ORB Scalp setup by Unenbat With Signal**ORB Scalp Setup by Unenbat with Signal**
This indicator visualizes a custom Opening Range Breakout (ORB) strategy using a 6-minute range split across the end of one hour and the start of the next. It identifies two key trade setups using 1-hour candles:
* **Reverse Signals:** Triggered when the second 1H candle breaks the previous high/low but closes back inside, signaling a reversal.
* **Continuation Signals:** Triggered when the second 1H candle breaks and closes beyond the previous candle’s range, confirming trend continuation.
SL/TP zones are plotted accordingly, with optional fill coloring. No trades are displayed during "inside bars" or "manipulation" candles.
Forecasting
Auto Trendlines with Break AlertsIdentify the two most recent significant swing highs and swing lows based on a customizable pivot length.
Draw trendlines extending from these points.
Provide an optional visual signal (a small diamond on the chart) and a alertcondition for sound/push notifications when a trendline is broken.
Configure: Once the indicator is on your chart, you can click on the gear icon (⚙️) next to its name to adjust the settings. You will see a checkbox to enable/disable alerts and a slider to change the pivot length.
Configuring Alerts in TradingView
The alertcondition lines in the code allow you to set up official TradingView alerts for sound and push notifications.
Create an Alert: Click the clock icon (⏰) on the right-side toolbar of your TradingView chart.
Set the Condition: In the "Condition" field, select the name of the indicator: "Auto Trendlines with Break Alerts".
Choose the Alert Type: A second dropdown will appear. Select either "High Trendline Broken" or "Low Trendline Broken" to specify which break you want to be alerted for.
Select Notification Options: In the "Notifications" section, you can check the boxes for "Play sound," "Send email," "Send push notification," etc.
Create the Alert: Click "Create" to save your alert.
ACR(Average Candle Range) With TargetsWhat is ACR?
The Average Candle Range (ACR) is a custom volatility metric that calculates the mean distance between the high and low of a set number of past candles. ACR focuses only on the actual candle range (high - low) of specific past candles on a chosen timeframe.
This script calculates and visualizes the Average Candle Range (ACR) over a user-defined number of candles on a custom timeframe. It displays a table of recent range values, plots dynamic bullish and bearish target levels, and marks the start of each new candle with a vertical line. All calculations update in real time as price action develops. This script was inspired by the “ICT ADR Levels - Judas x Daily Range Meter°” by toodegrees.
Key Features
Custom Timeframe Selection: Choose any timeframe (e.g., 1D, 4H, 15m) for analysis.
User-Defined Lookback: Calculate the average range across 1 to 10 previous candles.
Dynamic Targets:
Bullish Target: Current candle low + ACR.
Bearish Target: Current candle high – ACR.
Live Updates: Targets adjust intrabar as highs or lows change during the current candle.
Candle Start Markers: Vertical lines denote the open of each new candle on the selected timeframe.
Floating Range Table:
Displays the current ACR value.
Lists individual ranges for the previous five candles.
Extend Target Lines: Choose to extend bullish and bearish target levels fully across the screen.
Global Visibility Controls: Toggle on/off all visual elements (targets, vertical lines, and table) for a cleaner view.
How It Works
At each new candle on the user-selected timeframe, the script:
Draws a vertical line at the candle’s open.
Recalculates the ACR based on the inputted previous number of candles.
Plots target levels using the current candle's developing high and low values.
Limitation
Once the price has already moved a full ACR in the opposite direction from your intended trade, the associated target loses its practical value. For example, if you intended to trade long but the bearish ACR target is hit first, the bullish target is no longer a reliable reference for that session.
Use Case
This tool is designed for traders who:
Want to visualize the average movement range of candles over time.
Use higher or lower timeframe candles as structural anchors.
Require real-time range-based price levels for intraday or swing decision-making.
This script does not generate entry or exit signals. Instead, it supports range awareness and target projection based on historical candle behavior.
Key Difference from Similar Tools
While this script was inspired by “ICT ADR Levels - Judas x Daily Range Meter°” by toodegrees, it introduces a major enhancement: the ability to customize the timeframe used for calculating the range. Most ADR or candle-range tools are locked to a single timeframe (e.g., daily), but this version gives traders full control over the analysis window. This makes it adaptable to a wide range of strategies, including intraday and swing trading, across any market or asset.

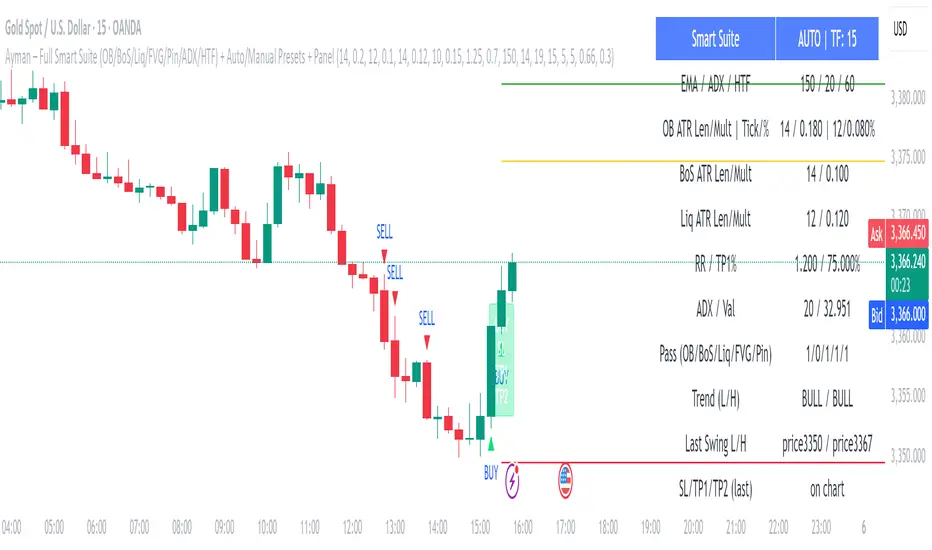
Ayman – Full Smart Suite Auto/Manual Presets + PanelIndicator Name
Ayman – Full Smart Suite (OB/BoS/Liq/FVG/Pin/ADX/HTF) + Auto/Manual Presets + Panel
This is a multi-condition trading tool for TradingView that combines advanced Smart Money Concepts (SMC) with classic technical filters.
It generates BUY/SELL signals, draws Stop Loss (SL) and Take Profit (TP1, TP2) levels, and displays a control panel with all active settings and conditions.
1. Main Features
Smart Money Concepts Filters:
Order Block (OB) Zones
Break of Structure (BoS)
Liquidity Sweeps
Fair Value Gaps (FVG)
Pin Bar patterns
ADX filter
Higher Timeframe EMA filter (HTF EMA)
Two Operating Modes:
Auto Presets: Automatically adjusts all settings (buffers, ATR multipliers, RR, etc.) based on your chart timeframe (M1/M5/M15).
Manual Mode: Fully customize all parameters yourself.
Trade Management Levels:
Stop Loss (SL)
TP1 – partial profit
TP2 – full profit
Visual Panel showing:
Current settings
Filter status
Trend direction
Last swing levels
SL/TP status
Alerts for BUY/SELL conditions
2. Entry Conditions
A BUY signal is generated when all these are true:
Trend: Price above EMA (bullish)
HTF EMA: Higher timeframe trend also bullish
ADX: Trend strength above threshold
OB: Price in a valid bullish Order Block zone
BoS: Structure break to the upside
Liquidity Sweep: Sweep of recent lows in bullish context
FVG: A bullish Fair Value Gap is present
Pin Bar: Bullish Pin Bar pattern detected (if enabled)
A SELL signal is generated when the opposite conditions are met.
3. Stop Loss & Take Profits
SL: Placed just beyond the last swing low (BUY) or swing high (SELL), with a small ATR buffer.
TP1: Partial profit target, defined as a ratio of the SL distance.
TP2: Full profit target, based on Reward:Risk ratio.
4. How to Use
Step 1 – Apply Indicator
Open TradingView
Go to your chart (recommended: XAUUSD, M1/M5 for scalping)
Add the indicator script
Step 2 – Choose Mode
AUTO Mode: Leave “Use Auto Presets” ON – parameters adapt to your timeframe.
MANUAL Mode: Turn Auto OFF and adjust all lengths, buffers, RR, and filters.
