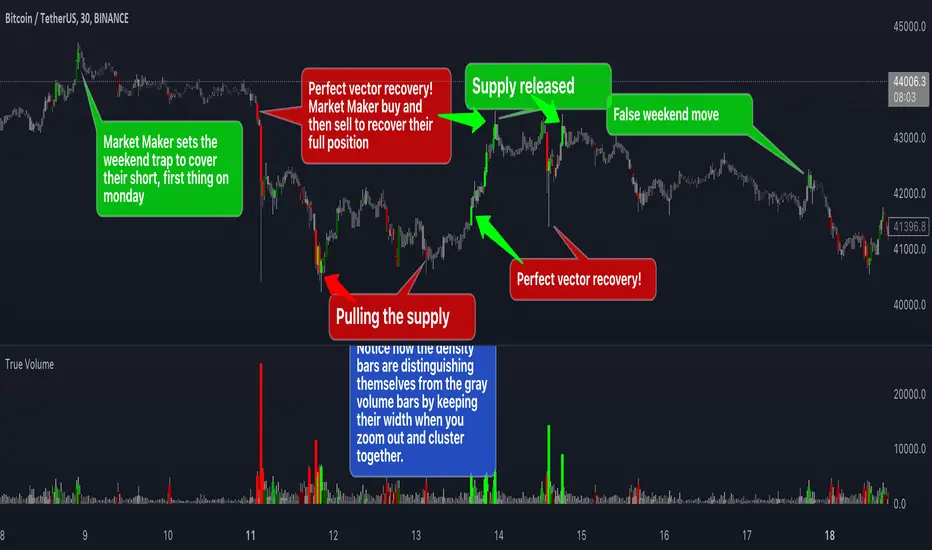
True VolumeThis indicator is designed to provide in-depth analysis of volume data from multiple sources and distinguish highly liquid candles by measuring the density of the volume. By focusing on the density and concentration of volume, rather than just the volume itself, it offers a more nuanced view of the market. This can be particularly beneficial in markets like cryptocurrencies, where understanding the role of market makers versus retail traders is crucial for strategic trading.
This is how it works:
Multiple Asset Integration:
Unlike standard volume indicators, True Volume allows the inclusion of up to four different assets (or the same asset from various exchanges) into its volume calculations. This feature provides a broader and more accurate total volume representation, essential in markets like cryptocurrencies where volume is dispersed across multiple exchanges.
Adjustable Time Anchors:
It offers various time anchor options, allowing traders to analyze volume data over different time periods or a specific amount of lookback candles. This flexibility helps in understanding volume trends over both short and long-term time frames.
Volume Density Analysis:
The core of this indicator is the innovative concept of Volume Density. It's calculated using a sigmoid function that normalizes the volume-to-price movement ratio in a unique way without needing a max cap or having the density column spike off the chart. This method helps in distinguishing between normal volume fluctuations and those that are unusually dense for the given price movement. This distinction is key in identifying potential market maker activities.
The Visuals:
The Volume Density is displayed in a unique way without compromising the original volume bars or cap the density. Infinite density can essentially be represented without having an infinitely large bar or caping out the density data. There's also two different color themes, optional bar color, and an option to flip the density bars up-side down for a different representation. Each of the original volume sources can be displayed separately as well. All colors as customizable as well for your own preference.
Price Volume Trend (PVT):
Included in this indicator is also the Price Volume Trend, which cumulatively measures the density delta, offering insights into the longer-term momentum of the market.
How do I trade it?
This indicator aims to give you insight into 'the other side of the trade', the Market Makers. When you buy, they provide liquidity by selling to you. That drives the Volume Density up.
Consider whether the market maker is currently long or short and might need to cover their position by wicking price back, or "adjust inventory". Especially towards the end of a market session.
Consider dense candles during market gaps or weekends to be market manipulation moves.
The density also goes up when stop losses are hit. If price makes a higher high or lower low, high density could indicate a liquidation event.
Density
KERPD Noise Filter - Kaufman Efficiency Ratio and Price DensityThis indicator combines Kaufman Efficiency Ratio (KER) and Price Density theories to create a unique market noise filter that is 'right on time' compared to using KER or Price Density alone. All data is normalized and merged into a single output. Additionally, this indicator provides the ability to consider background noise and background noise buoyancy to allow dynamic observation of noise level and asset specific calibration of the indicator (if desired).
