynamic stop that follows price movement
## Advanced Usage Strategies
### Moving Average Type Selection Guide
- **SMA**: More stable in choppy markets, good for higher timeframes
- **EMA/WMA**: More responsive to recent price changes, better for entry signals
- **VWMA**: Adds volume weighting for stronger trends, use with Volume filter
- **HMA**: Balance between responsiveness and noise reduction, good for volatile markets
### Multi-Timeframe Strategy Approaches
- **Trend Confirmation**: Use higher timeframe RSI (mtf2) for overall trend, current timeframe for entries
- **Entry Precision**: Use KEMAD on current timeframe with volume filter on mtf1
- **False Signal Reduction**: Apply RSI filter on mtf1 with strict KEMAD settings
### Market Condition Optimization
| Market Condition | Recommended Settings |
|------------------|----------------------|
| **Trending** | Use Breakout strategy with KEMAD filter on higher timeframe |
| **Ranging** | Use Mean Reversion with strict RSI filter (mtf1) |
| **Volatile** | Increase ATR multipliers, use HMA for moving averages |
| **Low Volatility** | Decrease noise parameters, use pullback strategy |
## Webhook Integration
The strategy features a professional webhook system that allows direct connectivity to your exchange or trading platform of choice through third-party services like 3commas, Alertatron, or Autoview.
The webhook payload includes all necessary parameters for automated execution:
- Entry price and direction
- Stop loss and take profit levels
- Position size
- Custom identifier for webhook routing
## Performance Optimization Tips
1. **Start with Defaults**: Begin with the default settings for your timeframe before customizing
2. **Adjust One Component at a Time**: Make incremental changes and test the impact
3. **Match MA Types to Market Conditions**: Use appropriate moving average types based on the Market Condition Optimization table
4. **Timeframe Synergy**: Create logical relationships between timeframes (e.g., 5min chart with 15min and 4h higher timeframes)
5. **Periodic Retuning**: Markets evolve - regularly review and adjust parameters
## Common Setups
### Crypto Trend-Following
- MLMA with EMA or HMA
- Higher RSI thresholds (75/25)
- KEMAD filter on mtf1
- Breakout entry strategy
### Stock Swing Trading
- MLMA with SMA for stability
- Volume filter with higher threshold
- KEMAD with increased filter order
- Pullback entry strategy
### Forex Scalping
- MLMA with WMA and lower noise parameter
- RSI filter on current timeframe
- Use highest timeframe for trend direction only
- Mean Reversion strategy
## Webhook Configuration
- **Benefits**:
- Automated trade execution without manual intervention
- Immediate response to market conditions
- Consistent execution of your strategy
- **Implementation Notes**:
- Requires proper webhook configuration on your exchange or platform
- Test thoroughly with small position sizes before full deployment
- Consider latency between signal generation and execution
### Backtesting Period
Define a specific historical period to evaluate the bot's performance:
| Setting | Description | Default Value |
|---------|-------------|---------------|
| **Start Date** | Beginning of backtest period | January 1, 2025 |
| **End Date** | End of backtest period | December 31, 2026 |
- **Best Practice**: Test across different market conditions (bull markets, bear markets, sideways markets)
- **Limitation**: Past performance doesn't guarantee future results
## Entry and Exit Strategies
### Dual-Channel System
A key innovation of the Bober XM is its dual-channel approach:
- **Independent Parameters**: Each trade direction has its own channel settings
- **Asymmetric Trading**: Recognizes that markets often behave differently in uptrends versus downtrends
- **Optimized Performance**: Fine-tune settings for both bullish and bearish conditions
This approach allows the bot to adapt to the natural asymmetry of markets, where uptrends often develop gradually while downtrends can be sharp and sudden.
### Channel Types
#### 1. Keltner Channels
Traditional volatility-based channels using EMA and ATR:
| Setting | Long Default | Short Default |
|---------|--------------|---------------|
| **EMA Length** | 37 | 20 |
| **ATR Length** | 13 | 17 |
| **Multiplier** | 1.4 | 1.9 |
| **Source** | low | high |
- **Strengths**:
- Reliable in trending markets
- Less prone to whipsaws than Bollinger Bands
- Clear visual representation of volatility
- **Weaknesses**:
- Can lag during rapid market changes
- Less effective in choppy, non-trending markets
#### 2. Machine Learning Moving Average (MLMA)
Advanced predictive model using kernel regression (RBF kernel):
| Setting | Description | Options |
|---------|-------------|--------|
| **Source MA** | Price data used for MA calculations | Any price source (low/high/close/etc.) |
| **Moving Average Type** | Type of MA algorithm for calculations | SMA, EMA, WMA, VWMA, RMA, HMA |
| **Trend Source** | Price data used for trend determination | Any price source (close default) |
| **Window Size** | Historical window for MLMA calculations | 5+ (default: 16) |
| **Forecast Length** | Number of bars to forecast ahead | 1+ (default: 3) |
| **Noise Parameter** | Controls smoothness of prediction | 0.01+ (default: ~0.43) |
| **Band Multiplier** | Multiplier for channel width | 0.1+ (default: 0.5-0.6) |
- **Strengths**:
- Predictive rather than reactive
- Adapts quickly to changing market conditions
- Better at identifying trend reversals early
- **Weaknesses**:
- More computationally intensive
- Requires careful parameter tuning
- Can be sensitive to input data quality
### Entry Strategies
| Strategy | Description | Ideal Market Conditions |
|----------|-------------|-------------------------|
| **Breakout** | Enters when price breaks through channel bands, indicating strong momentum | High volatility, emerging trends |
| **Pullback** | Enters when price retraces to the middle band after testing extremes | Established trends with regular pullbacks |
| **Mean Reversion** | Enters at channel extremes, betting on a return to the mean | Range-bound or oscillating markets |
#### Breakout Strategy (Default)
- **Implementation**: Enters long when price crosses above the upper band, short when price crosses below the lower band
- **Strengths**: Captures strong momentum moves, performs well in trending markets
- **Weaknesses**: Can lead to late entries, higher risk of false breakouts
- **Optimization Tips**:
- Increase channel multiplier for fewer but more reliable signals
- Combine with volume confirmation for better accuracy
#### Pullback Strategy
- **Implementation**: Enters long when price pulls back to middle band during uptrend, short during downtrend pullbacks
- **Strengths**: Better entry prices, lower risk, higher probability setups
- **Weaknesses**: Misses some strong moves, requires clear trend identification
- **Optimization Tips**:
- Use with trend filters to confirm overall direction
- Adjust middle band calculation for market volatility
#### Mean Reversion Strategy
- **Implementation**: Enters long at lower band, short at upper band, expecting price to revert to the mean
- **Strengths**: Excellent entry prices, works well in ranging markets
- **Weaknesses**: Dangerous in strong trends, can lead to fighting the trend
- **Optimization Tips**:
- Implement strong trend filters to avoid counter-trend trades
- Use smaller position sizes due to higher risk nature
### Confirmation Indicators
#### Pivot Point SuperTrend
Combines pivot points with ATR-based SuperTrend for trend confirmation:
| Setting | Default Value |
|---------|---------------|
| **Pivot Period** | 25 |
| **ATR Factor** | 2.2 |
| **ATR Period** | 41 |
- **Function**: Identifies significant market turning points and confirms trend direction
- **Implementation**: Requires price to respect the SuperTrend line for trade confirmation
#### Weighted Moving Average (WMA)
Provides additional confirmation layer for entries:
| Setting | Default Value |
|---------|---------------|
| **Period** | 15 |
| **Source** | ohlc4 (average of Open, High, Low, Close) |
- **Function**: Confirms trend direction and filters out low-quality signals
- **Implementation**: Price must be above WMA for longs, below for shorts
### Exit Strategies
#### On-Balance Volume (OBV) Based Exits
Uses volume flow to identify potential reversals:
| Setting | Default Value |
|---------|---------------|
| **Source** | ohlc4 |
| **MA Type** | HMA (Options: SMA, EMA, WMA, RMA, VWMA, HMA) |
| **Period** | 22 |
- **Function**: Identifies divergences between price and volume to exit before reversals