Step 3 – Filters
In the Filters On/Off section, enable/disable specific conditions (OB, BoS, Liq, FVG, Pin Bar, ADX, HTF EMA).
Step 4 – Trading the Signals
Wait for a BUY or SELL arrow to appear.
SL and TP levels will be plotted automatically.
TP1 can be used for partial close and TP2 for full exit.
Step 5 – Alerts
Set alerts via BUY Signal or SELL Signal to receive notifications.
5. Best Practices
Scalping: Use M1 or M5 with AUTO mode for gold or forex pairs.
Swing Trading: Use M15+ and adjust buffers/ATR manually.
Combine with price action confirmation before entering trades.
For higher accuracy, wait for multiple filter confirmations rather than acting on the first arrow.
6. Summary Table
Feature Purpose Can Disable?
Order Block Finds key supply/demand zones ✅
Break of Structure Detects trend continuation ✅
Liquidity Sweep Finds stop-hunt moves ✅
Fair Value Gap Confirms imbalance entries ✅
Pin Bar Price action reversal filter ✅
ADX Trend strength filter ✅
HTF EMA Higher timeframe confirmation ✅
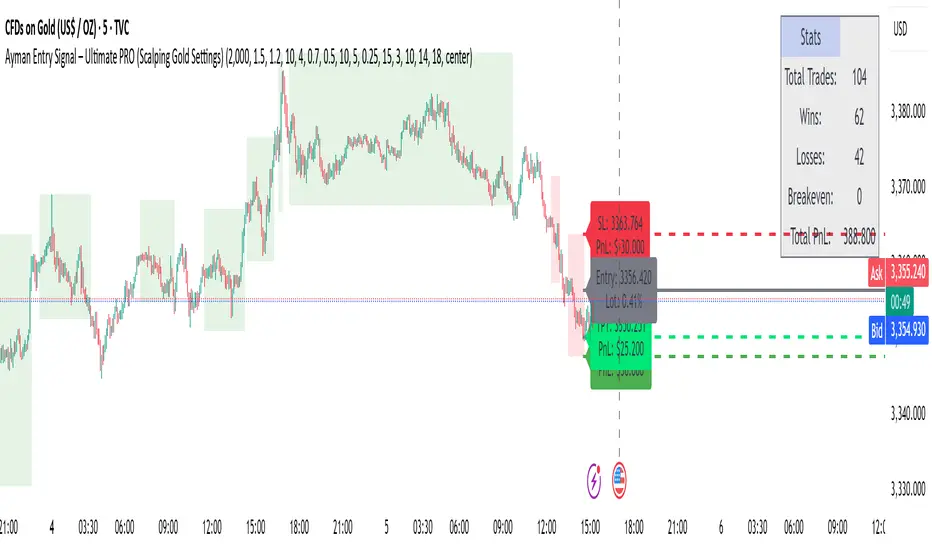
Ayman Entry Signal – Ultimate PRO (Scalping Gold Settings)1. Overview
This indicator is a professional gold scalping tool built for TradingView using Pine Script v6.
It combines multiple price action and technical filters to generate high-probability Buy/Sell signals with built-in trade management features (TP1, TP2, SL, Break Even, Partial Close, Stats tracking).
It is optimized for XAUUSD but can be applied to other assets with proper setting adjustments.
2. Key Features
Multi-Condition Trade Signals – EMA trend, Break of Structure, Order Blocks, FVG, Liquidity Sweeps, Pin Bars, Higher Timeframe confirmation, Trend Cloud, SMA Cross, and ADX.
Full Trade Management – Auto-calculates lot size, SL, TP1, TP2, Break Even, Partial Close.
Dynamic Chart Drawing – Entry lines, SL/TP lines, trade boxes, and real-time PnL.
Statistics Panel – Tracks wins, losses, breakeven trades, and total PnL over selected dates.
Customizable Filters – All filters can be turned ON/OFF to match your strategy.
3. Main Inputs & Settings
Account Settings
Capital ($) – Total trading capital.
Risk Percentage (%) – Risk per trade.
TP to SL Ratio – Risk-to-reward ratio.
Value Per Point ($) – Value per pip/point for lot size calculation.
SL Buffer – Extra points added to SL to avoid stop hunts.
Take Profit Settings
TP1 % of Full Target – Fraction of TP1 compared to TP2.
Move SL to Entry after TP1? – Activates Break Even after TP1.
Break Even Buffer – Extra points when moving SL to BE.
Take Partial Close at TP1 – Option to close half at TP1.
Signal Filters
ATR Period – For SL/TP calculation buffer.
EMA Trend – Uses EMA 9/21 crossover for trend.
Break of Structure (BoS) – Requires structure break confirmation.
Order Block (OB) – Validates trades within OB zones.
Fair Value Gap (FVG) – Confirms trades inside FVGs.
Liquidity Sweep – Checks if liquidity zones are swept.
Pin Bar Confirmation – Uses candlestick patterns for extra confirmation.
Pin Bar Body Ratio – Controls strictness of Pin Bar filter.
Higher Timeframe Filters (HTF)
HTF EMA Confirmation – Confirms lower timeframe trades with higher timeframe trend.
HTF BoS – Confirms with higher timeframe structure break.
HTF Timeframe – Selects higher timeframe.
Advanced Filters
SuperTrend Filter – Confirms trades based on SuperTrend.
ADX Filter – Filters out low volatility periods.
SMA Cross Filter – Uses SMA 8/9 cross as filter.
Trend Cloud Filter – Uses EMA 50/200 as a cloud trend filter.
4. How It Works
Buy Signal Conditions
EMA 9 > EMA 21 (trend bullish)
Optional filters (BoS, OB, FVG, Liquidity Sweep, Pin Bar, HTF confirmations, ADX, SMA Cross, Trend Cloud) must pass if enabled.
When all active filters pass → Buy signal triggers.
Sell Signal Conditions
EMA 9 < EMA 21 (trend bearish)
Same filtering process but for bearish conditions.
When all active filters pass → Sell signal triggers.
5. Trade Execution & Management
When a signal triggers:
Lot size is auto-calculated based on risk % and SL distance.
SL is placed beyond recent swing high/low + ATR buffer.
TP1 and TP2 are calculated from the SL using the reward-to-risk ratio.
Break Even: If enabled, SL moves to entry price after TP1 is hit.
Partial Close: If enabled, half of the position closes at TP1.
Trade Exit: Full exit at TP2, SL hit, or partial close at TP1.
6. Chart Display
Entry Line – Shows entry price.
SL Line – Red dashed line at stop loss level.
TP1 Line – Lime dashed line for TP1.
TP2 Line – Green dashed line for TP2.
PnL Labels – Displays real-time profit/loss in $.
Trade Box – Visual area showing trade range.
Pin Bar Shapes – Optional, marks Pin Bars.
7. Statistics Panel
Stats Header – Shows “Stats”.
Total Trades
Wins
Losses
Breakeven Trades
Total PnL
Can be reset or filtered by date.
8. How to Use
Load the Indicator in TradingView.
Select Gold (XAUUSD) on your preferred scalping timeframe (1m, 5m, 15m).
Adjust settings:
Use default gold scalping settings for quick start.
Enable/disable filters according to your style.
Wait for a Buy/Sell alert.
Confirm visually that all desired conditions align.
Place trade with calculated lot size, SL, and TP levels shown on chart.
Let trade run – the indicator manages Break Even & Partial Close if enabled.
9. Recommended Timeframes
Scalping: 1m, 5m, 15m
Day Trading: 15m, 30m, 1H
Swing: 4H, Daily (adjust settings accordingly)
Crypto Options Greeks & Volatility Analyzer [BackQuant]Crypto Options Greeks & Volatility Analyzer
Overview
The Crypto Options Greeks & Volatility Analyzer is a comprehensive analytical tool that calculates Black-Scholes option Greeks up to the third order for Bitcoin and Ethereum options. It integrates implied volatility data from VOLMEX indices and provides multiple visualization layers for options risk analysis.
Quick Introduction to Options Trading
Options are financial derivatives that give the holder the right, but not the obligation, to buy or sell an underlying asset at a predetermined price (strike price) within a specific time period (expiration date). Understanding options requires grasping two fundamental concepts:
Call Options : Give the right to buy the underlying asset at the strike price. Calls increase in value when the underlying price rises above the strike price.