The basic theory surrounding usage is that: higher values = lower noise, while lower values = higher noise in market.
Notes: NON-DIRECTIONAL Kaufman Efficiency Ratio used. Threshold period of 30 to 40 applies to Kaufman Efficiency Ratio systems if standard length of 20 is applied; maintained despite incorporation of Price Density normalized data.
TRADING USES:
-Trend strategies, mean reversion/reversal/contrarian strategies, and identification/avoidance of ranging market conditions.
-Trend strategy where KERPD is above a certain value; generally a trend is forming/continuing as noise levels fall in the market.
-Mean reversion/reversal/contrarian strategies when KERPD exits a trending condition and falls below a certain value (additional signal confluence confirming for a strong reversal in price required); generally a reversal is forming as noise levels increase in the market.
-A filter to screen out ranging/choppy conditions where breakouts are frequently fake-outs and or price fails to move significantly; noise level is high, in addition to the background buoyancy level.
-In an adaptive trading systems to assist in determining whether to apply a trend following algorithm or a mean reversion algorithm.
THEORY / THOUGHT SPACE:
The market is a jungle. When apex predators are present it often goes quiet (institutions moving price), when absent the jungle is loud.
There is always background noise that scales with the anticipation of the silence, which has features of buoyancy that act to calibrate the beginning of the silence and return to background noise conditions.
Trend traders hunt in low noise conditions. Reversion traders hunt in the onset of low noise into static conditions. Ranges can be avoided during high noise and buoyant background noise conditions.
Distance between the noise line and background noise can help inform decision making.
CALIBRATION:
- Set the Noise Threshold % color change line so that the color cut off is where your trend/reversion should begin.
- Set the Background Noise Buoyancy Calibration Decimal % to match the beginning/end of the color change Noise Threshold % line. Match the Background Noise Baseline Decimal %' to the number set for buoyancy.
- Additionally, create your own custom settings; 33/34 and 50 length also provides interesting results.
- A color change tape option can be enabled by un-commenting the lines at the bottom of this script.
Market Usage:
Stock, Crypto, Forex, and Others
Excellent for: NDQ, J225, US30, SPX
Market Conditions:
Trend, Reversal, Ranging

MathProbabilityDistributionLibrary "MathProbabilityDistribution"
Probability Distribution Functions.
name(idx) Indexed names helper function.
Parameters:
idx : int, position in the range (0, 6).
Returns: string, distribution name.
usage:
.name(1)
Notes:
(0) => 'StdNormal'
(1) => 'Normal'
(2) => 'Skew Normal'
(3) => 'Student T'
(4) => 'Skew Student T'
(5) => 'GED'
(6) => 'Skew GED'
zscore(position, mean, deviation) Z-score helper function for x calculation.
Parameters:
position : float, position.
mean : float, mean.
deviation : float, standard deviation.
Returns: float, z-score.
usage:
.zscore(1.5, 2.0, 1.0)
std_normal(position) Standard Normal Distribution.
Parameters:
position : float, position.
Returns: float, probability density.
usage:
.std_normal(0.6)
normal(position, mean, scale) Normal Distribution.
Parameters:
position : float, position in the distribution.
mean : float, mean of the distribution, default=0.0 for standard distribution.
scale : float, scale of the distribution, default=1.0 for standard distribution.
Returns: float, probability density.
usage:
.normal(0.6)
skew_normal(position, skew, mean, scale) Skew Normal Distribution.
Parameters:
position : float, position in the distribution.
skew : float, skewness of the distribution.
mean : float, mean of the distribution, default=0.0 for standard distribution.
scale : float, scale of the distribution, default=1.0 for standard distribution.
Returns: float, probability density.
usage:
.skew_normal(0.8, -2.0)
ged(position, shape, mean, scale) Generalized Error Distribution.
Parameters:
position : float, position.
shape : float, shape.
mean : float, mean, default=0.0 for standard distribution.
scale : float, scale, default=1.0 for standard distribution.
Returns: float, probability.
usage:
.ged(0.8, -2.0)
skew_ged(position, shape, skew, mean, scale) Skew Generalized Error Distribution.
Parameters:
position : float, position.
shape : float, shape.
skew : float, skew.
mean : float, mean, default=0.0 for standard distribution.
scale : float, scale, default=1.0 for standard distribution.