- **Implementation**: Exits when OBV crosses its moving average in the opposite direction
- **Customizable MA Type**: Different MA types provide varying sensitivity to OBV changes:
- **SMA**: Traditional simple average, equal weight to all periods
- **EMA**: More weight to recent data, responds faster to price changes
- **WMA**: Weighted by recency, smoother than EMA
- **RMA**: Similar to EMA but smoother, reduces noise
- **VWMA**: Factors in volume, helpful for OBV confirmation
- **HMA**: Reduces lag while maintaining smoothness (default)
#### ADX Exit Confirmation
Uses Average Directional Index to confirm trend exhaustion:
| Setting | Default Value |
|---------|---------------|
| **ADX Threshold** | 35 |
| **ADX Smoothing** | 60 |
| **DI Length** | 60 |
- **Function**: Confirms trend weakness before exiting positions
- **Implementation**: Requires ADX to drop below threshold or DI lines to cross
## Filter System
### RSI Filter
- **Function**: Controls entries based on momentum conditions
- **Parameters**:
- Period: 15 (default)
- Overbought level: 71
- Oversold level: 23
- Multi-timeframe support: Current, MTF1 (15min), or MTF2 (4h)
- Customizable price source (open, high, low, close, hl2, hlc3, ohlc4)
- **Implementation**: Blocks long entries when RSI > overbought, short entries when RSI < oversold
### Volatility Filter
- **Function**: Prevents trading during excessive market volatility
- **Parameters**:
- Measure: ATR (Average True Range)
- Period: Customizable (default varies by timeframe)
- Threshold: Adjustable multiplier
- Multi-timeframe support
- Customizable price source
- **Implementation**: Blocks trades when current volatility exceeds threshold × average volatility
### Volume Filter
- **Function**: Ensures adequate market liquidity for trades
- **Parameters**:
- Threshold: 0.4× average (default)
- Measurement period: 5 (default)
- Moving average type: Customizable (HMA default)
- Multi-timeframe support
- Customizable price source
- **Implementation**: Requires current volume to exceed threshold × average volume
### Bollinger Bands Filter
- **Function**: Controls entries based on price relative to statistical boundaries
- **Parameters**:
- Period: Customizable
- Standard deviation multiplier: Adjustable
- Moving average type: Customizable
- Multi-timeframe support
- Customizable price source
- **Implementation**: Can require price to be within bands or breaking out of bands depending on strategy
### KEMAD Filter (Kalman EMA Distance)
- **Function**: Advanced trend confirmation using Kalman filter algorithm
- **Parameters**:
- Process Noise: 0.35 (controls smoothness)
- Measurement Noise: 24 (controls reactivity)
- Filter Order: 6 (higher = more smoothing)
- ATR Length: 8 (for bandwidth calculation)
- Upper Multiplier: 2.0 (for long signals)
- Lower Multiplier: 2.7 (for short signals)
- Multi-timeframe support
- Customizable visual indicators
- **Implementation**: Generates signals based on price position relative to Kalman-filtered EMA bands
## Risk Management System
### Position Sizing
Automatically calculates position size based on account equity and risk parameters:
| Setting | Default Value |
|---------|---------------|
| **Risk % of Equity** | 50% |
- **Implementation**:
- Position size = (Account equity × Risk %) ÷ (Entry price × Stop loss distance)
- Adjusts automatically based on volatility and stop placement
- **Best Practices**:
- Start with lower risk percentages (1-2%) until strategy is proven
- Consider reducing risk during high volatility periods
### Stop-Loss Methods
Multiple stop-loss calculation methods with separate configurations for long and short positions:
| Method | Description | Configuration |
|--------|-------------|---------------|
| **ATR-Based** | Dynamic stops based on volatility | ATR Period: 14, Multiplier: 2.0 |
| **Percentage** | Fixed percentage from entry | Long: 1.5%, Short: 1.5% |
| **PIP-Based** | Fixed currency unit distance | 10.0 pips |
- **Implementation Notes**:
- ATR-based stops adapt to changing market volatility
- Percentage stops maintain consistent risk exposure
- PIP-based stops provide precise control in stable markets
### Trailing Stops
Locks in profits by adjusting stop-loss levels as price moves favorably:
| Setting | Default Value |
|---------|---------------|
| **Stop-Loss %** | 1.5% |
| **Activation Threshold** | 2.1% |
| **Trailing Distance** | 1.4% |
- **Implementation**:
- Initial stop remains fixed until profit reaches activation threshold
- Once activated, stop follows price at specified distance
- Locks in profit while allowing room for normal price fluctuations
### Risk-Reward Parameters
Defines the relationship between risk and potential reward:
| Setting | Default Value |
|---------|---------------|
| **Risk-Reward Ratio** | 1.4 |
| **Take Profit %** | 2.4% |
| **Stop-Loss %** | 1.5% |
- **Implementation**:
- Take profit distance = Stop loss distance × Risk-reward ratio
- Higher ratios require fewer winning trades for profitability
- Lower ratios increase win rate but reduce average profit
### Filter Combinations
The strategy allows for simultaneous application of multiple filters:
- **Recommended Combinations**:
- Trending markets: RSI + KEMAD filters
- Ranging markets: Bollinger Bands + Volatility filters
- All markets: Volume filter as minimum requirement
- **Performance Impact**:
- Each additional filter reduces the number of trades
- Quality of remaining trades typically improves
- Optimal combination depends on market conditions and timeframe
### Multi-Timeframe Filter Applications
| Filter Type | Current Timeframe | MTF1 (15min) | MTF2 (4h) |
|-------------|-------------------|-------------|------------|
| RSI | Quick entries/exits | Intraday trend | Overall trend |
| Volume | Immediate liquidity | Sustained support | Market participation |
| Volatility | Entry timing | Short-term risk | Regime changes |
| KEMAD | Precise signals | Trend confirmation | Major reversals |
## Visual Indicators and Chart Analysis
The bot provides comprehensive visual feedback on the chart:
- **Channel Bands**: Keltner or MLMA bands showing potential support/resistance
- **Pivot SuperTrend**: Colored line showing trend direction and potential reversal points
- **Entry/Exit Markers**: Annotations showing actual trade entries and exits
- **Risk/Reward Zones**: Visual representation of stop-loss and take-profit levels
These visual elements allow for:
- Real-time strategy assessment
- Post-trade analysis and optimization
- Educational understanding of the strategy logic
## Implementation Guide
### TradingView Setup
1. Load the script in TradingView Pine Editor
2. Apply to your preferred chart and timeframe
3. Adjust parameters based on your trading preferences
4. Enable alerts for webhook integration
### Webhook Integration
1. Configure webhook URL in TradingView alerts
2. Set up receiving endpoint on your trading platform
3. Define message format matching the bot's output
4. Test with small position sizes before full deployment
### Optimization Process
1. Backtest across different market conditions
2. Identify parameter sensitivity through multiple tests
3. Focus on risk management parameters first
4. Fine-tune entry/exit conditions based on performance metrics
5. Validate with out-of-sample testing
## Performance Considerations
### Strengths
- Adaptability to different market conditions through dual channels
- Multiple layers of confirmation reducing false signals
- Comprehensive risk management protecting capital
- Machine learning integration for predictive edge
### Limitations
- Complex parameter set requiring careful optimization
- Potential over-optimization risk with so many variables
- Computational intensity of MLMA calculations
- Dependency on proper webhook configuration for execution
### Best Practices
- Start with conservative risk settings (1-2% of equity)
- Test thoroughly in demo environment before live trading
- Monitor performance regularly and adjust parameters
- Consider market regime changes when evaluating results
## Conclusion
The ₿ober XM v2.0 represents a significant evolution in trading strategy design, combining traditional technical analysis with machine learning elements and multi-timeframe analysis. The core strength of this system lies in its adaptability and recognition of market asymmetry.
### Market Asymmetry and Adaptive Approach
The strategy acknowledges a fundamental truth about markets: bullish and bearish phases behave differently and should be treated as distinct environments. The dual-channel system with separate parameters for long and short positions directly addresses this asymmetry, allowing for optimized performance regardless of market direction.