Put Options : Give the right to sell the underlying asset at the strike price. Puts increase in value when the underlying price falls below the strike price.
The Language of Options: Greeks
Options traders use "Greeks" - mathematical measures that describe how an option's price changes in response to various factors:
Delta : How much the option price moves for each $1 change in the underlying
Gamma : How fast delta changes as the underlying moves
Theta : Daily time decay - how much value erodes each day
Vega : Sensitivity to implied volatility changes
Rho : Sensitivity to interest rate changes
These Greeks are essential for understanding risk. Just as a pilot needs instruments to fly safely, options traders need Greeks to navigate market conditions and manage positions effectively.
Why Volatility Matters
Implied volatility (IV) represents the market's expectation of future price movement. High IV means:
Options are more expensive (higher premiums)
Market expects larger price swings
Better for option sellers
Low IV means:
Options are cheaper
Market expects smaller moves
Better for option buyers
This indicator helps you visualize and quantify these critical concepts in real-time.
Back to the Indicator
Key Features & Components
1. Complete Greeks Calculations
The indicator computes all standard Greeks using the Black-Scholes-Merton model adapted for cryptocurrency markets:
First Order Greeks:
Delta (Δ) : Measures the rate of change of option price with respect to underlying price movement. Ranges from 0 to 1 for calls and -1 to 0 for puts.
Vega (ν) : Sensitivity to implied volatility changes, expressed as price change per 1% change in IV.
Theta (Θ) : Time decay measured in dollars per day, showing how much value erodes with each passing day.
Rho (ρ) : Interest rate sensitivity, measuring price change per 1% change in risk-free rate.
Second Order Greeks:
Gamma (Γ) : Rate of change of delta with respect to underlying price, indicating how quickly delta will change.
Vanna : Cross-derivative measuring delta's sensitivity to volatility changes and vega's sensitivity to price changes.
Charm : Delta decay over time, showing how delta changes as expiration approaches.
Vomma (Volga) : Vega's sensitivity to volatility changes, important for volatility trading strategies.
Third Order Greeks:
Speed : Rate of change of gamma with respect to underlying price (∂Γ/∂S).
Zomma : Gamma's sensitivity to volatility changes (∂Γ/∂σ).
Color : Gamma decay over time (∂Γ/∂T).
Ultima : Third-order volatility sensitivity (∂²ν/∂σ²).
2. Implied Volatility Analysis
The indicator includes a sophisticated IV ranking system that analyzes current implied volatility relative to its recent history:
IV Rank : Percentile ranking of current IV within its 30-day range (0-100%)
IV Percentile : Percentage of days in the lookback period where IV was lower than current
IV Regime Classification : Very Low, Low, High, or Very High
Color-Coded Headers : Visual indication of volatility regime in the Greeks table
Trading regime suggestions based on IV rank:
IV Rank > 75%: "Favor selling options" (high premium environment)
IV Rank 50-75%: "Neutral / Sell spreads"
IV Rank 25-50%: "Neutral / Buy spreads"
IV Rank < 25%: "Favor buying options" (low premium environment)
3. Gamma Zones Visualization
Gamma zones display horizontal price levels where gamma exposure is highest:
Purple horizontal lines indicate gamma concentration areas
Opacity scaling : Darker shading represents higher gamma values
Percentage labels : Shows gamma intensity relative to ATM gamma
Customizable zones : 3-10 price levels can be analyzed
These zones are critical for understanding:
Pin risk around expiration
Potential for explosive price movements
Optimal strike selection for gamma trading
Market maker hedging flows
4. Probability Cones (Expected Move)
The probability cones project expected price ranges based on current implied volatility:
1 Standard Deviation (68% probability) : Shown with dashed green/red lines
2 Standard Deviations (95% probability) : Shown with dotted green/red lines
Time-scaled projection : Cones widen as expiration approaches
Lognormal distribution : Accounts for positive skew in asset prices
Applications:
Strike selection for credit spreads
Identifying high-probability profit zones
Setting realistic price targets
Risk management for undefined risk strategies
5. Breakeven Analysis
The indicator plots key price levels for options positions:
White line : Strike price
Green line : Call breakeven (Strike + Premium)
Red line : Put breakeven (Strike - Premium)
These levels update dynamically as option premiums change with market conditions.
6. Payoff Structure Visualization
Optional P&L labels display profit/loss at expiration for various price levels:
Shows P&L at -2 sigma, -1 sigma, ATM, +1 sigma, and +2 sigma price levels
Separate calculations for calls and puts
Helps visualize option payoff diagrams directly on the chart
Updates based on current option premiums
Configuration Options
Calculation Parameters
Asset Selection : BTC or ETH (limited by VOLMEX IV data availability)
Expiry Options : 1D, 7D, 14D, 30D, 60D, 90D, 180D
Strike Mode : ATM (uses current spot) or Custom (manual strike input)
Risk-Free Rate : Adjustable annual rate for discounting calculations
Display Settings
Greeks Display : Toggle first, second, and third-order Greeks independently
Visual Elements : Enable/disable probability cones, gamma zones, P&L labels
Table Customization : Position (6 options) and text size (4 sizes)
Price Levels : Show/hide strike and breakeven lines
Technical Implementation
Data Sources
Spot Prices : INDEX:BTCUSD and INDEX:ETHUSD for underlying prices
Implied Volatility : VOLMEX:BVIV (Bitcoin) and VOLMEX:EVIV (Ethereum) indices
Real-Time Updates : All calculations update with each price tick
Mathematical Framework
The indicator implements the full Black-Scholes-Merton model:
Standard normal distribution approximations using Abramowitz and Stegun method
Proper annualization factors (365-day year)
Continuous compounding for interest rate calculations
Lognormal price distribution assumptions
Alert Conditions
Four categories of automated alerts:
Price-Based : Underlying crossing strike price
Gamma-Based : 50% surge detection for explosive moves
Moneyness : Deep ITM alerts when |delta| > 0.9
Time/Volatility : Near expiration and vega spike warnings
Practical Applications
For Options Traders
Monitor all Greeks in real-time for active positions
Identify optimal entry/exit points using IV rank
Visualize risk through probability cones and gamma zones
Track time decay and plan rolls
For Volatility Traders
Compare IV across different expiries
Identify mean reversion opportunities
Monitor vega exposure across strikes
Track higher-order volatility sensitivities
Conclusion
The Crypto Options Greeks & Volatility Analyzer transforms complex mathematical models into actionable visual insights. By combining institutional-grade Greeks calculations with intuitive overlays like probability cones and gamma zones, it bridges the gap between theoretical options knowledge and practical trading application.
Whether you're:
A directional trader using options for leverage
A volatility trader capturing IV mean reversion
A hedger managing portfolio risk
Or simply learning about options mechanics
This tool provides the quantitative foundation needed for informed decision-making in cryptocurrency options markets.
Remember that options trading involves substantial risk and complexity. The Greeks and visualizations provided by this indicator are tools for analysis - they should be combined with proper risk management, position sizing, and a thorough understanding of options strategies.
As crypto options markets continue to mature and grow, having professional-grade analytics becomes increasingly important. This indicator ensures you're equipped with the same analytical capabilities used by institutional traders, adapted specifically for the unique characteristics of 24/7 cryptocurrency markets.

DeltaTrace ForecastDeltaTrace Forecast is a forward-looking projection tool that visualizes the probable directional path of price using a multi-timeframe momentum model rooted in volatility-adjusted nonlinear dynamics. Rather than relying on traditional indicators that react to price after the fact, DeltaTrace estimates future price motion by tracing the progression of momentum changes across expanding timeframes—then scaling those deltas using adaptive volatility to forecast a plausible path forward.
At its core, DeltaTrace constructs a momentum vector from a series of smoothed z-scores derived from increasing multiples of the current chart's timeframe. These z-scores are normalized using a hyperbolic tangent function (tanh), which compresses extreme values and emphasizes meaningful deviations without being overly sensitive to outliers. This nonlinear normalization ensures that explosive moves are weighted with less distortion, while still preserving the shape and direction of the underlying trend.
Once the z-scores are calculated for a range of 12 timeframes (from 1× the current timeframe up to 12×), the indicator computes the first difference between each adjacent pair. These differences—or deltas—represent the change in momentum from one timeframe to the next. In this structure, a strong positive delta implies momentum is strengthening as we look into higher timeframes, while a negative delta reflects waning or reversing strength.
