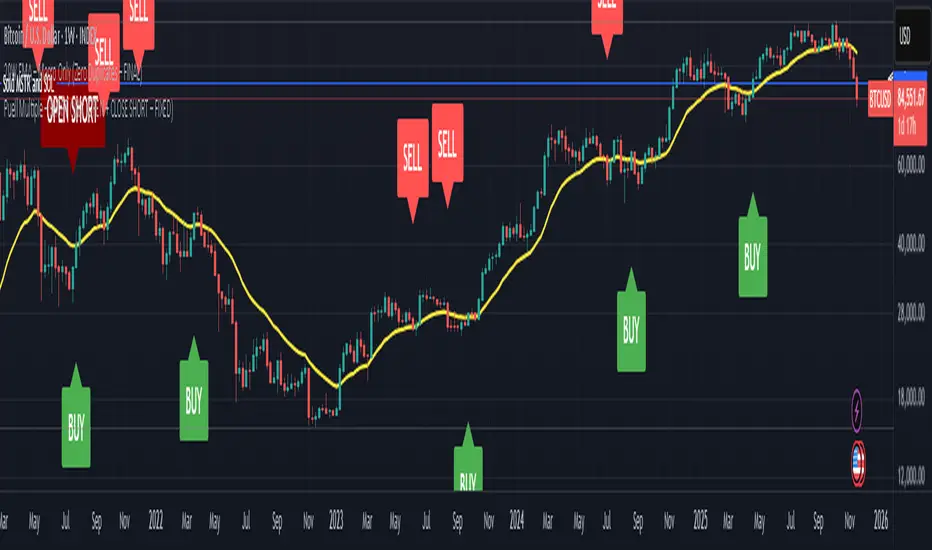
BTC Halving Cycle SignalsBTC Halving Cycle Signals
What signals does this script give in real history (2011-2025):
2015 → BUY (bear market bottom)
2019 → BUY (post-2018 bottom)
October 2020 → BUY
November 2023 → BUY
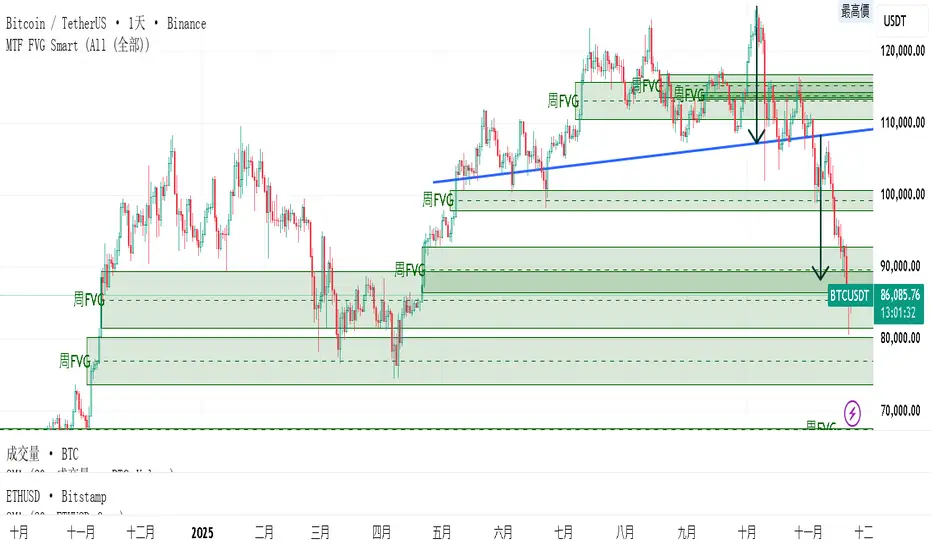
And right now (Nov 2025) → green bottom + price above weekly EMA200 → about to give a buy signal if it breaks $72k strongly.
BUY signal: ~500 days pre-halving + price > weekly EMA200 + monthly RSI <60 (accumulation).
SELL signal: ~1064 days post-halving + RSI >75 or close < SuperTrend (distribution).
Hardcoded halving dates (can be edited). Works on BTCUSD weekly/monthly, gives 1-2 signals per cycle.
Indicador Pine Script®