### Targeted Backtesting Philosophy
It's counterproductive to run backtests over excessively long periods. Markets evolve continuously, and strategies that worked in previous market regimes may be ineffective in current conditions. Instead:
- Test specific market phases separately (bull markets, bear markets, range-bound periods)
- Regularly re-optimize parameters as market conditions change
- Focus on recent performance with higher weight than historical results
- Test across multiple timeframes to ensure robustness
### Multi-Timeframe Analysis as a Game-Changer
The integration of multi-timeframe analysis fundamentally transforms the strategy's effectiveness:
- **Increased Safety**: Higher timeframe confirmations reduce false signals and improve trade quality
- **Context Awareness**: Decisions made with awareness of larger trends reduce adverse entries
- **Adaptable Precision**: Apply strict filters on lower timeframes while maintaining awareness of broader conditions
- **Reduced Noise**: Higher timeframe data naturally filters market noise that can trigger poor entries
The ₿ober XM v2.0 provides traders with a framework that acknowledges market complexity while offering practical tools to navigate it. With proper setup, realistic expectations, and attention to changing market conditions, it delivers a sophisticated approach to systematic trading that can be continuously refined and optimized.
Machine Learning Trendlines Cluster [LuxAlgo]The ML Trendlines Cluster indicator allows traders to automatically identify trendlines using a machine learning algorithm based on k-means clustering and linear regression, highlighting trendlines from clustered prices.
For trader's convenience, trendlines can be filtered based on their slope, allowing them to filter out trendlines that are too horizontal, or instead keep them depending on the user-selected settings.
🔶 USAGE
Traders only need to set the number of trendlines (clusters) they want the tool to detect and the algorithm will do the rest.
By default the tool is set to detect 4 clusters over the last 500 bars, in the image above it is set to detect 10 clusters over the same period.
This approach only focuses on drawing trendlines from prices that share a common trading range, offering a unique perspective to traditional trendlines. Trendlines with a significant slope can highlight higher dispersion within its cluster.
🔹 Trendline Slope Filtering
Traders can filter trendlines by their slope to display only steep or flat trendlines relative to a user-defined threshold.
The image above shows the three different configurations of this feature:
Filtering disabled
Filter slopes above threshold
Filter slopes below threshold
🔶 DETAILS
K-means clustering is a popular machine-learning algorithm that finds observations in a data set that are similar to each other and places them in a group.
The process starts by randomly assigning each data point to an initial group and calculating the centroid for each. A centroid is the center of the group. K-means clustering forms the groups in such a way that the variances between the data points and the centroid of the cluster are minimized.
The trendlines are displayed according to the linear regression function calculated for each cluster.
🔶 SETTINGS
Window Size: Maximum number of bars to get data from
Clusters: Maximum number of clusters (trendlines) to detect
🔹 Optimization
Maximum Iteration Steps: Maximum loop iterations for cluster computation
🔹 Slope Filter
Threshold Multiplier: Multiplier applied to a volatility measure, higher multiplier equals higher threshold
Filter Slopes: Enable/Disable Trendline Slope Filtering, select to filter trendlines with slopes ABOVE or BELOW the threshold
🔹 Style
Upper Zone: Color to display in the top zone
Lower Zone: Color to display in the bottom zone
Lines: Style for the lines
Size: Line size

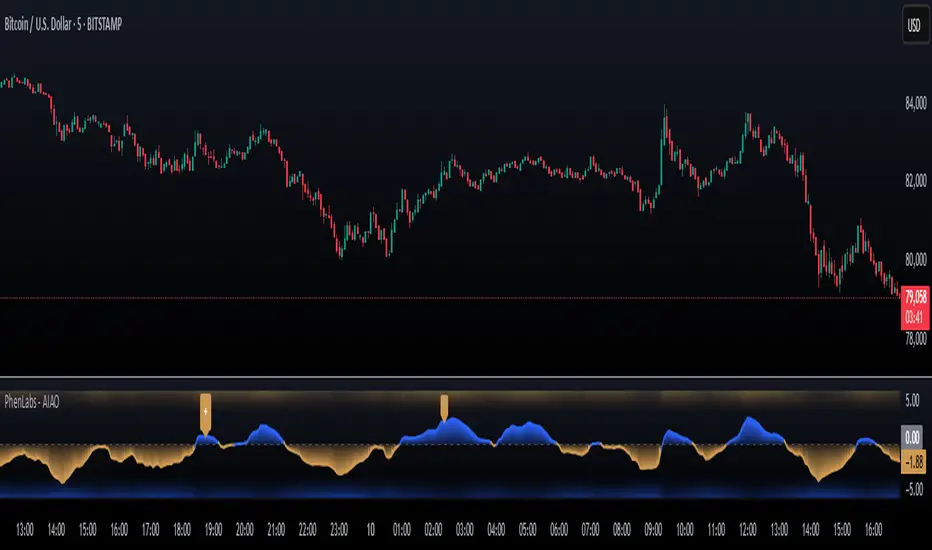
AI Adaptive Oscillator [PhenLabs]📊 Algorithmic Adaptive Oscillator
Version: PineScript™ v6
📌 Description
The AI Adaptive Oscillator is a sophisticated technical indicator that employs ensemble learning and adaptive weighting techniques to analyze market conditions. This innovative oscillator combines multiple traditional technical indicators through an AI-driven approach that continuously evaluates and adjusts component weights based on historical performance. By integrating statistical modeling with machine learning principles, the indicator adapts to changing market dynamics, providing traders with a responsive and reliable tool for market analysis.
🚀 Points of Innovation:
Ensemble learning framework with adaptive component weighting
Performance-based scoring system using directional accuracy
Dynamic volatility-adjusted smoothing mechanism
Intelligent signal filtering with cooldown and magnitude requirements
Signal confidence levels based on multi-factor analysis
🔧 Core Components
Ensemble Framework : Combines up to five technical indicators with performance-weighted integration
Adaptive Weighting : Continuous performance evaluation with automated weight adjustment
Volatility-Based Smoothing : Adapts sensitivity based on current market volatility
Pattern Recognition : Identifies potential reversal patterns with signal qualification criteria
Dynamic Visualization : Professional color schemes with gradient intensity representation
Signal Confidence : Three-tiered confidence assessment for trading signals
🔥 Key Features
The indicator provides comprehensive market analysis through:
Multi-Component Ensemble : Integrates RSI, CCI, Stochastic, MACD, and Volume-weighted momentum
Performance Scoring : Evaluates each component based on directional prediction accuracy
Adaptive Smoothing : Automatically adjusts based on market volatility
Pattern Detection : Identifies potential reversal patterns in overbought/oversold conditions
Signal Filtering : Prevents excessive signals through cooldown periods and minimum change requirements
Confidence Assessment : Displays signal strength through intuitive confidence indicators (average, above average, excellent)
🎨 Visualization
Gradient-Filled Oscillator : Color intensity reflects strength of market movement
Clear Signal Markers : Distinct bullish and bearish pattern signals with confidence indicators
Range Visualization : Clean representation of oscillator values from -6 to 6
Zero Line : Clear demarcation between bullish and bearish territory
Customizable Colors : Color schemes that can be adjusted to match your chart style
Confidence Symbols : Intuitive display of signal confidence (no symbol, +, or ++) alongside direction markers
📖 Usage Guidelines
⚙️ Settings Guide
Color Settings
Bullish Color
Default: #2b62fa (Blue)
This setting controls the color representation for bullish movements in the oscillator. The color appears when the oscillator value is positive (above zero), with intensity indicating the strength of the bullish momentum. A brighter shade indicates stronger bullish pressure.
Bearish Color
Default: #ce9851 (Amber)
This setting determines the color representation for bearish movements in the oscillator. The color appears when the oscillator value is negative (below zero), with intensity reflecting the strength of the bearish momentum. A more saturated shade indicates stronger bearish pressure.
Signal Settings
Signal Cooldown (bars)
Default: 10
Range: 1-50
This parameter sets the minimum number of bars that must pass before a new signal of the same type can be generated. Higher values reduce signal frequency and help prevent overtrading during choppy market conditions. Lower values increase signal sensitivity but may generate more false positives.
Min Change For New Signal
Default: 1.5
Range: 0.5-3.0
This setting defines the minimum required change in oscillator value between consecutive signals of the same type. It ensures that new signals represent meaningful changes in market conditions rather than minor fluctuations. Higher values produce fewer but potentially higher-quality signals, while lower values increase signal frequency.