However, not all deltas are treated equally. To make the projection adaptive to market volatility and temporally meaningful, each delta is scaled by the square root of its corresponding timeframe multiple, weighted by the ATR (Average True Range) of the base timeframe. This square-root volatility scaling mirrors the behavior of Brownian motion and reflects the natural geometric diffusion of price over time. By applying this scaling, the model tempers its forecast according to recent volatility while maintaining proportional distance over longer time horizons.
The result is a chain of projected price steps—11 in total—starting from the current closing price. These steps are cumulative, meaning each one builds upon the previous, forming a continuously adjusted polyline that represents the most recent forecast path of price. Each point in the forecast line is directional: if the next projected point is above the last, the segment is colored green (upward momentum); if below, it is colored red (downward momentum). This color coding gives immediate visual feedback on the nature of the projected path and allows for intuitive at-a-glance interpretation.
What makes DeltaTrace unique is its combination of ideas from signal processing, time-series momentum analysis, and volatility theory. Instead of relying on static support/resistance levels or lagging moving averages, it dynamically adapts to both momentum curvature and volatility structure. This allows it to be used not just for trend confirmation, but also for top-down bias fading, reversal anticipation, and path-following strategies.
Traders can use DeltaTrace in a variety of ways depending on their style:
For trend traders, a consistent upward or downward curve in the forecast suggests directional continuation and can be used for position sizing or confirmation of bias.
For mean-reversion traders, exaggerated divergence between the current price and the first few forecast points may indicate temporary exhaustion or overextension.
For scalpers or intraday traders, the short-term bend or flattening of the initial segments can reveal early signs of weakening momentum or build-up before breakout.
For swing traders, the full shape of the polyline gives an evolving map of market rhythm across time compression, allowing for context-aware decision-making.
It’s important to understand that this is a path projection tool, not a precise price target predictor. The forecast does not attempt to predict exact price levels at exact bars, but rather illustrates how the market might evolve if the current multi-timeframe momentum structure persists. Like all models, it should be interpreted probabilistically and used in conjunction with other confirmation signals, risk management tools, or strategy frameworks.
Inputs allow customization of the z-score calculation length and ATR window to tune the sensitivity of the model. The color scheme for up/down forecast segments can also be adjusted for personal preference. Additionally, users can toggle the polyline forecast on or off, which may be useful for pairing this indicator with others in a crowded chart layout.
Because the forecast path is calculated only on the last bar, it does not repaint or shift once the candle closes—preserving historical accuracy for visual inspection and backtesting reference. However, it is also sensitive to changes in volatility and momentum structure, meaning it updates each bar as conditions evolve, making it most effective in real-time decision support.
DeltaTrace Forecast is particularly well-suited for traders who want a deeper understanding of hidden momentum shifts across timeframes without relying on traditional trend-following tools. It reveals the shape of future possibility based on present dynamics, offering a compact yet powerful visualization of directional bias, transition risk, and path strength.
To maximize its utility, consider pairing DeltaTrace with volume profiles, order flow tools, higher timeframe zones, or market structure indicators. Used in context, it becomes a powerful companion to both systematic and discretionary trading styles—especially for those who appreciate a blend of mathematics and intuition in their market analysis.
This indicator is not based on magic or black-box logic; every component—from the z-score standardization to the volatility-adjusted deltas—is fully transparent and grounded in simple, interpretable mechanics. If you're looking for a reliable way to visualize multi-timeframe bias and momentum diffusion, DeltaTrace provides a unique lens through which to interpret future potential in an ever-shifting market landscape.

Power Metcalfe's + Fibonacci Channel## Metcalfe's Law + Fibonacci Channel - Optimized Bitcoin Valuation Model
This indicator presents an enhanced variation of the classic Bitcoin Metcalfe's Law model, combining logarithmic regression analysis with Fibonacci retracement levels to create a comprehensive valuation framework.
**Key Features:**
- **Optimized Metcalfe's Law calculation** using historical cycle data (2013-2022) for improved accuracy
- **Fibonacci channel overlay** with key levels: 0.382, 0.618, 1.272, 1.618, 2.000, 2.618, 3.000
- **Dynamic trading zones** with visual buy/sell signals based on price position relative to the channel
- **Real-time targets** displaying current Fibonacci projections and fair value estimates
**What makes it different:**
Unlike standard Metcalfe's Law implementations, this version integrates logarithmic growth principles and uses a refined dataset that accounts for Bitcoin's maturation cycles. The Fibonacci overlay provides clearer entry/exit points while maintaining the long-term growth trajectory based on network adoption.
**Best suited for:** Long-term Bitcoin holders and macro traders looking for mathematical support/resistance levels based on network adoption dynamics and scarcity.
The model automatically updates calculations and provides a comprehensive information table showing current formula parameters and key price targets.

MSTY-WNTR Rebalancing SignalMSTY-WNTR Rebalancing Signal
## Overview
The **MSTY-WNTR Rebalancing Signal** is a custom TradingView indicator designed to help investors dynamically allocate between two YieldMax ETFs: **MSTY** (YieldMax MSTR Option Income Strategy ETF) and **WNTR** (YieldMax Short MSTR Option Income Strategy ETF). These ETFs are tied to MicroStrategy (MSTR) stock, which is heavily influenced by Bitcoin's price due to MSTR's significant Bitcoin holdings.
MSTY benefits from upward movements in MSTR (and thus Bitcoin) through a covered call strategy that generates income but caps upside potential. WNTR, on the other hand, provides inverse exposure, profiting from MSTR declines but losing in rallies. This indicator uses Bitcoin's momentum and MSTR's relative strength to signal when to hold MSTY (bullish phases), WNTR (bearish phases), or stay neutral, aiming to optimize returns by switching allocations at key turning points.
Inspired by strategies discussed in crypto communities (e.g., X posts analyzing MSTR-linked ETFs), this indicator promotes an active rebalancing approach over a "set and forget" buy-and-hold strategy. In simulated backtests over the past 12 months (as of August 4, 2025), the optimized version has shown potential to outperform holding 100% MSTY or 100% WNTR alone, with an illustrative APY of ~125% vs. ~6% for MSTY and ~-15% for WNTR in one scenario.
**Important Disclaimer**: This is not financial advice. Past performance does not guarantee future results. Always consult a financial advisor. Trading involves risk, and you could lose money. The indicator is for educational and informational purposes only.
## Key Features
- **Momentum-Based Signals**: Uses a Simple Moving Average (SMA) on Bitcoin's price to detect bullish (price > SMA) or bearish (price < SMA) trends.
- **RSI Confirmation**: Incorporates MSTR's Relative Strength Index (RSI) to filter signals, avoiding overbought conditions for MSTY and oversold for WNTR.
- **Visual Cues**:
- Green upward triangle for "Hold MSTY".
- Red downward triangle for "Hold WNTR".
- Yellow cross for "Switch" signals.
- Background color: Green for MSTY, red for WNTR.
- **Information Panel**: A table in the top-right corner displays real-time data: BTC Price, SMA value, MSTR RSI, and current Allocation (MSTY, WNTR, or Neutral).
- **Alerts**: Configurable alerts for holding MSTY, holding WNTR, or switching.
- **Optimized Parameters**: Defaults are tuned (SMA: 10 days, RSI: 15 periods, Overbought: 80, Oversold: 20) based on simulations to reduce whipsaws and capture trends effectively.
## How It Works
The indicator's logic is straightforward yet effective for volatile assets like Bitcoin and MSTR:
1. **Primary Trigger (Bitcoin Momentum)**:
- Calculate the SMA of Bitcoin's closing price (default: 10-day).
- Bullish: Current BTC price > SMA → Potential MSTY hold.
- Bearish: Current BTC price < SMA → Potential WNTR hold.
2. **Secondary Filter (MSTR RSI Confirmation)**:
- Compute RSI on MSTR stock (default: 15-period).
- For bullish signals: If RSI > Overbought (80), signal Neutral (avoid overextended rallies).
- For bearish signals: If RSI < Oversold (20), signal Neutral (avoid capitulation bottoms).
3. **Allocation Rules**:
- Hold 100% MSTY if bullish and not overbought.
- Hold 100% WNTR if bearish and not oversold.
- Neutral otherwise (e.g., during choppy or extreme markets) – consider holding cash or avoiding trades.