Returns: float, probability.
usage:
.skew_ged(0.8, 2.0, 1.0)
student_t(position, shape, mean, scale) Student-T Distribution.
Parameters:
position : float, position.
shape : float, shape.
mean : float, mean, default=0.0 for standard distribution.
scale : float, scale, default=1.0 for standard distribution.
Returns: float, probability.
usage:
.student_t(0.8, 2.0, 1.0)
skew_student_t(position, shape, skew, mean, scale) Skew Student-T Distribution.
Parameters:
position : float, position.
shape : float, shape.
skew : float, skew.
mean : float, mean, default=0.0 for standard distribution.
scale : float, scale, default=1.0 for standard distribution.
Returns: float, probability.
usage:
.skew_student_t(0.8, 2.0, 1.0)
select(distribution, position, mean, scale, shape, skew, log) Conditional Distribution.
Parameters:
distribution : string, distribution name.
position : float, position.
mean : float, mean, default=0.0 for standard distribution.
scale : float, scale, default=1.0 for standard distribution.
shape : float, shape.
skew : float, skew.
log : bool, if true apply log() to the result.
Returns: float, probability.
usage:
.select('StdNormal', __CYCLE4F__, log=true)
Probability Distribution HistogramProbability Distribution Histogram
During data exploration it is often useful to plot the distribution of the data one is exploring. This indicator plots the distribution of data between different bins.
Essentially, what we do is we look at the min and max of the entire data set to determine its range. When we have the range of the data, we decide how many bins we want to divide this range into, so that the more bins we get, the smaller the range (a.k.a. width) for each bin becomes. We then place each data point in its corresponding bin, to see how many of the data points end up in each bin. For instance, if we have a data set where the smallest number is 5 and the biggest number is 105, we get a range of 100. If we then decide on 20 bins, each bin will have a width of 5. So the left-most bin would therefore correspond to values between 5 and 10, and the bin to the right would correspond to values between 10 and 15, and so on.
Once we have distributed all the data points into their corresponding bins, we compare the count in each bin to the total number of data points, to get a percentage of the total for each bin. So if we have 100 data points, and the left-most bin has 2 data points in it, that would equal 2%. This is also known as probability mass (or well, an approximation of it at least, since we're dealing with a bin, and not an exact number).
Usage
This is not an indicator that will give you any trading signals. This indicator is made to help you examine data. It can take any input you give it and plot how that data is distributed.
The indicator can transform the data in a few ways to help you get the most out of your data exploration. For instance, it is usually more accurate to use logarithmic data than raw data, so there is an option to transform the data using the natural logarithmic function. There is also an option to transform the data into %-Change form or by using data differencing.
Another option that the indicator has is the ability to trim data from the data set before plotting the distribution. This can help if you know there are outliers that are made up of corrupted data or data that is not relevant to your research.
I also included the option to plot the normal distribution as well, for comparison. This can be useful when the data is made up of residuals from a prediction model, to see if the residuals seem to be normally distributed or not.

test - delta distributiona test case for the KDE function on price delta.
the KDE function can be used to quickly check or confirm edge cases of the trading systems conditionals.

Volume DensitySince we don't have tick count per time interval, let's do it this way. Basically "bigger the move bigger the volume" rule applies in most times, making volume alone kinda useless. What is more interesting, is when there was a huge volume within a relatively small range, or vice versa, a huge move without equally increased volume.
Without diving into details, bars with low volatility and serious volume are aprox. areas of possible future reversals/pullbacks, while volumeless high volatility moves should not cause any serious stops in price action.
This is just a small easy script to highlight this process. "Mathematically speaking, it's just a reciprocal of quotient of awfewefaffwqg..... Nah, not this time.
HOW IT WORKS:
Volume Density = 1/(range/volume)
We take range of a bar (high minus low), divide it by volume of the same bar, in order to neutralize this "bigger-bigger" relationship. Then we memorize this number, take 1 and divide 1 by this number, in order to inverse the result. So now, small bars with big volume will be rated higher than just by using classic volume histogram.
I suppose it would be easy to use it along with classic volume histogram, and assess the differences between these 2 histograms.
///
Probs some1 has already posted smth like this before idk, but if it aint the case, here it is, for you.