AI Core Settings
Base Length
Default: 14
Minimum: 2
This fundamental setting determines the primary calculation period for all technical components in the ensemble (RSI, CCI, Stochastic, etc.). It represents the lookback window for each component’s base calculation. Shorter periods create a more responsive but potentially noisier oscillator, while longer periods produce smoother signals with potential lag.
Adaptive Speed
Default: 0.1
Range: 0.01-0.3
Controls how quickly the oscillator adapts to new market conditions through its volatility-adjusted smoothing mechanism. Higher values make the oscillator more responsive to recent price action but potentially more erratic. Lower values create smoother transitions but may lag during rapid market changes. This parameter directly influences the indicator’s adaptiveness to market volatility.
Learning Lookback Period
Default: 150
Minimum: 10
Determines the historical data range used to evaluate each ensemble component’s performance and calculate adaptive weights. This setting controls how far back the AI “learns” from past performance to optimize current signals. Longer periods provide more stable weight distribution but may be slower to adapt to regime changes. Shorter periods adapt more quickly but may overreact to recent anomalies.
Ensemble Size
Default: 5
Range: 2-5
Specifies how many technical components to include in the ensemble calculation.
Understanding The Interaction Between Settings
Base Length and Learning Lookback : The base length determines the reactivity of individual components, while the lookback period determines how their weights are adjusted. These should be balanced according to your timeframe - shorter timeframes benefit from shorter base lengths, while the lookback should generally be 10-15 times the base length for optimal learning.
Adaptive Speed and Signal Cooldown : These settings control sensitivity from different angles. Increasing adaptive speed makes the oscillator more responsive, while reducing signal cooldown increases signal frequency. For conservative trading, keep adaptive speed low and cooldown high; for aggressive trading, do the opposite.
Ensemble Size and Min Change : Larger ensembles provide more stable signals, allowing for a lower minimum change threshold. Smaller ensembles might benefit from a higher threshold to filter out noise.
Understanding Signal Confidence Levels
The indicator provides three distinct confidence levels for both bullish and bearish signals:
Average Confidence (▲ or ▼) : Basic signal that meets the minimum pattern and filtering criteria. These signals indicate potential reversals but with moderate confidence in the prediction. Consider using these as initial alerts that may require additional confirmation.
Above Average Confidence (▲+ or ▼+) : Higher reliability signal with stronger underlying metrics. These signals demonstrate greater consensus among the ensemble components and/or stronger historical performance. They offer increased probability of successful reversals and can be traded with less additional confirmation.
Excellent Confidence (▲++ or ▼++) : Highest quality signals with exceptional underlying metrics. These signals show strong agreement across oscillator components, excellent historical performance, and optimal signal strength. These represent the indicator’s highest conviction trade opportunities and can be prioritized in your trading decisions.
Confidence assessment is calculated through a multi-factor analysis including:
Historical performance of ensemble components
Degree of agreement between different oscillator components
Relative strength of the signal compared to historical thresholds
✅ Best Use Cases:
Identify potential market reversals through oscillator extremes
Filter trade signals based on AI-evaluated component weights
Monitor changing market conditions through oscillator direction and intensity
Confirm trade signals from other indicators with adaptive ensemble validation
Detect early momentum shifts through pattern recognition
Prioritize trading opportunities based on signal confidence levels
Adjust position sizing according to signal confidence (larger for ++ signals, smaller for standard signals)
⚠️ Limitations
Requires sufficient historical data for accurate performance scoring
Ensemble weights may lag during dramatic market condition changes
Higher ensemble sizes require more computational resources
Performance evaluation quality depends on the learning lookback period length
Even high confidence signals should be considered within broader market context
💡 What Makes This Unique
Adaptive Intelligence : Continuously adjusts component weights based on actual performance
Ensemble Methodology : Combines strength of multiple indicators while minimizing individual weaknesses
Volatility-Adjusted Smoothing : Provides appropriate sensitivity across different market conditions
Performance-Based Learning : Utilizes historical accuracy to improve future predictions
Intelligent Signal Filtering : Reduces noise and false signals through sophisticated filtering criteria
Multi-Level Confidence Assessment : Delivers nuanced signal quality information for optimized trading decisions
🔬 How It Works
The indicator processes market data through five main components:
Ensemble Component Calculation :
Normalizes traditional indicators to consistent scale
Includes RSI, CCI, Stochastic, MACD, and volume components
Adapts based on the selected ensemble size
Performance Evaluation :
Analyzes directional accuracy of each component
Calculates continuous performance scores
Determines adaptive component weights
Oscillator Integration :
Combines weighted components into unified oscillator
Applies volatility-based adaptive smoothing
Scales final values to -6 to 6 range
Signal Generation :
Detects potential reversal patterns
Applies cooldown and magnitude filters
Generates clear visual markers for qualified signals
Confidence Assessment :
Evaluates component agreement, historical accuracy, and signal strength
Classifies signals into three confidence tiers (average, above average, excellent)
Displays intuitive confidence indicators (no symbol, +, ++) alongside direction markers
💡 Note:
The AI Adaptive Oscillator performs optimally when used with appropriate timeframe selection and complementary indicators. Its adaptive nature makes it particularly valuable during changing market conditions, where traditional fixed-weight indicators often lose effectiveness. The ensemble approach provides a more robust analysis by leveraging the collective intelligence of multiple technical methodologies. Pay special attention to the signal confidence indicators to optimize your trading decisions - excellent (++) signals often represent the most reliable trade opportunities.
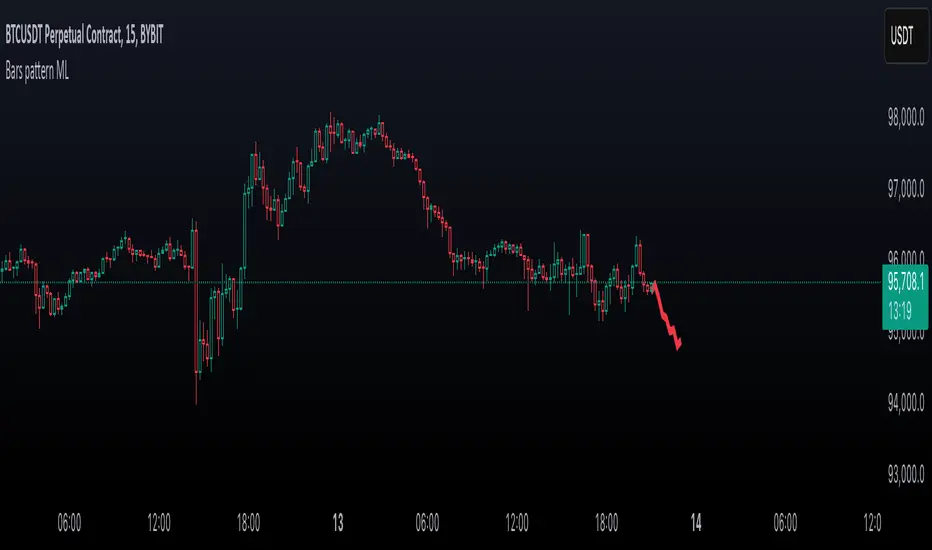
Bars pattern MLThis script implements a K-Nearest Neighbors (KNN)-based machine learning model to predict future price movements in financial markets. It analyzes past price action using Euclidean distance and selects the most similar historical patterns to estimate future price changes. Unlike traditional KNN implementations, this approach optimizes distance calculations by maintaining a dynamically updated list of the closest neighbors, ensuring efficient selection without the need for sorting. The model generates a forecasted price trajectory based on incremental predictions, which are visualized on the chart using polylines for better interpretability.
VWAP Bands with ML [CryptoSea]VWAP Machine Learning Bands is an advanced indicator designed to enhance trading analysis by integrating VWAP with a machine learning-inspired adaptive smoothing approach. This tool helps traders identify trend-based support and resistance zones, predict potential price movements, and generate dynamic trade signals.
Key Features
Adaptive ML VWAP Calculation: Uses a dynamically adjusted SMA-based VWAP model with volatility sensitivity for improved trend analysis.
Forecasting Mechanism: The 'Forecast' parameter shifts the ML output forward, providing predictive insights into potential price movements.
Volatility-Based Band Adjustments: The 'Sigma' parameter fine-tunes the impact of volatility on ML smoothing, adapting to market conditions.