4. **Rebalancing**:
- Switch signals trigger when the hold changes (e.g., from MSTY to WNTR).
- Recommended frequency: Weekly reviews or on 5% BTC moves to minimize trading costs (aim for 4-6 trades/year).
This approach leverages Bitcoin's influence on MSTR while mitigating the risks of MSTY's covered call drag during downtrends and WNTR's losses in uptrends.
## Setup and Usage
1. **Chart Requirements**:
- Apply this indicator to a Bitcoin chart (e.g., BTCUSD on Binance or Coinbase, daily timeframe recommended).
- Ensure MSTR stock data is accessible (TradingView supports it natively).
2. **Adding to TradingView**:
- Open the Pine Editor.
- Paste the script code.
- Save and add to your chart.
- Customize inputs if needed (e.g., adjust SMA/RSI lengths for different timeframes).
3. **Interpretation**:
- **Green Background/Triangle**: Allocate 100% to MSTY – Bitcoin is in an uptrend, MSTR not overbought.
- **Red Background/Triangle**: Allocate 100% to WNTR – Bitcoin in downtrend, MSTR not oversold.
- **Yellow Switch Cross**: Rebalance your portfolio immediately.
- **Neutral (No Signal)**: Panel shows "Neutral" – Hold cash or previous position; reassess weekly.
- Monitor the panel for key metrics to validate signals manually.
4. **Backtesting and Strategy Integration**:
- Convert to a strategy script by changing `indicator()` to `strategy()` and adding entry/exit logic for automated testing.
- In simulations (e.g., using Python or TradingView's backtester), it has outperformed buy-and-hold in volatile markets by ~100-200% relative APY, but results vary.
- Factor in fees: ETF expense ratios (~0.99%), trading commissions (~$0.40/trade), and slippage.
5. **Risk Management**:
- Use with a diversified portfolio; never allocate more than you can afford to lose.
- Add stop-losses (e.g., 10% trailing) to protect against extreme moves.
- Rebalance sparingly to avoid over-trading in sideways markets.
- Dividends: Reinvest MSTY/WNTR payouts into the current hold for compounding.
## Performance Insights (Simulated as of August 4, 2025)
Based on synthetic backtests modeling the last 12 months:
- **Optimized Strategy APY**: ~125% (by timing switches effectively).
- **Hold 100% MSTY APY**: ~6% (gains from BTC rallies offset by downtrends).
- **Hold 100% WNTR APY**: ~-15% (losses in bull phases outweigh bear gains).
In one scenario with stronger volatility, the strategy achieved ~4533% APY vs. 10% for MSTY and -34% for WNTR, highlighting its potential in dynamic markets. However, these are illustrative; real results depend on actual BTC/MSTR movements. Test thoroughly on historical data.
## Limitations and Considerations
- **Data Dependency**: Relies on accurate BTC and MSTR data; delays or gaps can affect signals.
- **Market Risks**: Bitcoin's volatility can lead to false signals (whipsaws); the RSI filter helps but isn't perfect.
- **No Guarantees**: This indicator doesn't predict the future. MSTR's correlation to BTC may change (e.g., due to regulatory events).
- **Not for All Users**: Best for intermediate/advanced traders familiar with ETFs and crypto. Beginners should paper trade first.
- **Updates**: As of August 4, 2025, this is version 1.0. Future updates may include volume filters or EMA options.
If you find this indicator useful, consider leaving a like or comment on TradingView. Feedback welcome for improvements!

EMA9/EMA50 Cross Alert (2H Only)התראה לקרוס של ממוצע נא אקספוננציאלי 9 ו 50 ל 2 הכיוונים בטיים פרם של שעתיים.
Alert for a collapse of the 9 and 50 exponential moving averages in both directions on a two-hour time frame.
Volume Based Analysis V 1.00
Volume Based Analysis V1.00 – Multi-Scenario Buyer/Seller Power & Volume Pressure Indicator
Description:
1. Overview
The Volume Based Analysis V1.00 indicator is a comprehensive tool for analyzing market dynamics using Buyer Power, Seller Power, and Volume Pressure scenarios. It detects 12 configurable scenarios combining volume-based calculations with price action to highlight potential bullish or bearish conditions.
When used in conjunction with other technical tools such as Ichimoku, Bollinger Bands, and trendline analysis, traders can gain a deeper and more reliable understanding of the market context surrounding each signal.
2. Key Features
12 Configurable Scenarios covering Buyer/Seller Power convergence, divergence, and dominance
Advanced Volume Pressure Analysis detecting when both buy/sell volumes exceed averages
Global Lookback System ensuring consistency across all calculations
Dominance Peak Module for identifying strongest buyer/seller dominance at structural pivots
Real-time Signal Statistics Table showing bullish/bearish counts and volume metrics
Fully customizable inputs (SMA lengths, multipliers, timeframes)
Visual chart markers (S01 to S12) for clear on-chart identification
3. Usage Guide
Enable/Disable Scenarios: Choose which signals to display based on your trading strategy
Fine-tune Parameters: Adjust SMA lengths, multipliers, and lookback periods to fit your market and timeframe
Timeframe Control: Use custom lower timeframes for refined up/down volume calculations
Combine with Other Indicators:
Ichimoku: Confirm volume-based bullish signals with cloud breakouts or trend confirmation
Bollinger Bands: Validate divergence/convergence signals with overbought/oversold zones
Trendlines: Spot high-probability signals at breakout or retest points
Signal Tables & Peaks: Read buy/sell volume dominance at a glance, and activate the Dominance Peak Module to highlight key turning points.
4. Example Scenarios & Suggested Images
Image #1 – S01 Bullish Convergence Above Zero
S01 activated, Buyer Power > 0, both buyer power slope & price slope positive, above-average buy volume. Show S01 ↑ marker below bar.
Image #2 – Combined with Ichimoku
Display a bullish scenario where price breaks above Ichimoku cloud while S01 or S09 bullish signal is active. Highlight both the volume-based marker and Ichimoku cloud breakout.
Image #3 – Combined with Bollinger Bands & Trendlines
Show a bearish S10 signal at the upper Bollinger Band near a descending trendline resistance. Highlight the confluence of the volume pressure signal with the band touch and trendline rejection.
Image #4 – Dominance Peak Module
Pivot low with green ▲ Bull Peak and pivot high with red ▼ Bear Peak, showing strong dominance counts.
Image #5 – Statistics Table in Action
Bottom-left table showing buy/sell volume, averages, and bullish/bearish counts during an active market phase.
5. Feedback & Collaboration
Your feedback and suggestions are welcome — they help improve and refine this system. If you discover interesting use cases or have ideas for new features, please share them in the script’s comments section on TradingView.
6. Disclaimer
This script is for educational purposes only. It is not financial advice. Past performance does not guarantee future results. Always do your own analysis before making trading decisions.
Tip: Use this tool alongside trend confirmation indicators for the most robust signal interpretation.

Advanced Forex Currency Strength Meter
# Advanced Forex Currency Strength Meter
🚀 The Ultimate Currency Strength Analysis Tool for Forex Traders
This sophisticated indicator measures and compares the relative strength of major currencies (EUR, GBP, USD, JPY, CHF, CAD, AUD, NZD) to help you identify the strongest and weakest currencies in real-time, providing clear trading signals based on currency strength differentials.
## 📊 What This Indicator Does
The Advanced Forex Currency Strength Meter analyzes currency relationships across 28+ major forex pairs and 8 currency indices to determine which currencies are gaining or losing strength. Instead of relying on individual pair analysis, this tool gives you a bird's-eye view of the entire forex market, helping you:
Identify the strongest and weakest currencies at any given time
Find high-probability trading opportunities by pairing strong vs weak currencies
Avoid ranging markets by detecting when currencies have similar strength
Get clear LONG/SHORT/NEUTRAL signals for your current trading pair
Optimize your trading strategy based on your preferred timeframe and holding period
## ⚙️ How The Indicator Works
### Dual Calculation Method
The indicator uses a sophisticated dual approach for maximum accuracy:
Pairs-Based Analysis: Calculates currency strength from 28+ major forex pairs (EURUSD, GBPUSD, USDJPY, etc.)
Index-Based Analysis: Incorporates official currency indices (DXY, EXY, BXY, JXY, CXY, AXY, SXY, ZXY)
Weighted Combination: Blends both methods using smart weighting for enhanced accuracy
### Smart Auto-Optimization System
The indicator automatically adjusts its parameters based on your chart timeframe and intended holding period:
The system recognizes that scalping requires different sensitivity than swing trading, automatically optimizing lookback periods, analysis timeframes, signal thresholds, and index weights.
### Strength Calculation Process
Fetches price data from multiple timeframes using optimized tuple requests
Calculates percentage change over the specified lookback period
Optionally normalizes by ATR (Average True Range) to account for volatility differences
Combines pair-based and index-based calculations using dynamic weighting
Generates relative strength by comparing base currency vs quote currency
Produces clear trading signals when strength differential exceeds threshold
## 🎯 How To Use The Indicator
### Quick Start
Add the indicator to any forex pair chart
Enable 🧠 Smart Auto-Optimization (recommended for beginners)
Watch for LONG 🚀 signals when the relative strength line is green and above threshold
Watch for SHORT 🐻 signals when the relative strength line is red and below threshold
Avoid trading during NEUTRAL ⚪ periods when currencies have similar strength
Note: This is highly recommended to couple this indicator with fundamental analysis and use it as an extra signal.
### 📋 Parameters Reference
#### 🤖 Smart Settings
🧠 Smart Auto-Optimization: (Default: Enabled) Automatically optimizes all parameters based on chart timeframe and trading style
#### ⚙️ Manual Override
These settings are only active when Smart Auto-Optimization is disabled:
Manual Lookback Period: (Default: 14) Number of periods to analyze for strength calculation
Manual ATR Period: (Default: 14) Period for ATR normalization calculation
Manual Analysis Timeframe: (Default: 240) Higher timeframe for strength analysis
Manual Index Weight: (Default: 0.5) Weight given to currency indices vs pairs (0.0 = pairs only, 1.0 = indices only)
Manual Signal Threshold: (Default: 0.5) Minimum strength differential required for trading signals
#### 📊 Display
Show Signal Markers: (Default: Enabled) Display triangle markers when signals change
Show Info Label: (Default: Enabled) Show comprehensive information label with current analysis
#### 🔍 Analysis
Use ATR Normalization: (Default: Enabled) Normalize strength calculations by volatility for fairer comparison
#### 💰 Currency Indices
💰 Use Currency Indices: (Default: Enabled) Include all 8 currency indices in strength calculation for enhanced accuracy
#### 🎨 Colors
Strong Currency Color: (Default: Green) Color for positive/strong signals
Weak Currency Color: (Default: Red) Color for negative/weak signals
Neutral Color: (Default: Gray) Color for neutral conditions
Strong/Weak Backgrounds: Background colors for clear signal visualization
### 🧠 Smart Optimization Profiles
The indicator automatically selects optimal parameters based on your chart timeframe:
#### ⚡ Scalping Profile (1M-5M Charts)
For positions held for a few minutes:
Lookback: 5 periods (fast/sensitive)
Analysis Timeframe: 15 minutes
Index Weight: 20% (favor pairs for speed)
Signal Threshold: 0.3% (sensitive triggers)
#### 📈 Intraday Profile (10M-1H Charts)
For positions held for a few hours:
Lookback: 12 periods (balanced sensitivity)
Analysis Timeframe: 4 hours
Index Weight: 40% (balanced approach)
Signal Threshold: 0.4% (moderate sensitivity)
#### 📊 Swing Profile (4H-Daily Charts)
For positions held for a few days:
Lookback: 21 periods (stable analysis)
Analysis Timeframe: Daily
Index Weight: 60% (favor indices for stability)
Signal Threshold: 0.5% (conservative triggers)
#### 📆 Position Profile (Weekly+ Charts)
For positions held for a few weeks:
Lookback: 30 periods (long-term view)
Analysis Timeframe: Weekly
Index Weight: 70% (heavily favor indices)
Signal Threshold: 0.6% (very conservative)
### Entry Timing
Wait for clear LONG 🚀 or SHORT 🐻 signals
Avoid trading during NEUTRAL ⚪ periods
Look for signal confirmations on multiple timeframes
### Risk Management
Stronger signals (higher relative strength values) suggest higher probability trades
Use appropriate position sizing based on signal strength
Consider the trading style profile when setting stop losses and take profits
💡 Pro Tip: The indicator works best when combined with your existing technical analysis. Use currency strength to identify which pairs to trade, then use your favorite technical indicators to determine when to enter and exit.
## 🔧 Key Features
28+ Forex Pairs Analysis: Comprehensive coverage of major currency relationships
8 Currency Indices Integration: DXY, EXY, BXY, JXY, CXY, AXY, SXY, ZXY for enhanced accuracy
Smart Auto-Optimization: Automatically adapts to your trading style and timeframe
ATR Normalization: Fair comparison across different currency pairs and volatility levels
Real-Time Signals: Clear LONG/SHORT/NEUTRAL signals with visual markers
Performance Optimized: Efficient tuple-based data requests minimize external calls
User-Friendly Interface: Simplified settings with comprehensive tooltips
Multi-Timeframe Support: Works on any timeframe from 1-minute to monthly charts
Transform your forex trading with the power of currency strength analysis! 🚀

AymaN Entry Signal – With HTF + Pin Bar + Multi TP + BE + V1Ayman Entry Signal – Indicator Description
Overview
Ayman Entry Signal – With HTF + Pin Bar + Multi TP + BE + Stats Panel (V1)
This is a professional-grade Pine Script indicator designed for scalping and intraday trading, with full trade management, multi-confirmation logic, and advanced visualization. The tool is ideal for traders focused on XAUUSD (Gold), Forex, and other volatile instruments who seek both precision entries and structured exits with dynamic risk control.
Main Features
Advanced Entry Logic:
- EMA fast/slow crossovers (configurable)
- Optional conditions: Break of Structure (BoS), Order Block (OB), Fair Value Gap (FVG), Liquidity sweeps, Pin Bars
- HTF confirmation using EMA or BoS
- Real-time entry condition display
Trade Management:
- Dynamic calculation of Entry, SL (with ATR buffer), TP1, TP2
- Supports Partial Close and Break Even logic after TP1
- Visual PnL label (dynamic and color-coded)
Statistics Panel:
- Shows total trades, win/loss/breakeven count, cumulative PnL
- Filter by custom date or session
- Fully customizable panel appearance
Trade Visualization:
- Trade box includes all trade levels (Entry, SL, TP1, TP2)
- Visual display of trade conditions and PnL result
- Option to keep previous trades on chart
Alert System:
- Alerts for Buy and Sell entries
- Compatible with webhook automation systems like MT5/MT4
Customization & Inputs
- Capital & risk per trade
- Value per pip/point
- SL buffer (ATR-based)
- Manual EMA override
- Enable/disable: EMA, BoS, OB, FVG, Liquidity, Pin Bars
- HTF: timeframe + confirmation logic
- Trade box/labels visibility
- Full color customization
- PnL label position: top, center, or bottom
Recommended Use
- Ideal for Gold scalping (XAUUSD), also effective for Forex
- Best on 1m–15m charts; use HTF confirmation from 15m–4H
- Pairs well with semi-automated systems using alerts and webhooks
Disclaimer
Note: This is a non-executing indicator. It does not place trades but provides visual and statistical guidance for professional manual or semi-automated trading.

EMA Cross Approach ScreenerWorks best on D/4H. Signals when the price of a stock is below the 200ema and the 9 and 20 are sloping up approaching the 200 while being 5% or less than from the 200. Helps the trader find a good buying point while keeping risk minimum.

Global M2 Money Supply // Days Offset =This is the original version.. there is no update... just needed to re-install the script.

ATR % Line from LoD/HoDATR % Line Trading Indicator - Entry Filter Tool
This Pine Script creates a sophisticated ATR (Average True Range) percentage-based entry filter indicator for TradingView that helps traders avoid buying overextended stocks and identify optimal entry zones based on volatility.
Core Functionality - Entry Discipline
The script calculates a maximum entry threshold by taking a percentage of the Average True Range (ATR) and projecting it from the current day's low. This creates a dynamic "no-buy zone" that adapts to market volatility, helping traders avoid purchasing stocks that have already moved too far from their daily base.