Multi-Tier Standard Deviation Bands: Includes two levels of bands to define potential breakout or mean-reversion zones.
Dynamic Trend-Based Colouring: The VWAP and ML lines change colour based on their relative positions, visually indicating bullish and bearish conditions.
Custom Signal Detection Modes: Allows traders to choose between signals from Band 1, Band 2, or both, for more tailored trade setups.
In the image below, you can see an example of the bands on higher timeframe showing good mean reversion signal opportunities, these tend to work better in ranging markets rather than strong trending ones.
How It Works
VWAP & ML Integration: The script computes VWAP and applies a machine learning-inspired adjustment using SMA smoothing and volatility-based adaptation.
Forecasting Impact: The 'Forecast' setting shifts the ML output forward in time, allowing for anticipatory trend analysis.
Volatility Scaling (Sigma): Adjusts the ML smoothing sensitivity based on market volatility, providing more responsive or stable trend lines.
Trend Confirmation via Colouring: The VWAP line dynamically switches colour depending on whether it is above or below the ML output.
Multi-Level Band Analysis: Two standard deviation-based bands provide a framework for identifying breakouts, trend reversals, or continuation patterns.
In the example below, we can see some of the most reliable signals where we have mean reversion signals from the band whilst the price is also pulling back into the VWAP, these signals have the additional confluence which can give you a higher probabilty move.
Alerts
Bullish Signal Band 1: Alerts when the price crosses above the lower ML Band 1.
Bearish Signal Band 1: Alerts when the price crosses below the upper ML Band 1.
Bullish Signal Band 2: Alerts when the price crosses above the lower ML Band 2.
Bearish Signal Band 2: Alerts when the price crosses below the upper ML Band 2.
Filtered Bullish Signal: Alerts when a bullish signal is triggered based on the selected signal detection mode.
Filtered Bearish Signal: Alerts when a bearish signal is triggered based on the selected signal detection mode.
Application
Trend & Momentum Analysis: Helps traders identify key market trends and potential momentum shifts.
Dynamic Support & Resistance: Standard deviation bands serve as adaptive price zones for potential breakouts or reversals.
Enhanced Trade Signal Confirmation: The integration of ML smoothing with VWAP provides clearer entry and exit signals.
Customizable Risk Management: Allows users to adjust parameters for fine-tuned signal detection, aligning with their trading strategy.
The VWAP Machine Learning Bands indicator offers traders an innovative tool to improve market entries, recognize potential reversals, and enhance trend analysis with intelligent data-driven signals.

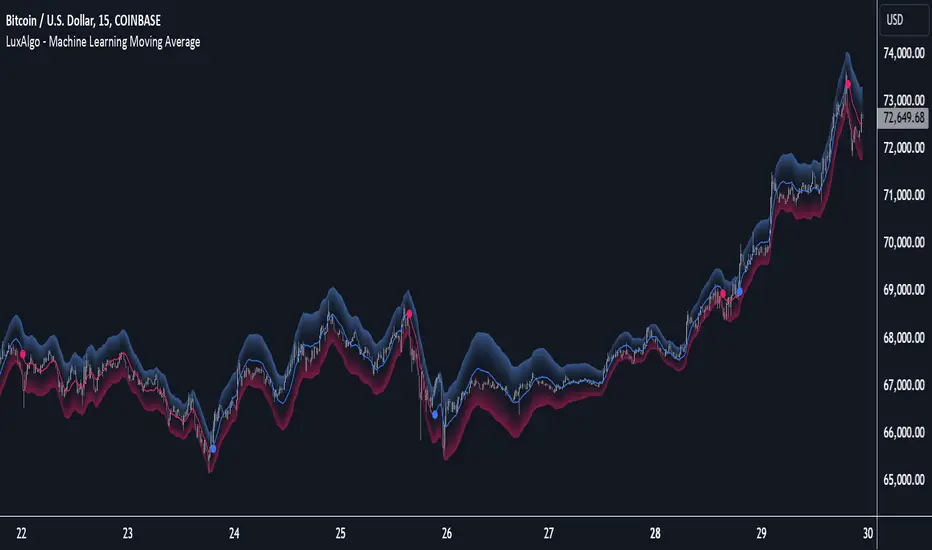
Machine Learning Moving Average [LuxAlgo]The Machine Learning Moving Average (MLMA) is a responsive moving average making use of the weighting function obtained Gaussian Process Regression method. Characteristic such as responsiveness and smoothness can be adjusted by the user from the settings.
The moving average also includes bands, used to highlight possible reversals.
🔶 USAGE
The Machine Learning Moving Average smooths out noisy variations from the price, directly estimating the underlying trend in the price.
A higher "Window" setting will return a longer-term moving average while increasing the "Forecast" setting will affect the responsiveness and smoothness of the moving average, with higher positive values returning a more responsive moving average and negative values returning a smoother but less responsive moving average.
Do note that an excessively high "Forecast" setting will result in overshoots, with the moving average having a poor fit with the price.
The moving average color is determined according to the estimated trend direction based on the bands described below, shifting to blue (default) in an uptrend and fushia (default) in downtrends.
The upper and lower extremities represent the range within which price movements likely fluctuate.
Signals are generated when the price crosses above or below the band extremities, with turning points being highlighted by colored circles on the chart.
🔶 SETTINGS
Window: Calculation period of the moving average. Higher values yield a smoother average, emphasizing long-term trends and filtering out short-term fluctuations.
Forecast: Sets the projection horizon for Gaussian Process Regression. Higher values create a more responsive moving average but will result in more overshoots, potentially worsening the fit with the price. Negative values will result in a smoother moving average.
Sigma: Controls the standard deviation of the Gaussian kernel, influencing weight distribution. Higher Sigma values return a longer-term moving average.
Multiplicative Factor: Adjusts the upper and lower extremity bounds, with higher values widening the bands and lowering the amount of returned turning points.
🔶 RELATED SCRIPTS
Machine-Learning-Gaussian-Process-Regression
SuperTrend-AI-Clustering
Machine Learning RSI [BackQuant]Machine Learning RSI
The Machine Learning RSI is a cutting-edge trading indicator that combines the power of Relative Strength Index (RSI) with Machine Learning (ML) clustering techniques to dynamically determine overbought and oversold thresholds. This advanced indicator adapts to market conditions in real-time, offering traders a robust tool for identifying optimal entry and exit points with increased precision.
Core Concept: Relative Strength Index (RSI)
The RSI is a well-known momentum oscillator that measures the speed and change of price movements, oscillating between 0 and 100. Typically, RSI values above 70 are considered overbought, and values below 30 are considered oversold. However, static thresholds may not be effective in all market conditions.
This script enhances the RSI by integrating a dynamic thresholding system powered by Machine Learning clustering, allowing it to adapt thresholds based on historical RSI behavior and market context.
Machine Learning Clustering for Dynamic Thresholds
The Machine Learning (ML) component uses clustering to calculate dynamic thresholds for overbought and oversold levels. Instead of relying on fixed RSI levels, this indicator clusters historical RSI values into three groups using a percentile-based initialization and iterative optimization:
Cluster 1: Represents lower RSI values (typically associated with oversold conditions).
Cluster 2: Represents mid-range RSI values.
Cluster 3: Represents higher RSI values (typically associated with overbought conditions).
Dynamic thresholds are determined as follows:
Long Threshold: The upper centroid value of Cluster 3.
Short Threshold: The lower centroid value of Cluster 1.
This approach ensures that the indicator adapts to the current market regime, providing more accurate signals in volatile or trending conditions.
Smoothing Options for RSI
To further enhance the effectiveness of the RSI, this script allows traders to apply various smoothing methods to the RSI calculation, including:
Simple Moving Average (SMA)
Exponential Moving Average (EMA)
Weighted Moving Average (WMA)
Hull Moving Average (HMA)
Linear Regression (LINREG)
Double Exponential Moving Average (DEMA)
Triple Exponential Moving Average (TEMA)
Adaptive Linear Moving Average (ALMA)
T3 Moving Average
Traders can select their preferred smoothing method and adjust the smoothing period to suit their trading style and market conditions. The option to smooth the RSI reduces noise and makes the indicator more reliable for detecting trends and reversals.