Key Calculation:
Measures the ATR over a specified period (default: 14 bars)
Takes a user-defined percentage of that ATR (default: 25%)
Projects this distance from the day's low to establish a maximum entry threshold
Entry Rule: Avoid buying when price exceeds this ATR% level from the daily low or high.
Visual Features
Entry Threshold Line:
Draws a horizontal line at the calculated maximum entry level
Line extends forward for clear visualization of the "no-buy zone"
Red zones above this line indicate overextended conditions
Fully customizable appearance with color, width, and style options
Smart Entry Alerts:
Optional labels show the ATR percentage threshold and exact price level
Visual confirmation when stocks are trading in acceptable entry zones vs. extended areas
Real-Time Monitoring Table:
Displays current distance from daily low as ATR percentage
Shows whether current price is in "safe entry zone" or "extended territory"
Customizable display options for clean chart analysis
Practical Applications for Entry Management
Avoiding Extended Entries:
Primary Use: Don't initiate long positions when price is more than X% ATR from the daily low
Prevents buying stocks that have already made their daily move
Reduces risk of buying at temporary tops within the trading session
Entry Zone Identification:
Price trading below the ATR% line = potential entry opportunity
Price trading above the ATR% line = wait for pullback or skip the trade
Combines volatility analysis with momentum discipline
Risk Management Benefits:
Improved Entry Timing: Enter closer to daily support levels
Better Risk/Reward: Shorter distance to stop loss (daily low)
Reduced Chasing: Systematic approach prevents FOMO-driven entries
Volatility Awareness: Higher volatility stocks get wider acceptable entry ranges
Configuration for Entry Filtering
Key Settings for Entry Management:
ATR Percentage: Set your maximum acceptable extension (15-30% common for day trading)
Reference Point: Use "Low" to measure extension from daily base
Line Style: Make highly visible to clearly see entry threshold
Alert Integration: Visual confirmation of entry-friendly zones
Typical Usage Scenarios:
Conservative Entries: 15-20% ATR from daily low
Moderate Extensions: 25-35% ATR for stronger momentum plays
Aggressive Setups: 40%+ ATR for breakout situations (use with caution)
Entry Strategy Integration
Pre-Market Planning:
Set ATR% threshold based on stock's typical volatility
Identify key levels where entries become unfavorable
Plan alternative entry strategies for extended stocks
Intraday Execution:
Monitor real-time ATR% extension from daily low
Avoid new long positions when threshold is exceeded
Wait for pullbacks to re-enter acceptable entry zones
This tool transforms volatility analysis into practical entry discipline, helping traders maintain consistent entry standards and avoid the costly mistake of chasing overextended stocks. By respecting ATR-based extension limits, traders can improve their entry timing and overall trade profitability.


Market Energy – Trend vs Retest (with Saturation %)Market Energy – Trend vs Retest Indicator
This indicator measures the bullish and bearish energy in the market based on volume-weighted price changes.
It calculates two smoothed energy waves — bullish energy and bearish energy — using exponential moving averages of volume-adjusted price movements.
The indicator detects trend changes and retests by comparing the relative strength of these waves.
A saturation percentage quantifies the intensity of the current dominant side (bulls or bears) relative to recent highs.
- High saturation (>70%) indicates strong momentum and dominance by bulls or bears.
- Low saturation (<30%) suggests weak momentum and possible market indecision or consolidation.
The background color highlights the current control: green for bulls, red for bears, with transparency indicating the saturation level.
A label shows which side is currently in control along with the saturation percentage for quick interpretation.
Use this tool to identify strong trends, possible retests, and momentum strength to support your trading decisions.

Market Energy – Trend vs RetestShows who is in control of the market. The red lines are sellers in control and the green are the buyers in control
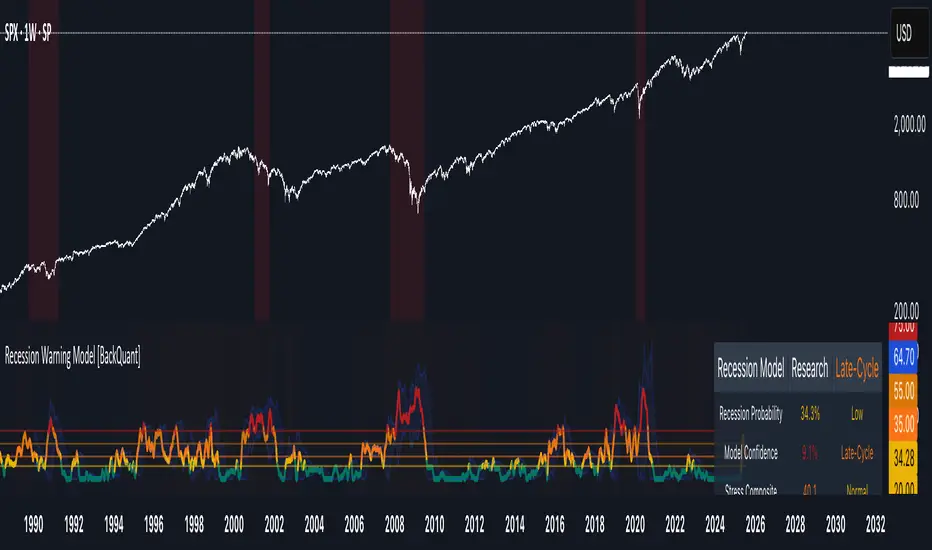
Recession Warning Model [BackQuant]Recession Warning Model
Overview
The Recession Warning Model (RWM) is a Pine Script® indicator designed to estimate the probability of an economic recession by integrating multiple macroeconomic, market sentiment, and labor market indicators. It combines over a dozen data series into a transparent, adaptive, and actionable tool for traders, portfolio managers, and researchers. The model provides customizable complexity levels, display modes, and data processing options to accommodate various analytical requirements while ensuring robustness through dynamic weighting and regime-aware adjustments.
Purpose
The RWM fulfills the need for a concise yet comprehensive tool to monitor recession risk. Unlike approaches relying on a single metric, such as yield-curve inversion, or extensive economic reports, it consolidates multiple data sources into a single probability output. The model identifies active indicators, their confidence levels, and the current economic regime, enabling users to anticipate downturns and adjust strategies accordingly.
Core Features
- Indicator Families : Incorporates 13 indicators across five categories: Yield, Labor, Sentiment, Production, and Financial Stress.
- Dynamic Weighting : Adjusts indicator weights based on recent predictive accuracy, constrained within user-defined boundaries.
- Leading and Coincident Split : Separates early-warning (leading) and confirmatory (coincident) signals, with adjustable weighting (default 60/40 mix).
- Economic Regime Sensitivity : Modulates output sensitivity based on market conditions (Expansion, Late-Cycle, Stress, Crisis), using a composite of VIX, yield-curve, financial conditions, and credit spreads.
- Display Options : Supports four modes—Probability (0-100%), Binary (four risk bins), Lead/Coincident, and Ensemble (blended probability).
- Confidence Intervals : Reflects model stability, widening during high volatility or conflicting signals.
- Alerts : Configurable thresholds (Watch, Caution, Warning, Alert) with persistence filters to minimize false signals.
- Data Export : Enables CSV output for probabilities, signals, and regimes, facilitating external analysis in Python or R.
Model Complexity Levels
Users can select from four tiers to balance simplicity and depth:
1. Essential : Focuses on three core indicators—yield-curve spread, jobless claims, and unemployment change—for minimalistic monitoring.
2. Standard : Expands to nine indicators, adding consumer confidence, PMI, VIX, S&P 500 trend, money supply vs. GDP, and the Sahm Rule.
3. Professional : Includes all 13 indicators, incorporating financial conditions, credit spreads, JOLTS vacancies, and wage growth.
4. Research : Unlocks all indicators plus experimental settings for advanced users.
Key Indicators
Below is a summary of the 13 indicators, their data sources, and economic significance:
- Yield-Curve Spread : Difference between 10-year and 3-month Treasury yields. Negative spreads signal banking sector stress.
- Jobless Claims : Four-week moving average of unemployment claims. Sustained increases indicate rising layoffs.
- Unemployment Change : Three-month change in unemployment rate. Sharp rises often precede recessions.
- Sahm Rule : Triggers when unemployment rises 0.5% above its 12-month low, a reliable recession indicator.
- Consumer Confidence : University of Michigan survey. Declines reflect household pessimism, impacting spending.
- PMI : Purchasing Managers’ Index. Values below 50 indicate manufacturing contraction.
- VIX : CBOE Volatility Index. Elevated levels suggest market anticipation of economic distress.
- S&P 500 Growth : Weekly moving average trend. Declines reduce wealth effects, curbing consumption.
- M2 + GDP Trend : Monitors money supply and real GDP. Simultaneous declines signal credit contraction.
- NFCI : Chicago Fed’s National Financial Conditions Index. Positive values indicate tighter conditions.
- Credit Spreads : Proxy for corporate bond spreads using 10-year vs. 2-year Treasury yields. Widening spreads reflect stress.
- JOLTS Vacancies : Job openings data. Significant drops precede hiring slowdowns.
- Wage Growth : Year-over-year change in average hourly earnings. Late-cycle spikes often signal economic overheating.
Data Processing
- Rate of Change (ROC) : Optionally applied to capture momentum in data series (default: 21-bar period).
- Z-Score Normalization : Standardizes indicators to a common scale (default: 252-bar lookback).
- Smoothing : Applies a short moving average to final signals (default: 5-bar period) to reduce noise.
- Binary Signals : Generated for each indicator (e.g., yield-curve inverted or PMI below 50) based on thresholds or Z-score deviations.
Probability Calculation
1. Each indicator’s binary signal is weighted according to user settings or dynamic performance.
2. Weights are normalized to sum to 100% across active indicators.
3. Leading and coincident signals are aggregated separately (if split mode is enabled) and combined using the specified mix.
4. The probability is adjusted by a regime multiplier, amplifying risk during Stress or Crisis regimes.
5. Optional smoothing ensures stable outputs.
Display and Visualization
- Probability Mode : Plots a continuous 0-100% recession probability with color gradients and confidence bands.
- Binary Mode : Categorizes risk into four levels (Minimal, Watch, Caution, Alert) for simplified dashboards.
- Lead/Coincident Mode : Displays leading and coincident probabilities separately to track signal divergence.
- Ensemble Mode : Averages traditional and split probabilities for a balanced view.
- Regime Background : Color-coded overlays (green for Expansion, orange for Late-Cycle, amber for Stress, red for Crisis).
- Analytics Table : Optional dashboard showing probability, confidence, regime, and top indicator statuses.
Practical Applications
- Asset Allocation : Adjust equity or bond exposures based on sustained probability increases.
- Risk Management : Hedge portfolios with VIX futures or options during regime shifts to Stress or Crisis.
- Sector Rotation : Shift toward defensive sectors when coincident signals rise above 50%.
- Trading Filters : Disable short-term strategies during high-risk regimes.
- Event Timing : Scale positions ahead of high-impact data releases when probability and VIX are elevated.
Configuration Guidelines
- Enable ROC and Z-score for consistent indicator comparison unless raw data is preferred.
- Use dynamic weighting with at least one economic cycle of data for optimal performance.
- Monitor stress composite scores above 80 alongside probabilities above 70 for critical risk signals.
- Adjust adaptation speed (default: 0.1) to 0.2 during Crisis regimes for faster indicator prioritization.
- Combine RWM with complementary tools (e.g., liquidity metrics) for intraday or short-term trading.
Limitations
- Macro indicators lag intraday market moves, making RWM better suited for strategic rather than tactical trading.
- Historical data availability may constrain dynamic weighting on shorter timeframes.
- Model accuracy depends on the quality and timeliness of economic data feeds.
Final Note
The Recession Warning Model provides a disciplined framework for monitoring economic downturn risks. By integrating diverse indicators with transparent weighting and regime-aware adjustments, it empowers users to make informed decisions in portfolio management, risk hedging, or macroeconomic research. Regular review of model outputs alongside market-specific tools ensures its effective application across varying market conditions.
Official USD Staggered Bands - ArgentinaOfficial USD Staggered Bands - Argentina
The Central Bank, under the administration of Javier Milei (La Libertad Avanza), announced on Friday, April 11, 2025, a series of measures to eliminate the so-called "exchange rate restriction."
In this new phase, the dollar's exchange rate on the Free Exchange Market (MLC) will be able to fluctuate within a band between $1,000 and $1,400 , the limits of which will be expanded at a rate of 1% monthly.
The lines evolve daily, increasing as the public administration predicts. This way, you can know the likelihood of a Central Bank intervention to correct the variation and return the peso to a price within the band.
The script runs under the ticker USDARS

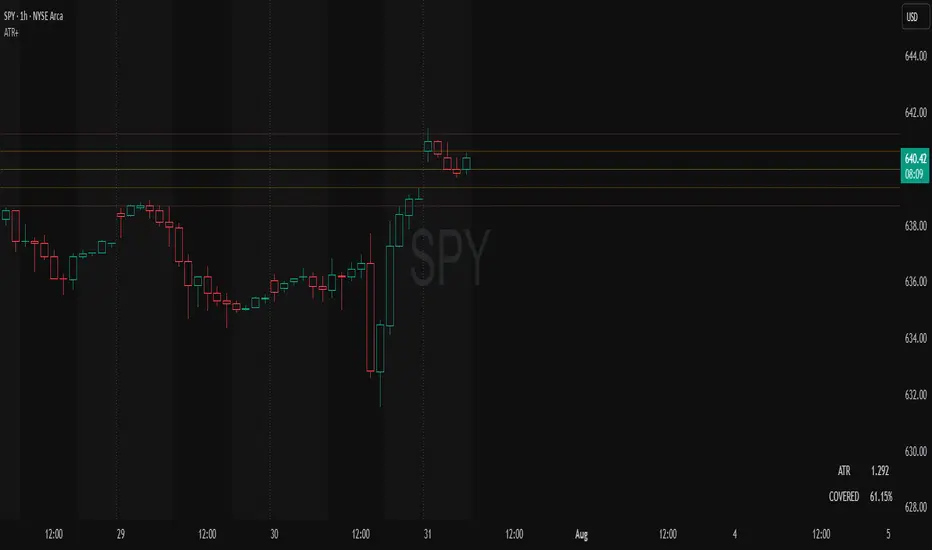
ATR Plots + OverlayATR Plots + Overlay
This tool calculates and displays Average True Range (ATR)-based levels on your chart for any selected timeframe, giving traders a quick visual reference for expected price movement relative to the most recent bar’s open price. It plots guide levels above and below that open and shows how much of the typical ATR-based range has already been covered—all in one interactive table and on-chart overlay.
What It Does
ATR Calculation:
Uses true range data over a user-defined period (default 14), smoothed via RMA, SMA, EMA, or WMA, on the selected timeframe (e.g., 1h, 4h, daily) to calculate the ATR value.
Projected Levels:
Plots four reference levels relative to the open price of the most recent bar on the chosen timeframe:
+100% ATR: Open + ATR
+50% ATR: Open + 50% of ATR
−50% ATR: Open − 50% of ATR
−100% ATR: Open − ATR
Coverage %:
Tracks high and low prices for the current session on the selected timeframe and calculates what percentage of the ATR has already been covered:
Coverage % = (High − Low) ÷ ATR × 100
Interactive Table:
Shows the ATR value and current coverage percentage in a customizable table overlay. Position, color scheme, borders, transparency, and an optional empty top row are all adjustable via settings.
Customization Options
Table Settings:
Position the table (top/bottom × left/right).
Customize background color, text color, border color, and thickness.
Optionally add an empty top row for spacing.
Line Settings:
Choose color, line style (solid/dotted/dashed), and width.
Lines automatically update with each new bar on the selected timeframe, anchored to that bar’s open price.
General Inputs:
ATR length (number of bars).
Smoothing method (RMA, SMA, EMA, WMA).
Timeframe selection for ATR calculations (e.g., 15m, 1h, Daily).
How to Use It for Trading
Measure Volatility: Quickly gauge the expected price movement based on ATR for any timeframe.
Identify Overextension: Use the coverage % to see how much of the expected ATR range is already consumed.
Plan Entries & Exits: Align trade targets and stops with ATR levels for more objective planning.
Visual Reference: Horizontal guide lines and table update automatically as new bars form, keeping information clear and actionable.
Ideal For
Intraday traders using ATR levels to frame trades.
Swing traders wanting ATR-based reference points for larger timeframes.
Anyone seeking a volatility-based framework for planning stops, targets, or identifying overextended conditions.