Long and Short Signals
The indicator generates long and short signals based on the relationship between the RSI value and the dynamic thresholds:
Long Signals: Triggered when the RSI crosses above the long threshold, signaling bullish momentum.
Short Signals: Triggered when the RSI falls below the short threshold, signaling bearish momentum.
These signals are dynamically adjusted to reflect real-time market conditions, making them more robust than static RSI signals.
Visualization and Clustering Insights
The Machine Learning RSI provides an intuitive and visually rich interface, including:
RSI Line: Plotted in real-time, color-coded based on its position relative to the dynamic thresholds (green for long, red for short, gray for neutral).
Dynamic Threshold Lines: The script plots the long and short thresholds calculated by the ML clustering process, providing a clear visual reference for overbought and oversold levels.
Cluster Plots: Each RSI cluster is displayed with distinct colors (green, orange, and red) to give traders insights into how RSI values are grouped and how the dynamic thresholds are derived.
Customization Options
The Machine Learning RSI is highly customizable, allowing traders to tailor the indicator to their preferences:
RSI Settings : Adjust the RSI length, source price, and smoothing method to match your trading strategy.
Threshold Settings : Define the range and step size for clustering thresholds, allowing you to fine-tune the clustering process.
Optimization Settings : Control the performance memory, maximum clustering steps, and maximum data points for ML calculations to ensure optimal performance.
UI Settings : Customize the appearance of the RSI plot, dynamic thresholds, and cluster plots. Traders can also enable or disable candle coloring based on trend direction.
Alerts and Automation
To assist traders in staying on top of market movements, the script includes alert conditions for key events:
Long Signal: When the RSI crosses above the long threshold.
Short Signal: When the RSI crosses below the short threshold.
These alerts can be configured to notify traders in real-time, enabling timely decisions without constant chart monitoring.
Trading Applications
The Machine Learning RSI is versatile and can be applied to various trading strategies, including:
Trend Following: By dynamically adjusting thresholds, this indicator is effective in identifying and following trends in real-time.
Reversal Trading: The ML clustering process helps identify extreme RSI levels, offering reliable signals for reversals.
Range-Bound Trading: The dynamic thresholds adapt to market conditions, making the indicator suitable for trading in sideways markets where static thresholds often fail.
Final Thoughts
The Machine Learning RSI represents a significant advancement in RSI-based trading indicators. By integrating Machine Learning clustering techniques, this script overcomes the limitations of static thresholds, providing dynamic, adaptive signals that respond to market conditions in real-time. With its robust visualization, customizable settings, and alert capabilities, this indicator is a powerful tool for traders seeking to enhance their momentum analysis and improve decision-making.
As always, thorough backtesting and integration into a broader trading strategy are recommended to maximize the effectiveness!
ANN Trend PredictionThis trend indicator utilizes an artificial neural network (ANN) to predict the next market reversal within a certain range of previous candles. The larger the range of previous candles you set, the fewer reversals will be predicted, and trends will tend to last longer.
The ANN is trained on the BTCUSD 4-hour chart, so using it on other assets or timeframes may yield suboptimal results. It takes three input values: the closing price, the Stochastic RSI, and a Choppiness Indicator. Based on these inputs, the ANN categorizes the current candle as part of an uptrend, downtrend, or as undefined.
Compared to an EMA-based trend indicator, this ANN identifies reversals several candles earlier. It achieves this by detecting subtle patterns in the input values that typically appear before a market turnaround. These patterns are somewhat specific to that chosen asset and timeframe.
The results are displayed using rows of triangles that indicate the predicted price direction. The price levels of the triangles correspond to the closing price at the last reversal. The area between the triangle row and the price is colored green if the ANN correctly predicted the move, and red if it did not.
This indicator is designed to showcase the capabilities and potential of ANNs, and is not intended for actual trading use. The ANN can be trained on any other input values, assets and timeframes for several predictions tasks.
You can use the Predicted_Trend_Signal of this Indicator in any backtest indicator. In the Backtester just grap the Predicted_Trend_Signal. downtrend = 1, uptrend = -1, undefined = 0
Feel free to write me a comment.

Machine Learning Cross-Validation Split & Batch HighlighterThis indicator is designed for traders and analysts who employ Machine Learning (ML) techniques for cross-validation in financial markets.
The script visually segments a selected range of historical price data into splits and batches, helping in the assessment of model performance over different market conditions.
User
Theory
In ML, cross-validation is a technique to assess the generalizability of a model, typically by partitioning the data into a set of "folds" or "splits." Each split acts as a validation set, while the others form the training set. This script takes a unique approach by considering the sequential nature of financial time series data, where random shuffling of data (as in traditional cross-validation) can disrupt the temporal order, leading to misleading results.
Chronological Integrity of Splits
Even if the order of the splits is shuffled for cross-validation purposes, the data within each split remains in its original chronological sequence. This feature is crucial for time series analysis, as it respects the inherent order-dependency of financial markets. Thus, each split can be considered a microcosm of market behavior, maintaining the integrity of trends, cycles, and patterns that could be disrupted by random sampling.
The script allows users to define the number of splits and the size of each batch within a split. By doing so, it maintains the chronological sequence of the data, ensuring that the validation set is representative of a future time period that the model would predict.
www.tradingview.com
Parameters
Number of Splits: Defines how many segments the selected data range will be divided into. Each split serves as a standalone testing ground for the ML model. (Up to 24)
Batch Size: Determines the number of bars (candles) in each batch within a split. Smaller batches can help pinpoint overfitting at a finer granularity.
Start Index: The bar index from where the historical data range begins. It sets the starting point for data analysis.
End Index: The bar index where the historical data range ends. It marks the cutoff for data to be included in the model assessment.
Usage
To use this script effectively:
1 - Input the Start Index and End Index to define the historical data range you wish to analyze.
2 - Adjust the Number of Splits to create multiple validation sets for cross-validation.
3 - Set the Batch Size to control the granularity of each validation set within the splits.
4 - The script will highlight the background of each batch within the splits using alternating shades, allowing for a clear visual distinction of the data segmentation.
By maintaining the temporal sequence and allowing for adjustable granularity, the "ML Split and Batch Highlighter" aids in creating a robust validation framework for time series forecasting models in finance.

ML - Momentum Index (Pivots)Building upon the innovative foundations laid by Zeiierman's Machine Learning Momentum Index (MLMI), this variation introduces a series of refinements and new features aimed at bolstering the model's predictive accuracy and responsiveness. Licensed under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0), my adaptation seeks to enhance the original by offering a more nuanced approach to momentum-based trading.
Key Features :
Pivot-Based Analysis: Shifting focus from trend crosses to pivot points, this version employs pivot bars to offer a distinct perspective on market momentum, aiding in the identification of critical reversal points.
Extended Parameter Set: By integrating additional parameters for making predictions, the model gains improved adaptability, allowing for finer tuning to match market conditions.
Dataset Size Limitation: To ensure efficiency and mitigate the risk of calculation timeouts, a cap on the dataset size has been implemented, balancing between comprehensive historical analysis and computational agility.
Enhanced Price Source Flexibility: Users can select between closing prices or (suggested) OHLC4 as the basis for calculations, tailoring the indicator to different analysis preferences and strategies.
This adaptation not only inherits the robust framework of the original MLMI but also introduces innovations to enhance its utility in diverse trading scenarios. Whether you're looking to refine your short-term trading tactics or seeking stable indicators for long-term strategies, the ML - Momentum Index (Pivots) offers a versatile tool to navigate the complexities of the market.
For a deeper understanding of the modifications and to leverage the full potential of this indicator, users are encouraged to explore the tooltips and documentation provided within the script.
The Momentum Indicator calculations have been transitioned to the MLMomentumIndex library, simplifying the process of integration. Users can now seamlessly incorporate the momentumIndexPivots function into their scripts to conduct detailed momentum analysis with ease.

Machine Learning using Neural Networks | EducationalThe script provided is a comprehensive illustration of how to implement and execute a simplistic Neural Network (NN) on TradingView using PineScript.
It encompasses the entire workflow from data input, weight initialization, implicit neuron calculation, feedforward computation, backpropagation for weight adjustments, generating predictions, to visualizing the Mean Squared Error (MSE) Loss Curve for monitoring the training phase.
In the visual example above, you can see that the prediction is not aligned with the actual value. This is intentional for demonstrative purposes, and by incrementing the Epochs or Learning Rate, you will see these two values converge as the accuracy increases.
Hyperparameters:
Learning Rate, Epochs, and the choice between Simple Backpropagation and a verbose version are declared as script inputs, allowing users to tailor the training process.
Initialization:
Random initialization of weight matrices (w1, w2) is performed to ensure asymmetry, promoting effective gradient updates. A seed is added for reproducibility.
Utility Functions:
Functions for matrix randomization, sigmoid activation, MSE loss calculation, data normalization, and standardization are defined to streamline the computation process.
Neural Network Computation:
The feedforward function computes the hidden and output layer values given the input.
Two variants of the backpropagation function are provided for weight adjustment, with one offering a more verbose step-by-step computation of gradients.
A wrapper train_nn function iterates through epochs, performing feedforward, loss computation, and backpropagation in each epoch while logging and collecting loss values.
Training Invocation:
The input data is prepared by normalizing it to a value between 0 and 1 using the maximum standardized value, and the training process is invoked only on the last confirmed bar to preserve computational resources.
Output Forecasting and Visualization:
Post training, the NN's output (predicted price) is computed, standardized and visualized alongside the actual price on the chart.
The MSE loss between the predicted and actual prices is visualized, providing insight into the prediction accuracy.
Optionally, the MSE Loss Curve is plotted on the chart, illustrating the loss trajectory through epochs, assisting in understanding the training performance.
Customizable Visualization:
Various inputs control visualization aspects like Chart Scaling, Chart Horizontal Offset, and Chart Vertical Offset, allowing users to adapt the visualization to their preference.
-------------------------------------------------------
The following is this Neural Network structure, consisting of one hidden layer, with two hidden neurons.
Through understanding the steps outlined in my code, one should be able to scale the NN in any way they like, such as changing the input / output data and layers to fit their strategy ideas.
Additionally, one could forgo the backpropagation function, and load their own trained weights into the w1 and w2 matrices, to have this code run purely for inference.
-------------------------------------------------------
While this demonstration does create a “prediction”, it is on historical data. The purpose here is educational, rather than providing a ready tool for non-programmer consumers.
Normally in Machine Learning projects, the training process would be split into two segments, the Training and the Validation parts. For the purpose of conveying the core concept in a concise and non-repetitive way, I have foregone the Validation part. However, it is merely the application of your trained network on new data (feedforward), and monitoring the loss curve.
Essentially, checking the accuracy on “unseen” data, while training it on “seen” data.
-------------------------------------------------------
I hope that this code will help developers create interesting machine learning applications within the Tradingview ecosystem.

Relational Quadratic Kernel Channel [Vin]The Relational Quadratic Kernel Channel (RQK-Channel-V) is designed to provide more valuable potential price extremes or continuation points in the price trend.
Example:
Usage:
Lookback Window: Adjust the "Lookback Window" parameter to control the number of previous bars considered when calculating the Rational Quadratic Estimate. Longer windows capture longer-term trends, while shorter windows respond more quickly to price changes.
Relative Weight: The "Relative Weight" parameter allows you to control the importance of each data point in the calculation. Higher values emphasize recent data, while lower values give more weight to historical data.
Source: Choose the data source (e.g., close price) that you want to use for the kernel estimate.
ATR Length: Set the length of the Average True Range (ATR) used for channel width calculation. A longer ATR length results in wider channels, while a shorter length leads to narrower channels.
Channel Multipliers: Adjust the "Channel Multiplier" parameters to control the width of the channels. Higher multipliers result in wider channels, while lower multipliers produce narrower channels. The indicator provides three sets of channels, each with its own multiplier for flexibility.
Details:
Rational Quadratic Kernel Function:
The Rational Quadratic Kernel Function is a type of smoothing function used to estimate a continuous curve or line from discrete data points. It is often used in time series analysis to reduce noise and emphasize trends or patterns in the data.
The formula for the Rational Quadratic Kernel Function is generally defined as:
K(x) = (1 + (x^2) / (2 * α * β))^(-α)
Where:
x represents the distance or difference between data points.
α and β are parameters that control the shape of the kernel. These parameters can be adjusted to control the smoothness or flexibility of the kernel function.
In the context of this indicator, the Rational Quadratic Kernel Function is applied to a specified source (e.g., close prices) over a defined lookback window. It calculates a smoothed estimate of the source data, which is then used to determine the central value of the channels. The kernel function allows the indicator to adapt to different market conditions and reduce noise in the data.
The specific parameters (length and relativeWeight) in your indicator allows to fine-tune how the Rational Quadratic Kernel Function is applied, providing flexibility in capturing both short-term and long-term trends in the data.
To know more about unsupervised ML implementations, I highly recommend to follow the users, @jdehorty and @LuxAlgo
Optimizing the parameters:
Lookback Window (length): The lookback window determines how many previous bars are considered when calculating the kernel estimate.
For shorter-term trading strategies, you may want to use a shorter lookback window (e.g., 5-10).
For longer-term trading or investing, consider a longer lookback window (e.g., 20-50).
Relative Weight (relativeWeight): This parameter controls the importance of each data point in the calculation.
A higher relative weight (e.g., 2 or 3) emphasizes recent data, which can be suitable for trend-following strategies.
A lower relative weight (e.g., 1) gives more equal importance to historical and recent data, which may be useful for strategies that aim to capture both short-term and long-term trends.
ATR Length (atrLength): The length of the Average True Range (ATR) affects the width of the channels.
Longer ATR lengths result in wider channels, which may be suitable for capturing broader price movements.
Shorter ATR lengths result in narrower channels, which can be helpful for identifying smaller price swings.
Channel Multipliers (channelMultiplier1, channelMultiplier2, channelMultiplier3): These parameters determine the width of the channels relative to the ATR.
Adjust these multipliers based on your risk tolerance and desired channel width.
Higher multipliers result in wider channels, which may lead to fewer signals but potentially larger price movements.
Lower multipliers create narrower channels, which can result in more frequent signals but potentially smaller price movements.

Machine Learning Regression Trend [LuxAlgo]The Machine Learning Regression Trend tool uses random sample consensus (RANSAC) to fit and extrapolate a linear model by discarding potential outliers, resulting in a more robust fit.
🔶 USAGE
The proposed tool can be used like a regular linear regression, providing support/resistance as well as forecasting an estimated underlying trend.
Using RANSAC allows filtering out outliers from the input data of our final fit, by outliers we are referring to values deviating from the underlying trend whose influence on a fitted model is undesired. For financial prices and under the assumptions of segmented linear trends, these outliers can be caused by volatile moves and/or periodic variations within an underlying trend.
Adjusting the "Allowed Error" numerical setting will determine how sensitive the model is to outliers, with higher values returning a more sensitive model. The blue margin displayed shows the allowed error area.
The number of outliers in the calculation window (represented by red dots) can also be indicative of the amount of noise added to an underlying linear trend in the price, with more outliers suggesting more noise.
Compared to a regular linear regression which does not discriminate against any point in the calculation window, we see that the model using RANSAC is more conservative, giving more importance to detecting a higher number of inliners.
🔶 DETAILS
RANSAC is a general approach to fitting more robust models in the presence of outliers in a dataset and as such does not limit itself to a linear regression model.
This iterative approach can be summarized as follow for the case of our script:
Step 1: Obtain a subset of our dataset by randomly selecting 2 unique samples
Step 2: Fit a linear regression to our subset
Step 3: Get the error between the value within our dataset and the fitted model at time t , if the absolute error is lower than our tolerance threshold then that value is an inlier
Step 4: If the amount of detected inliers is greater than a user-set amount save the model
Repeat steps 1 to 4 until the set number of iterations is reached and use the model that maximizes the number of inliers
🔶 SETTINGS
Length: Calculation window of the linear regression.
Width: Linear regression channel width.
Source: Input data for the linear regression calculation.
🔹 RANSAC
Minimum Inliers: Minimum number of inliers required to return an appropriate model.
Allowed Error: Determine the tolerance threshold used to detect potential inliers. "Auto" will automatically determine the tolerance threshold and will allow the user to multiply it through the numerical input setting at the side. "Fixed" will use the user-set value as the tolerance threshold.
Maximum Iterations Steps: Maximum number of allowed iterations.

Universal Moving Average Convergence DivergenceI changed MACD formula to divergence of (MA26/MA12 - 1).
And its make it more useful.
Cuz:
1) comparability with all other coins with different prices.
2) fix small numbers in low price coines like shiba
3) making a good indicator like RSI to use it for optimization and ML/AI projects as a variable
Most important thing about this indicator is that its Universal
Now you can compare the UMACD of Shiba with Bitcoin without any problem in matamatics space.No need to use virtuality and its important in Optimization problems that we rediuse the problem from a picture to a number(A plot to a list of numbers)
If we don't care about exagrated pumps and dumps, we can say to it Normalized-MACD too. Cuz in normal situations its MAX ≈ 0.1 and MIN ≈ -0.1
WIPNNetworkLibrary "WIPNNetwork"
this is a work in progress (WIP) and prone to have some errors, so use at your own risk...
let me know if you find any issues..
Method for a generalized Neural Network.
network(x) Generalized Neural Network Method.
Parameters:
x : TODO: add parameter x description here
Returns: TODO: add what function returns

FunctionNNLayerLibrary "FunctionNNLayer"
Generalized Neural Network Layer method.
function(inputs, weights, n_nodes, activation_function, bias, alpha, scale) Generalized Layer.
Parameters:
inputs : float array, input values.
weights : float array, weight values.
n_nodes : int, number of nodes in layer.
activation_function : string, default='sigmoid', name of the activation function used.
bias : float, default=1.0, bias to pass into activation function.
alpha : float, default=na, if required to pass into activation function.
scale : float, default=na, if required to pass into activation function.
Returns: float
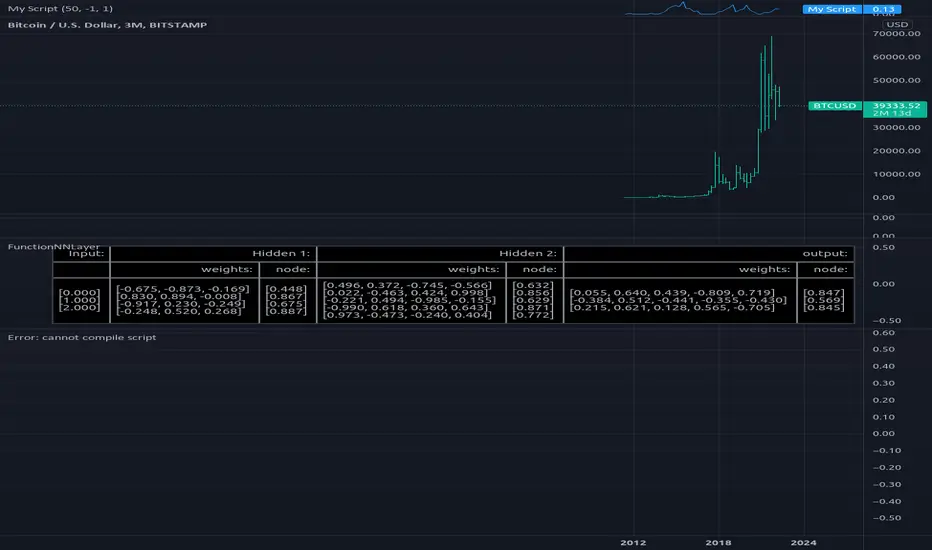
FunctionNNPerceptronLibrary "FunctionNNPerceptron"
Perceptron Function for Neural networks.
function(inputs, weights, bias, activation_function, alpha, scale) generalized perceptron node for Neural Networks.
Parameters:
inputs : float array, the inputs of the perceptron.
weights : float array, the weights for inputs.
bias : float, default=1.0, the default bias of the perceptron.
activation_function : string, default='sigmoid', activation function applied to the output.
alpha : float, default=na, if required for activation.
scale : float, default=na, if required for activation.
@outputs float

MLActivationFunctionsLibrary "MLActivationFunctions"
Activation functions for Neural networks.
binary_step(value) Basic threshold output classifier to activate/deactivate neuron.
Parameters:
value : float, value to process.
Returns: float
linear(value) Input is the same as output.
Parameters:
value : float, value to process.
Returns: float
sigmoid(value) Sigmoid or logistic function.
Parameters:
value : float, value to process.
Returns: float
sigmoid_derivative(value) Derivative of sigmoid function.
Parameters:
value : float, value to process.
Returns: float
tanh(value) Hyperbolic tangent function.
Parameters:
value : float, value to process.
Returns: float
tanh_derivative(value) Hyperbolic tangent function derivative.
Parameters:
value : float, value to process.
Returns: float
relu(value) Rectified linear unit (RELU) function.
Parameters:
value : float, value to process.
Returns: float
relu_derivative(value) RELU function derivative.
Parameters:
value : float, value to process.
Returns: float
leaky_relu(value) Leaky RELU function.
Parameters:
value : float, value to process.
Returns: float
leaky_relu_derivative(value) Leaky RELU function derivative.
Parameters:
value : float, value to process.
Returns: float
relu6(value) RELU-6 function.
Parameters:
value : float, value to process.
Returns: float
softmax(value) Softmax function.
Parameters:
value : float array, values to process.
Returns: float
softplus(value) Softplus function.
Parameters:
value : float, value to process.
Returns: float
softsign(value) Softsign function.
Parameters:
value : float, value to process.
Returns: float
elu(value, alpha) Exponential Linear Unit (ELU) function.
Parameters:
value : float, value to process.
alpha : float, default=1.0, predefined constant, controls the value to which an ELU saturates for negative net inputs. .
Returns: float
selu(value, alpha, scale) Scaled Exponential Linear Unit (SELU) function.
Parameters:
value : float, value to process.
alpha : float, default=1.67326324, predefined constant, controls the value to which an SELU saturates for negative net inputs. .
scale : float, default=1.05070098, predefined constant.
Returns: float
exponential(value) Pointer to math.exp() function.
Parameters:
value : float, value to process.
Returns: float
function(name, value, alpha, scale) Activation function.
Parameters:
name : string, name of activation function.
value : float, value to process.
alpha : float, default=na, if required.
scale : float, default=na, if required.
Returns: float
derivative(name, value, alpha, scale) Derivative Activation function.
Parameters:
name : string, name of activation function.
value : float, value to process.
alpha : float, default=na, if required.
scale : float, default=na, if required.
Returns: float
MLLossFunctionsLibrary "MLLossFunctions"
Methods for Loss functions.
mse(expects, predicts) Mean Squared Error (MSE) " MSE = 1/N * sum ((y - y')^2) ".
Parameters:
expects : float array, expected values.
predicts : float array, prediction values.
Returns: float
binary_cross_entropy(expects, predicts) Binary Cross-Entropy Loss (log).
Parameters:
expects : float array, expected values.
predicts : float array, prediction values.
Returns: float
neutronix community bot ML + Alerts 4h-daily (mod. capissimo)Gm traders,
i have been a python programmer for some years studying artificial intelligence for general purpose; after some time i finally decided to have a look at some finance related stuff and scripts.
Moved by curiosity i've decided to make some but decisive modifications to a script i tried to use initially but without success: the LVQ machine learning strategy.
So after studying the charts and indicators, i have rewritten this script made by Capissimo and added heavy filtering thanks to vwap and vwma, then fixed repaint and other issues.
I hope you enjoy it and that it could increase your possibilities of success in trading.
HOW TO USE THE SCRIPT
Add the script to 3h+ charts like for example BTC 4h, 6h, 8h, 12h, daily. (In order for it to work on shorter timeframes charts you can try to change to lookback window but i dont advise it).
Change only rsi and volfilter(volume filtering) settings to try to find the best winrate. Leave dataset to open. Fyi the winrate isn't 100% accurate but can give you a raw vision of final results.
Use alerts included for trading and and in options click on 'Once per bar'. If you have checked 'Reverse Signals' in the control panel you have got more 'risky' signals so be advised if trading futures and stocks.
Exit trade signals not provided, so it is recommended the use of take profits and stop loss (1.5:1 ratio)
As always, the script is for study purposes. Do not risk more than you can spend!
Original LVQ-based strategy made by capissimo
Modified by gravisxv 13/10/2021